macOS 초보를 위한 터미널 사용 가이드 - Week 04
grep과 그 대안들
- 이전 문서: [[/mac/terminal-guide/03]]
- 다음 문서: [[/mac/terminal-guide/05]]
grep 명령?
[[/cmd/grep]]은 1970년대 초부터 여태까지 수많은 사람들에 의해 사용되고 발전을 거듭해 온 유서깊은 프로그램입니다. [[/cmd/grep]]을 처음 개발한 사람은 Ken Thompson입니다.
[[/people/brian-w-kernighan]]에 의하면 grep이라는 이름은 ed의 g/re/p 명령에서 왔다고 합니다.
(ed도 Ken Thompson이 개발한 프로그램입니다.)
이 가이드의 대상 플랫폼인 macOS에서는 오래된 버전의 BSD 유닉스에 들어있던 [[/cmd/grep]]이 설치되어 있습니다. 그래서 GNU [[/cmd/grep]]과는 몇 가지 옵션이나 기능, 성능 등에 차이가 있습니다.
[[/cmd/grep]]을 잘 쓰려면 GNU [[/cmd/grep]]과 BSD [[/cmd/grep]] 사이에서 서로 호환되는 옵션이 무엇인지를 알면 좋습니다. 그리고 3 종류의 정규식 문법([[/regex/bre]]{BRE}, ERE, [[/regex/pcre]]{PCRE}) 중 필수적으로 ERE, 좀 더 욕심내서 PCRE를 다룰 수 있으면 좋습니다.
grep 기본 사용법
GNU [[/cmd/grep]]에 대해서는 좀 미뤄두고 일단은 macOS에 기본으로 설치되어 있는 BSD [[/cmd/grep]]에 대해서만 기본적인 사용법을 익혀 봅시다.
먼저 grep --version으로 버전을 확인해 봅시다. 제 컴퓨터에서는 다음과 같이 나오네요.
$ grep --version
grep (BSD grep, GNU compatible) 2.6.0-FreeBSD
[[/cmd/grep]]의 기본 문법은 다음과 같습니다.
grep 옵션 검색패턴 파일이름1 파일이름2 파일이름3 ...
오른쪽에 파일 이름이 '수평 리스트'로 줄줄이 이어지는 것을 보고 [[/mac/terminal-guide/03#xargs]]{지난 주에 공부한} [[/cmd/xargs]]를 떠올릴 수 있다면 점점 터미널 사용에 익숙해지고 있다는 뜻입니다.
물론 떠올리지 못했어도 괜찮습니다.
UNIX 셸 명령들은 이렇게 마지막에 여러 파일의 이름을 나열하는 방식으로 돌아가는 것들이 많습니다. 그래서 자꾸 쓰다 보면 리스트가 뒤에 오는 방식에 익숙해집니다.
/usr/share/dict/words 파일은 컴퓨터에 기본적으로 내장되어 있는 영어사전입니다.
$ wc -l /usr/share/dict/words
235976 /usr/share/dict/words
단어가 235,976개나 들어있네요. 이 파일을 대상으로 [[/cmd/grep]] 사용을 연습해 봅시다.
영어사전 파일에서 study 단어를 찾아보겠습니다.
$ grep study /usr/share/dict/words
afterstudy
forestudy
outstudy
overstudy
prestudy
restudy
study
understudy
words파일에서study단어를 포함하는 모든 라인을 찾아서 출력해라
여러 파일을 지정할 수 있었다는 것을 기억하고 계실 것입니다.
그러니 이번에는 2개의 파일을 지정해서 study 단어를 찾아보겠습니다.
$ grep study /usr/share/dict/words /usr/share/dict/web2
/usr/share/dict/words:afterstudy
/usr/share/dict/words:forestudy
/usr/share/dict/words:outstudy
/usr/share/dict/words:overstudy
/usr/share/dict/words:prestudy
/usr/share/dict/words:restudy
/usr/share/dict/words:study
/usr/share/dict/words:understudy
/usr/share/dict/web2:afterstudy
/usr/share/dict/web2:forestudy
/usr/share/dict/web2:outstudy
/usr/share/dict/web2:overstudy
/usr/share/dict/web2:prestudy
/usr/share/dict/web2:restudy
/usr/share/dict/web2:study
/usr/share/dict/web2:understudy
words와web2파일에서study단어를 포함하는 모든 라인을 찾아서 출력해라
파일이 두 개가 되니 검색 결과에서 어떤 파일에서 찾았는지도 함께 표시되는 것을 볼 수 있습니다. 다음과 같은 형식입니다.
찾은파일이름:찾은단어
물론 [[/cmd/grep]]이 표준입력(0)으로 들어오는 텍스트를 읽어서 처리하게 하고 싶다면 단순하게 파이프 |를 사용하면 됩니다.
$ seq 30 | grep 4
4
14
24
seq 30: 1부터 30까지를 출력grep 4: 4가 포함되어 있는 줄만 출력
-o 옵션
-o 옵션을 주면 매치된 문자열만 출력해 줍니다.
$ seq 3000 | grep 444
444
1444
2444
$ seq 3000 | grep 444 -o
444
444
444
-o 옵션이 없을 때에는 1부터 3000까지의 숫자 중에서 444와 매치된 '줄'을 출력했습니다.
그러나 -o 옵션을 주면 444와 매치된 '문자열'만을 출력합니다.
-v 옵션
-v 옵션을 주면 매치되지 않은 줄만 출력합니다.
seq 100 | grep -v 2
seq 100: 1부터 100까지를 출력grep -v 2: 2가 포함되지 않은 줄만 출력
명령을 실행해보면 출력 결과가 꽤 많을 겁니다. 모아서 보기 쉽게 [[/cmd/xargs]]를 써서 10개씩 한 줄로 모아서 출력해 봅시다.
$ seq 100 | grep -v 2 | xargs -n 10
1 3 4 5 6 7 8 9 10 11
13 14 15 16 17 18 19 30 31 33
34 35 36 37 38 39 40 41 43 44
45 46 47 48 49 50 51 53 54 55
56 57 58 59 60 61 63 64 65 66
67 68 69 70 71 73 74 75 76 77
78 79 80 81 83 84 85 86 87 88
89 90 91 93 94 95 96 97 98 99
100
seq 100: 1부터 100까지를 출력grep -v 2: 2가 포함되지 않은 줄만 출력xargs -n 10: 10개씩 한 줄로 모아서 출력
1 ~ 100 중에서 2가 포함된 것들만 빼고 모두 출력된 것 같습니다.
[[/cmd/grep]]을 한 번 더 써서 이 결과를 확인할 수 있을 겁니다.
$ seq 100 | grep -v 2 | grep 2 | wc -l
0
seq 100: 1부터 100까지를 출력grep -v 2: 2가 포함되지 않은 줄만 출력grep 2: 2가 포함된 줄만 출력wc -l: 줄 수를 세어서 출력
사실 grep -v 2와 grep 2는 서로 논리적으로 정반대의 결과를 출력하기 때문에 이 결과는 당연한 것이기도 합니다.
–color 옵션
--color 옵션을 주면 매치된 부분에 색을 입혀서 출력해 줍니다.
$ seq 50 | grep 6 --color
6
16
26
36
46
alias 지정하기
[[/cmd/grep]] 명령을 입력할 때마다 매번
--color옵션을 주기는 귀찮습니다. 그러니 그냥grep을 실행해도--color옵션이 적용되도록alias를 설정해 두면 편리합니다.alias grep='grep --color=auto'이렇게 한번 입력해두면 해당 터미널을 종료할 때까지는
grep을 실행할 때마다grep --color=auto가 실행되는 것과 똑같이 작동합니다.다음 터미널 세션에서도 사용하고 싶다면
~/.bash_profile이나~/.bashrc또는~/.zshrc에 해당alias를 설정해 두면 됩니다.
-R 옵션
만약 하위의 모든 디렉토리에 대해 검색을 하고 싶다면 -R 옵션을 사용하면 됩니다.
grep -R 'Thompson' ~/johngrib.github.io
~/johngrib.github.io디렉토리부터 하위의 모든 디렉토리에 대해 'Thompson'을 검색
만약 검색을 연습할만한 파일들이 충분하지 않다면 다음 명령으로 이 웹사이트의 소스를 받아서
grep을 연습해보세요.git clone git@github.com:johngrib/johngrib.github.io.git
한편 -R은 파일이나 경로를 지정하지 않아도 알아서 현재 경로를 기준으로 탐색을 시작합니다.
그래서 다음과 같이 해도 됩니다.
cd ~/johngrib.github.io
grep -R 'Thompson'
- 현재 경로 하위의 모든 디렉토리에 대해 'Thompson'을 검색
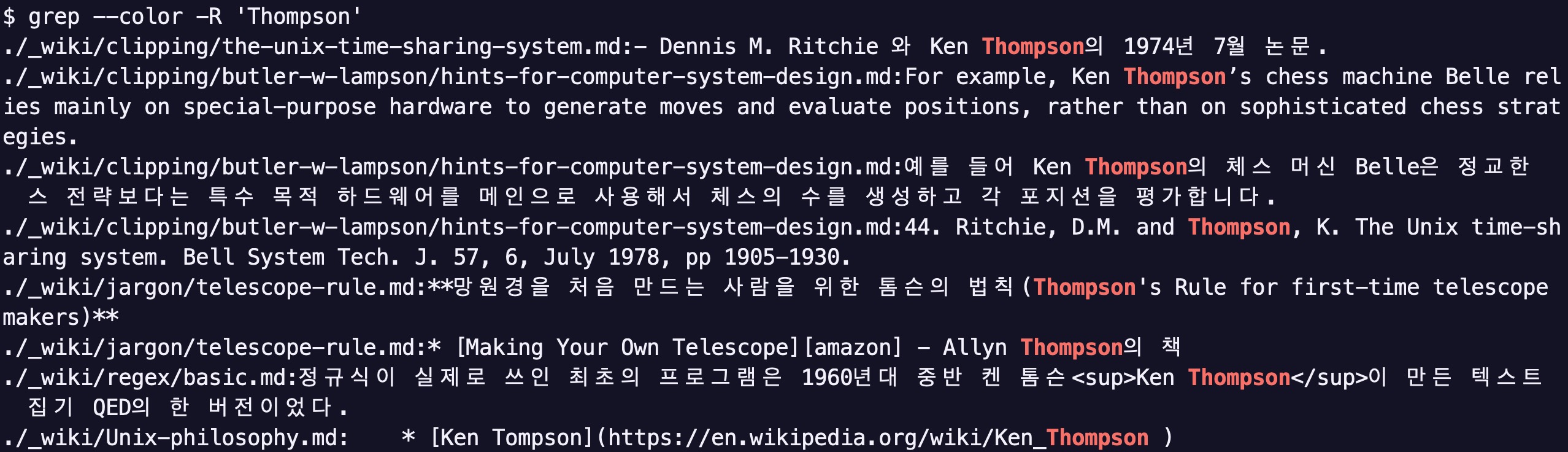
지금까지의 [[/cmd/grep]] 실행 결과는 검색된 라인이 출력되는 방식이었습니다.
그런데 -R 옵션을 사용하면 위의 스크린샷과 같이 파일명:검색결과 형식으로 출력됩니다.
하지만 긴 파일을 대상으로 검색을 할 때에는 파일명만으로는 검색 결과를 활용하기 어렵습니다.
그래서 -R을 사용할 때에는 줄 번호를 출력해주는 -n 옵션을 함께 사용하는 경우가 많습니다.
-n 옵션
-n 옵션을 주면 검색된 라인의 줄 번호를 함께 출력합니다.
$ printf "가위\n바위\n보\n" | grep -n 바
2:바위
$ printf "가위\n바위\n보\n" | grep -n 위
1:가위
2:바위
-R 옵션과 함께 사용하면 파일명:줄번호:검색결과 형식으로 출력되기 때문에 검색 결과를 보고, 파일을 열어서 해당 위치로 찾아가기가 쉽습니다.
grep --color -n -R 'Thompson' ~/johngrib.github.io
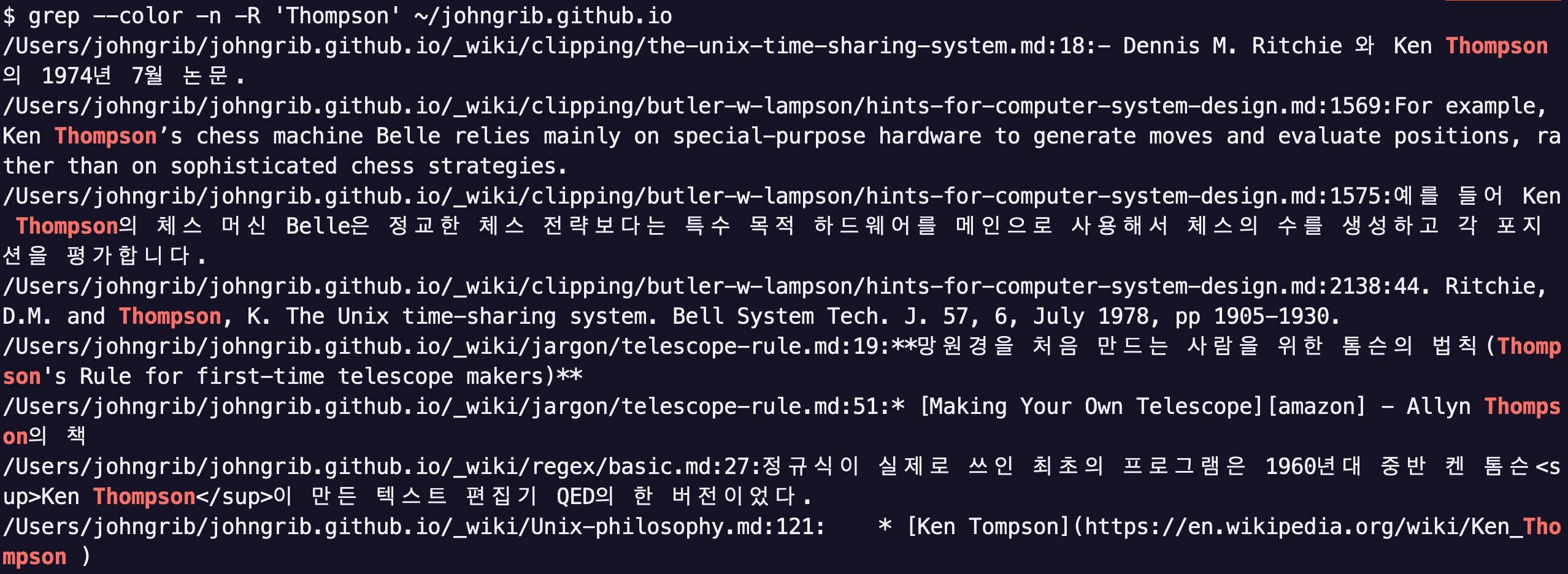
첫째줄을 보면 ... /clipping/the-unix-time-sharing-system.md:18:- Dennis ... 라고 되어 있는 것을 알 수 있습니다.
여기에서 파일 이름뒤에 이어지는 :18이 바로 해당 파일의 18번 라인이라는 뜻입니다.
내용이 좀 난잡하니까 파일이름과 줄번호만 출력해봅시다.
$ grep -n -R 'Thompson' ~/johngrib.github.io | head | cut -d: -f1 -f2
/Users/johngrib/johngrib.github.io/_wiki/clipping/the-unix-time-sharing-system.md:18
/Users/johngrib/johngrib.github.io/_wiki/clipping/butler-w-lampson/hints-for-computer-system-design.md:1569
/Users/johngrib/johngrib.github.io/_wiki/clipping/butler-w-lampson/hints-for-computer-system-design.md:1575
/Users/johngrib/johngrib.github.io/_wiki/clipping/butler-w-lampson/hints-for-computer-system-design.md:2138
/Users/johngrib/johngrib.github.io/_wiki/jargon/telescope-rule.md:19
/Users/johngrib/johngrib.github.io/_wiki/jargon/telescope-rule.md:51
/Users/johngrib/johngrib.github.io/_wiki/regex/basic.md:27
/Users/johngrib/johngrib.github.io/_wiki/Unix-philosophy.md:121
/Users/johngrib/johngrib.github.io/_wiki/mac/terminal-guide/04.md:23
/Users/johngrib/johngrib.github.io/_wiki/mac/terminal-guide/04.md:26
grep -n: 출력 결과에 줄 번호를 추가한다.grep -R ~/johngrib.github.io:~/johngrib.github.io의 하위 디렉토리까지 모두 탐색한다.| head:grep의 검색 결과 중에서 처음 10줄만 출력한다.| cut -d: -f1 -f2::를 구분자로 사용해서 첫번째와 두번째 필드만 출력한다.
이와 같은 파일명:줄번호 형식은 파일의 특정한 위치를 표시할 필요가 있는 경우에 UNIX 계열 명령어들이 공통으로 사용하는 형식이므로 기억해두면 좋습니다.
(아직은 좀 어려울 수 있는) 팁
터미널에서 작동하는 것을 기본으로 두는 [[/vim]] 에디터에서도
파일명:줄번호형식을 중요하게 사용하고 있습니다. 그래서파일명:줄번호형식의 문자열 위에 커서를 두고gF를 입력하면 바로 해당 파일의 해당 라인으로 이동할 수 있습니다.그래서 다음과 같은 활용이 가능해집니다.
grep -n -R 'Thompson' \ ~/johngrib.github.io/_wiki > grep-result \ && vim grep-result
grep -n -R 'Thompson' 경로 > grep-result: 지정한 경로의 모든 하위 디렉토리에서 'Thompson'을 검색해서 검색 결과를grep-result파일에 저장한다.&&- 이전 명령이 성공하면 다음 명령을 실행한다.vim grep-result:grep-result파일을 vim으로 열어서 검색 결과를 확인한다.이렇게 vim에서 검색결과 파일을 열게 되면 스크롤을 하면서 검색결과를 보고
gF를 사용해 각 파일의 해당 라인들로 바로 이동할 수 있습니다. (gf는 파일을 열어주기만 하고,gF는 파일을 연 다음 해당 라인으로 바로 이동해줍니다.)물론 파일을 생성하는 것이 귀찮다면 [[/cmd/grep]]의 표준출력(
1)을 바로 [[/vim]]으로 넘겨주는 방법도 있습니다.grep --color -n -R 'Thompson' ~/johngrib.github.io | vim -
find 명령과의 조합
[[/cmd/grep]]은 수많은 다른 명령들과 조합해서 사용할 수 있습니다.
이번에는 앞에서 공부했던 [[/cmd/find]]와 조합해서 사용해 봅시다.
-exec 옵션을 사용하면 찾아낸 파일들에 대해 일일이 실행할 수 있겠죠.
find ~/johngrib.github.io -name '*.md' -exec grep 'Thompson' {} \;
find ~/johngrib.github.io: johngrib.github.io 디렉토리부터 시작해서 하위 디렉토리까지 모두 탐색-name '*.md': 확장자가.md인 파일만 탐색-exec grep 'Thompson' {} \;: 찾은 파일들에 대해 'Thompson'을 검색
좀 더 빠르게 실행하고 싶다면 역시 [[/mac/terminal-guide/03#xargs-find]]{이전에 공부했던 xargs를 사용하면} 되겠죠.
find ~/johngrib.github.io -name '*.md' | xargs grep 'Thompson'
-B 와 -A 옵션
-B(before)와 -A(after) 옵션을 사용하면 찾은 라인의 앞/뒤로 몇 줄을 더 출력할 수 있습니다.
예를 들어 -B3은 찾은 곳의 아래로 3줄을 더 보여주고, -A2는 찾은 곳의 위로 2줄을 더 보여줍니다.
grep -A3 -B2 -R Architectural

위 아래로 몇 줄을 더 보여주므로 각 검색결과 경계를 구분해주기 위해 -- 두 글자만 있는 라인이 중간중간에 추가되어 있습니다.
여기에 -n 옵션을 추가하면 줄번호도 같이 표시되므로 정말로 아래로 3줄, 위로 2줄을 더 보여주는지 확인할 수 있습니다.
grep -A3 -B2 -n -R Architectural
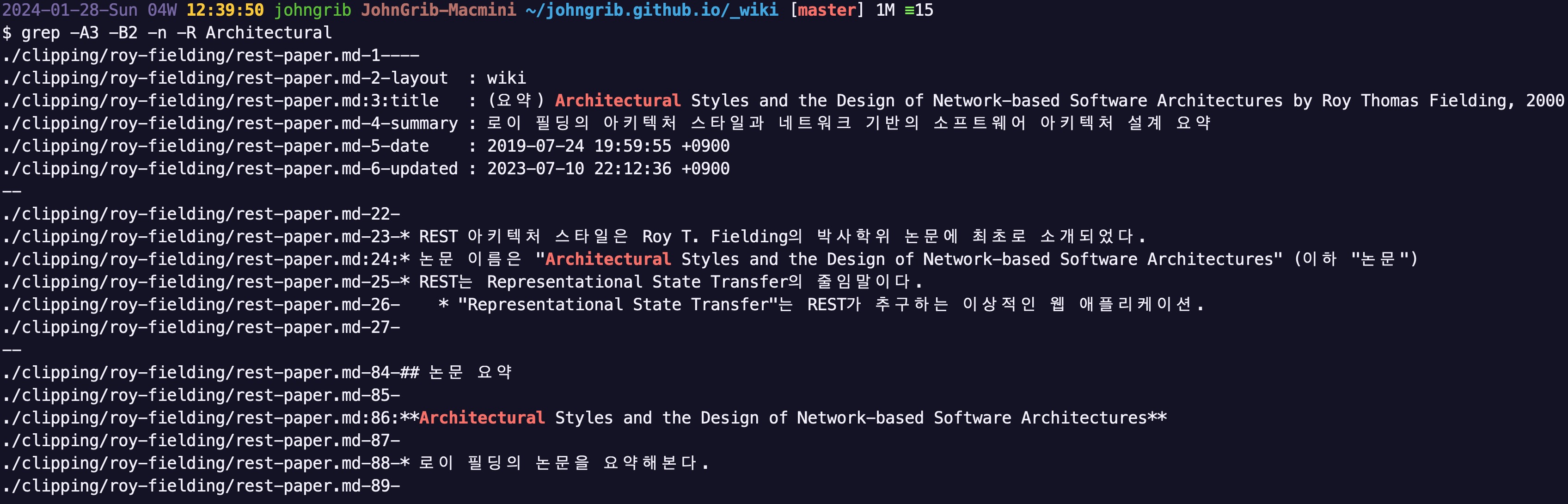
보통 프로그래밍 프로젝트에서 함수 이름 등으로 검색할 때에는 -B5 정도로 위로 5줄을 더 보여주는 것이 편리합니다.
그렇게 하면 그 함수 시그니처 위의 주석도 같이 볼 수 있는 결과가 나오기 때문입니다.
grep에서 더 나아가기
GNU grep 설치하고 사용하기
앞에서 언급한 바와 같이 [[/cmd/grep]]은 역사가 오래된 프로그램입니다. 게다가 하필 macOS는 오래된 버전의 BSD grep을 제공하고 있기 때문에 GNU grep에 비해 몇 가지 짜증나는 점들이 있습니다.
- GNU grep이 macOS에 설치된 오래된 버전의 BSD grep보다 거의 모든 점이 뛰어납니다.
- macOS의 grep은 PCRE(Perl Compatible Regular Expression)을 지원하지 않습니다.
- GNU grep이 macOS에 설치된 grep보다 훨씬 빠릅니다.
이번에는 GNU grep을 설치해 봅시다. 다음 명령을 실행하면 됩니다.
brew install grep
그런데 설치가 끝난다고 해서 곧바로 GNU grep을 사용할 수 있는 것은 아닙니다.
macOS에 이미 기본으로 설치된 grep과 충돌을 피하기 위해 GNU grep을 ggrep라는 이름으로 설치하기 때문입니다.
따라서 GNU grep을 사용하려면 ggrep이라는 이름으로 실행하거나 아니면 grep을 ggrep으로 aliasing해야 합니다.
이 가이드에서는 alias를 사용하지 않고 그냥 ggrep이라는 이름을 사용할 것입니다.
그러니 이제부터 ggrep 명령을 사용하면 GNU grep을 실행하는 것이라고 생각하시면 됩니다.
설치가 끝났으니 이제 간단하게 macOS에 설치된 grep과 GNU grep의 속도를 비교해 봅시다.
$ find . -type f | wc -l
13059
파일이 13,059 개 있는 디렉토리가 테스트 대상입니다
$ time grep -R test >/dev/null 2>&1
real 0m13.522s
user 0m12.033s
sys 0m0.458s
$ time ggrep -R test >/dev/null 2>&1
real 0m0.584s
user 0m0.294s
sys 0m0.267s
13,059개의 파일을 대상으로 test라는 단어를 검색하는데, macOS에 설치된 grep은 13.522초가 걸렸습니다.
그런데GNU grep은 0.584초 밖에 걸리지 않았습니다.
검색 대상 파일의 수가 많으면 많을수록 이 차이는 더욱 커질 것입니다.
인생은 짧으니까 GNU grep을 사용하는 것이 더 나은 결정일 수 있습니다.
BRE, ERE, PCRE
IEEE POSIX 표준에서는 정규식을 다음과 같이 구분합니다.1
- SRE(Simple Regular Expression)
- BRE(Basic Regular Expression)
- ERE(Extended Regular Expression)
이들 중 SRE는 deprecated 되었고 BRE는 여러모로 불편하기 때문에, 아주 단순한 패턴이 아니라면 실제로 [[/cmd/grep]]을 사용할 때에는 주로 ERE를 쓰게 됩니다.
BRE의 이름을 보면 "Basic"인데 왜 불편하다는 걸까 하는 생각을 할 수 있습니다.
그런데 BRE는 괄호나 수량자 등등에 \를 붙여 이스케이핑해줘야 하기 때문에 조금이라도 덜 단순한 정규 표현식을 쓰려 한다면 무지 귀찮습니다.
| BRE | \? |
\+ |
\{ |
\} |
\( |
\) |
\| |
| ERE | ? |
+ |
{ |
} |
( |
) |
| |
PCRE는 Perl 호환 정규식으로, 대부분의 고급 정규식 기능은 PCRE와 관련된 것이기도 합니다.
많은 수의 프로그래밍 언어의 빌트인 라이브러리에 포함되는 정규식 구현체들은 PCRE 스펙을 참고하고 있습니다.
보통 정규식의 중요 기능으로 여겨지곤 하는 전후방탐색이나 수량자의 다양한 옵션, 그룹 캡처링, 역참조, 주요 이스케이프 시퀀스 등은 PCRE에서 비롯된 것입니다. 그래서 보통 프로그래밍 언어에서 정규식을 사용하고 있다면 BRE나 ERE가 아니라 PCRE 기능을 사용하고 있을 가능성이 높습니다. 다만 PCRE는 기능이 매우 많아서 대부분의 PCRE를 참고한 정규식 구현체들은 모든 기능을 구현하지 않기도 합니다.
하지만 그럼에도 불구하고 상식으로 BRE를 알아둘 필요는 있는데 옵션 없이 사용하는 [[/cmd/grep]], [[/cmd/sed]] 등이 BRE로 돌아가기 때문입니다.
[[/cmd/grep]], [[/cmd/sed]]에서 BRE가 아니라 ERE를 사용하려면 -E 옵션을 사용하면 됩니다.
몇 가지 정규식 사용 도구 비교
다음은 macOS에서 정규식을 사용하는 몇 가지 도구들을 제 마음대로 비교/정리해 본 것입니다.
- th
- 설치 방법
- BRE
- ERE
- PCRE
- 특징
- td
- [[/cmd/grep]]{macOS 빌트인 grep}
- 설치되어 있음
- default
-E- 지원안함
-
- GNU grep에 비해 엄청나게 느림
- 보통 macOS를 쓰는 회사라면 다같이 쓰는 셸 스크립트에서 주로 이걸 사용함
- td
- GNU grep
-
brew install grepggrep으로 실행
- default
-E-P-
- macOS에 설치되어 있는 grep보다 많이 빠름
- 귀찮게 설치해야 한다는 걸 빼고는 macOS grep보다 모든 점이 좋음
- td
- macOS 빌트인 egrep
- 설치되어 있음
-G- default
- 지원안함
-E를 안 적어도 되어서 macOS grep보다 덜 귀찮음
- td
- GNU egrep
-
- GNU grep과 함께 설치됨
gegrep으로 실행
-G- default
-P- deprecated. 실행하면 GNU grep을 사용하라고 경고 메시지가 나옴
- td
- [[/cmd/sed]]{macOS 빌트인 sed}
- 설치되어 있음
- default
-E- 지원안함
- 기능 지원보다 빠른 속도가 더 중요해서 PCRE 지원을 안함
- td
- [[/cmd/perl-one-liner]]{perl 5}
- 설치되어 있음
- 지원안함
- 지원안함
- default2
- 시대를 풍미한 프로그래밍 언어
- td
- [[/cmd/ag]]
brew install ag- 지원안함
- 지원안함
- default
-R옵션이 기본. 거의 매일 사용함.
- td
- [[/cmd/rg]]{rg}
brew install rg-P-
- [[/cmd/ag]]보다 빠름.
-R옵션이 기본.
grep -E로 ERE 사용해보기
[[/cmd/grep]]의 ERE를 실습해보기 위해 연습용 데이터를 생성하는 명령을 설치해 봅시다.
brew install rig
[[/cmd/rig]]는 Random Identity Generator의 약자로, 랜덤한 이름과 이메일 주소를 생성해주는 명령입니다.
설치가 된 다음 실행해보면 랜덤한 가상인물의 개인정보가 생성되는 것을 볼 수 있습니다.
$ rig
Stevie Kirk
984 Hamlet St
Yonkers, NY 10701
(914) xxx-xxxx
-c 옵션을 통해 생성할 개인정보의 개수를 지정할 수 있습니다. 이번에는 -c3으로 3개를 생성해봅시다.
$ rig -c3
Reyna Marquez
355 Hamlet St
Wichita, KS 67276
(316) xxx-xxxx
Lorraine Petersen
571 Ashland St
Appleton, WI 54911
(414) xxx-xxxx
Jed Stark
640 Dorwin Rd
Spokane, WA 99210
(509) xxx-xxxx
좋습니다. 이제 실습용으로 1,000 명의 가상인물 정보를 생성해서 파일로 저장해봅시다.
rig -c1000 > people.txt
생성된 people.txt 파일의 라인 수를 세어봅시다.
$ wc -l people.txt
4999 people.txt
4,999 줄이 생성됐네요. 이제 [[/cmd/grep]]으로 이 파일에서 John 이라는 단어가 포함된 모든 줄을 출력해 봅시다.
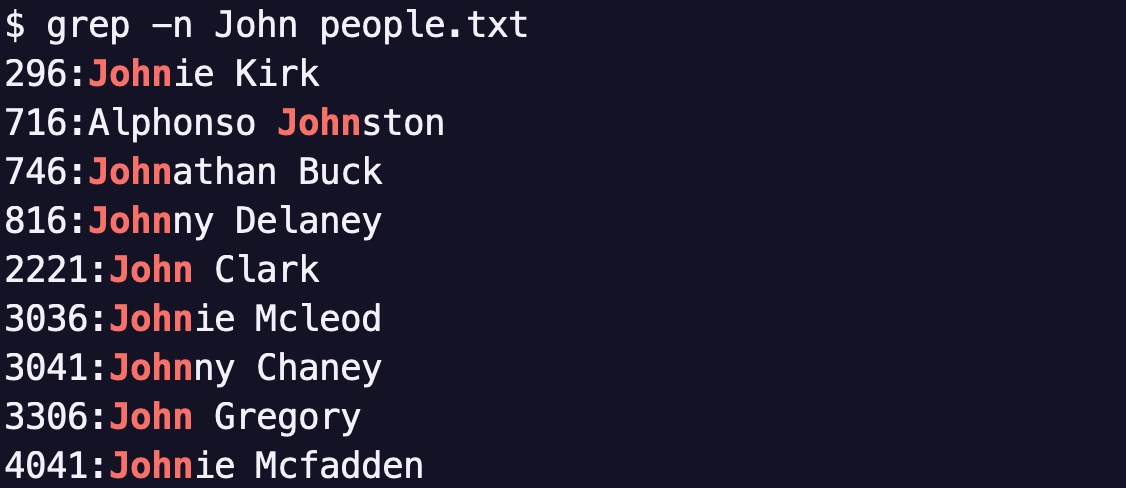
John 뒤에 다른 알파벳이 오는 경우도 매치시키려면 이렇게 해야 합니다.
grep 'John\([a-z]\)*' people.txt
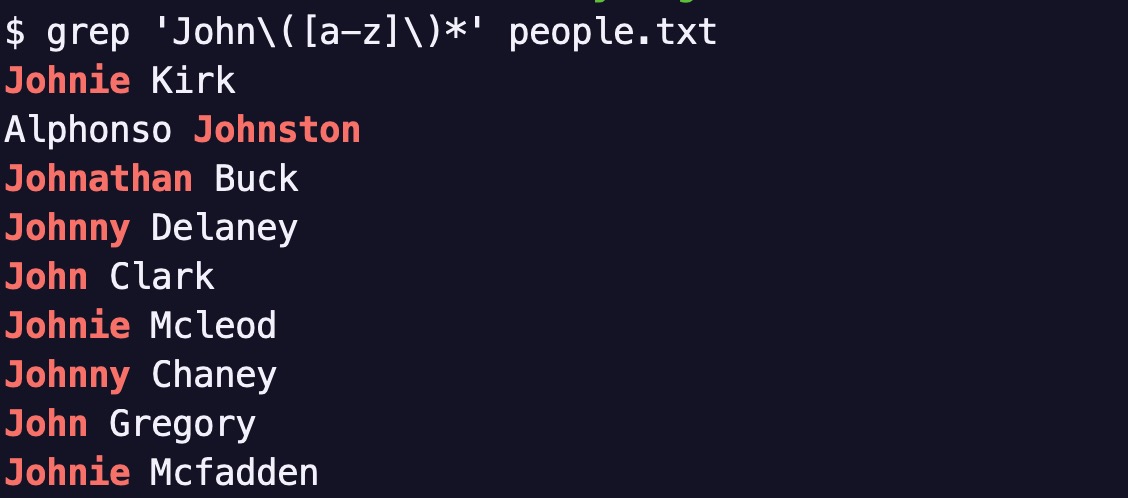
BRE를 쓰고 있기 때문에 괄호 앞에 \를 넣어야 하는 것이 꽤 짜증납니다.
그러니 \를 덜 써도 되는 ERE를 쓰는 것이 더 편합니다.
grep -E 'John([a-z])*' people.txt
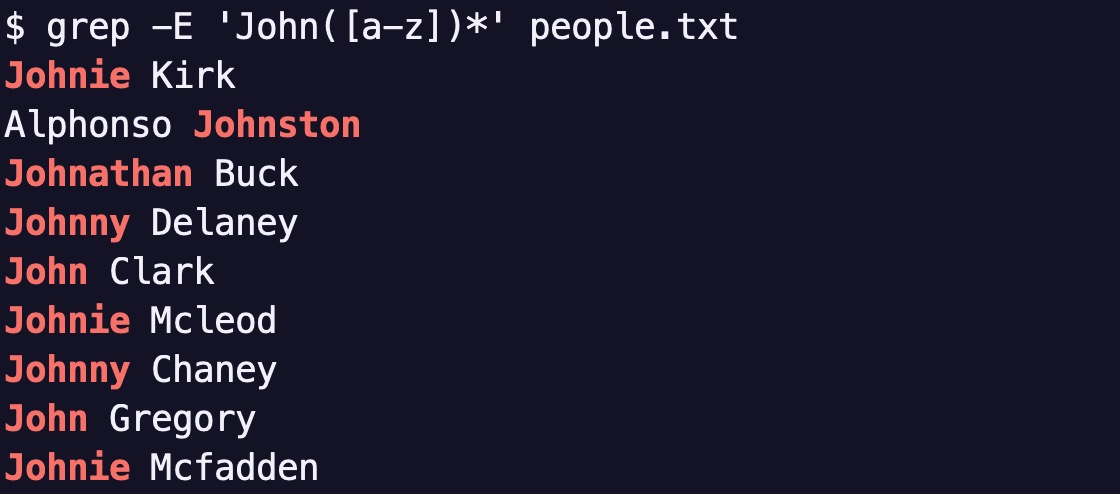
괄호를 많이 사용해야 할 때가 바로 BRE가 정말 짜증나는 경우입니다.
grep '\([aeiou]\{1,2\}\)[a-z] [A-Z]\([aeiou]\{2\}\)' people.txt
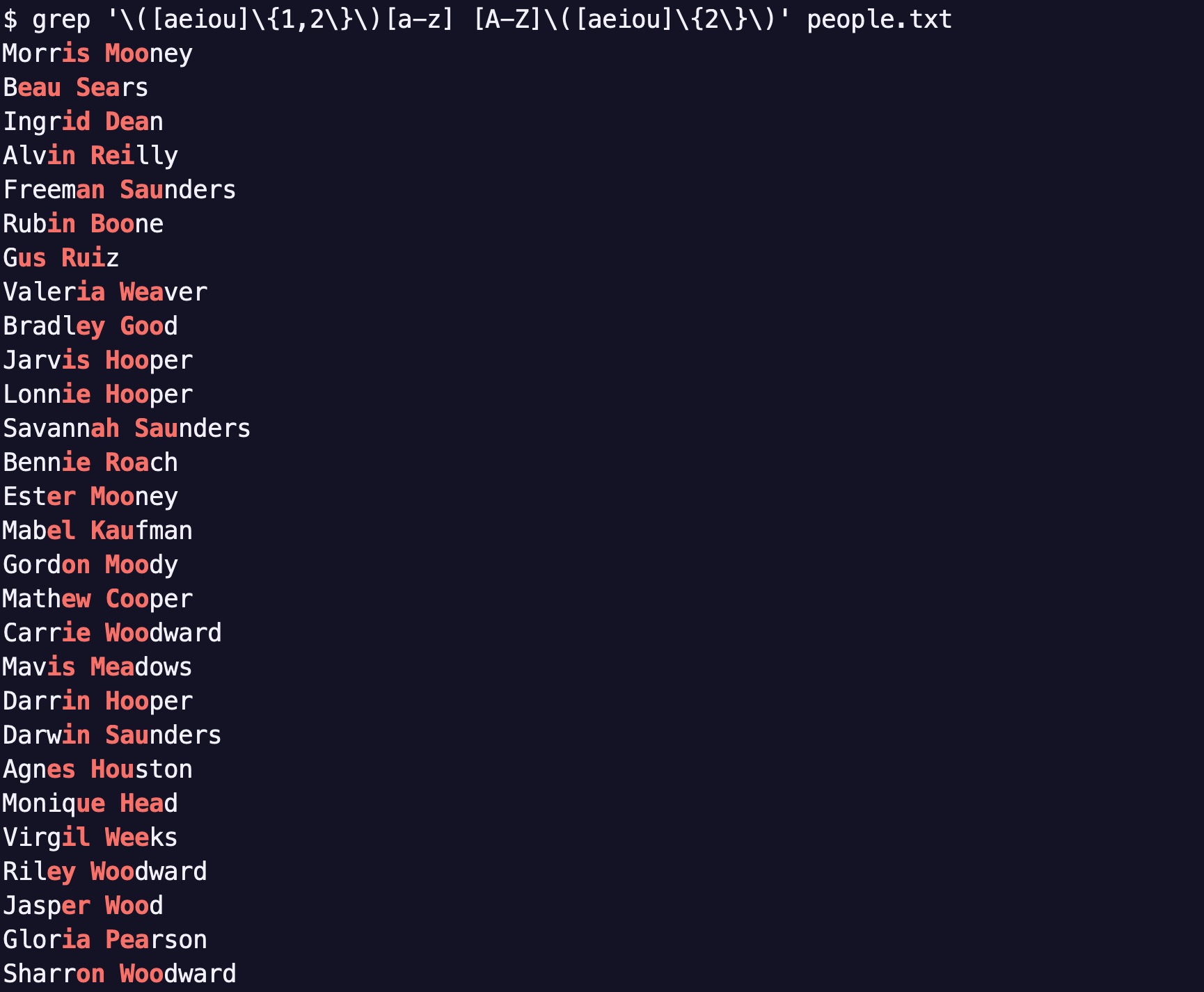
ERE를 쓰면 괄호 앞의 \가 대부분 사라지니 훨씬 타이핑하기 쉽습니다.
grep -E '([aeiou]{1,2})[a-z] [A-Z]([aeiou]{2})' people.txt
ag, rg 사용해보기
[[/cmd/ag]]와 [[/cmd/rg]]{rg}는 [[/cmd/grep]]의 현대적인 대안으로 널리 사용되고 있습니다.
ag가 rg보다 먼저 나왔고, rg가 ag보다 더 빠른 편이지만 저는 손에 익어서 ag를 더 많이 사용하는 편입니다.
이 가이드를 읽는 여러분은 ag와 rg를 모두 설치해서 [[/cmd/grep]]과 비교해보며 사용해보시기를 권합니다.
상황에 따라 용도에 맞겠다 싶은 것을 사용하면 됩니다.
ag와 rg는 대체로 다음과 같은 특징이 있습니다.
- [[/cmd/grep]]보다 빠른 경우가 많습니다.
- PCRE2를 지원하며,
ag의 경우 default로 PCRE를 사용합니다. - [[/cmd/grep]]의
-R옵션이 default로 켜져 있습니다. - GNU grep과 많은 옵션이 호환되어, GNU grep에 익숙한 사람이라면 별로 공부하지 않아도 쉽게 사용할 수 있습니다.
- grep에 비해 편의를 위한 다양한 옵션들이 추가되어 있습니다.
ag와 rg는 다음과 같이 설치하면 됩니다.
brew install ag
brew install rg
PCRE 맛보기
[[/regex/pcre]]를 공부하는 것은 이 가이드의 범위를 벗어나므로, 여기서는 PCRE의 편리한 기능 위주로 몇 가지를 간단히 맛보기만 하겠습니다.
인용하기
PCRE에는 \Q로 시작해서 \E로 끝나는 인용 기능이 있습니다. 이 기능을 사용하면 \Q와 \E 사이에 있는 문자열을 그대로 매치시킬 수 있습니다.
johngrib.github.io 리포지토리에서 \[[/cmd]]와 매치되는 문자열을 찾아봅시다.
먼저 macOS에 설치되어 있는 grep 부터 사용해 봅시다.
$ grep -R -E '\[\[/cmd\]\]' | head
./_wiki/cmd/tr.md:parent : [[/cmd]]
./_wiki/cmd/find.md:parent : [[/cmd]]
./_wiki/cmd/make.md:parent : [[/cmd]]
./_wiki/cmd/chsh.md:parent : [[/cmd]]
./_wiki/cmd/basename.md:parent : [[/cmd]]
./_wiki/cmd/chardetect.md:parent : [[/cmd]]
./_wiki/cmd/touch.md:parent : [[/cmd]]
./_wiki/cmd/factor.md:parent : [[/cmd]]
./_wiki/cmd/strfile.md:parent : [[/cmd]]
./_wiki/cmd/gpg.md:parent : [[/cmd]]
grep -R: 현재 디렉토리부터 재귀적으로 모든 파일을 검색합니다.grep -E: ERE를 사용합니다.\[\[/cmd\]\]:\[[/cmd]]를 매치시킵니다.[와]를 검색해야 하므로\로 escape합니다.
| head: 결과의 첫 10줄만 출력합니다.
\를 4번이나 타이핑해서 피곤한 느낌입니다. PCRE의 인용 기능을 사용하면 \를 2번만 타이핑하면 됩니다.
GNU grep으로 PCRE를 사용해 봅시다.
$ ggrep -R -P '\Q[[/cmd]]\E' | head
_wiki/cmd/tr.md:parent : [[/cmd]]
_wiki/cmd/find.md:parent : [[/cmd]]
_wiki/cmd/make.md:parent : [[/cmd]]
_wiki/cmd/chsh.md:parent : [[/cmd]]
_wiki/cmd/basename.md:parent : [[/cmd]]
_wiki/cmd/chardetect.md:parent : [[/cmd]]
_wiki/cmd/touch.md:parent : [[/cmd]]
_wiki/cmd/factor.md:parent : [[/cmd]]
_wiki/cmd/strfile.md:parent : [[/cmd]]
_wiki/cmd/gpg.md:parent : [[/cmd]]
ggrep -R: GNU grep,-R옵션을 사용합니다.ggrep -P: PCRE를 사용합니다.\Q[[/cmd]]\E:\[[/cmd]]를 매치시킵니다.\Q와\E사이에 있는 문자열을 그대로 매치시키므로 좀 더 보기 편하고 타이핑도 쉽습니다.
이번에는 [[/cmd/ag]]를 사용해 봅시다.
$ ag '\Q[[/cmd]]\E' | head
_wiki/cmd/tr.md:11:parent : [[/cmd]]
_wiki/cmd/find.md:11:parent : [[/cmd]]
_wiki/cmd/make.md:11:parent : [[/cmd]]
_wiki/cmd/chsh.md:11:parent : [[/cmd]]
_wiki/cmd/chardetect.md:11:parent : [[/cmd]]
_wiki/cmd/touch.md:11:parent : [[/cmd]]
_wiki/cmd/basename.md:11:parent : [[/cmd]]
_wiki/cmd/strfile.md:11:parent : [[/cmd]]
_wiki/cmd/jq.md:11:parent : [[/cmd]]
_wiki/cmd/uniq.md:11:parent : [[/cmd]]
ag는 PCRE를 default로 사용하므로, -P 옵션을 사용하지 않아도 됩니다. 타이핑이 더 편하네요.
언어 문자셋 매치하기
PCRE에는 국가/언어별 문자셋을 매치할 수 있는 기능도 있습니다.
예를 들어 한국어는 \p{Hangul}로 매치할 수 있습니다.
$ curl https://en.wikipedia.org/wiki/Korean_language | ggrep -Po '\p{Hangul}+' | head
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 584k 100 584k 0 0 625k 0 --:--:-- --:--:-- --:--:-- 625k
한국어
한국어
한국어
조선말
국립국어원
사회과학원
어학연구소
중국조선어규범위원회
한국어
한국어
curl https://en.wikipedia.org/wiki/Korean_language: 영문 위키피디아에서 한국어 문서를 다운로드합니다.ggrep -P '\p{Hangul}+': PCRE를 사용해 한글만 매치시킵니다.ggrep -o: 매치된 문자열만 출력합니다. (-Po로-P와-o옵션을 하나로 합쳤습니다.)head: 결과의 첫 10줄만 출력합니다.
물론 [[/cmd/rg]]{rg}로도 됩니다. 이번에는 한글 5글자 이상인 단어만 매치시킨 다음 가장 많이 나온 단어 10개를 출력해 봅시다.
$ curl https://en.wikipedia.org/wiki/Korean_language | rg -Po '\p{Hangul}{5,}' | sort | uniq -c | sort -n | tail
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 584k 100 584k 0 0 632k 0 --:--:-- --:--:-- --:--:-- 631k
2 추어졌누만
2 추워졌구나
2 클아바네요
2 판매자에게
2 행동하여야
2 부여받았으며
2 치워뒀으니까
2 치워뒀으니께
2 한국민족문화대백과사전
3 국립국어원
curl https://en.wikipedia.org/wiki/Korean_language: 영문 위키피디아에서 한국어 문서를 다운로드합니다.rg -Po '\p{Hangul}{5,}': PCRE를 사용해 한글 5글자 이상인 단어만 매치시킵니다.- [[/cmd/sort]]{sort}: 단어를 정렬합니다.
- [[/cmd/uniq]]{
uniq -c}: 중복을 제거하고, 각 단어가 몇 번 나왔는지 출력합니다. - [[/cmd/sort]]{
sort -n}: 숫자 기준으로 정렬합니다. - [[/cmd/tail]]{tail}: 결과의 마지막 10줄만 출력합니다.
[[/regex/pcre]]에는 이 외에도 강력한 기능이 많이 있으므로 공부해보는 것을 추천합니다.
이전, 다음 문서
- 이전 문서: [[/mac/terminal-guide/03]]
- 다음 문서: [[/mac/terminal-guide/05]]