Clojure의 collection
작성중인 문서
java.util.List 구현체
List
List는 REPL의 출력 결과에서 ( )로 표현된다.
그런데 ( )로 List를 만들면 첫번째 아이템을 함수로 평가하려다 예외를 던지게 된다.
(1 2 3)
Execution error (ClassCastException) at tutorial.core/eval1649 (form-init10906104573479548905.clj:1).
class java.lang.Long cannot be cast to class clojure.lang.IFn (java.lang.Long is in module java.base of loader 'bootstrap'; clojure.lang.IFn is in unnamed module of loader 'app')
위의 에러 메시지를 잘 읽어보자. 1을 clojure.lang.Ifn으로 캐스팅하려 했지만 1은 함수가 아니기 때문에 캐스팅이 실패한 것이다.
이런 리터럴을 함수 호출이 아니라 List로 사용하려면 평가를 방지하기 위해 '(quot, 인용) 심볼을 앞에 붙인다.
'(1 2 3)
이렇게 만든 List의 타입은 clojure.lang.PersistentList이다. [[/clojure/study/persistent-list]]도 잊지 말고 읽어 두도록 하자. 연결 리스트 구조로 되어 있다는 것도 잊지 말자.
(class '(1 2)) ; clojure.lang.PersistentList
한편 REPL에서 리스트를 평가해보면 다음과 같이 문자열로 표현되어 출력되는 것을 볼 수 있다.
'(1 2 3)
=> (1 2 3)
이렇게 출력되도록 작동하고 있는 곳은 clojure.lang.RT.java를 읽어보면 찾을 수 있다.
if(x == null)
w.write("nil");
else if(x instanceof ISeq || x instanceof IPersistentList) {
w.write('(');
printInnerSeq(seq(x), w);
w.write(')');
}
ISeq나 IPersistentList의 구현체라면 양쪽에 (와 )를 붙여서 출력하도록 되어 있다.
보너스: 바로 윗줄을 보면 null 값은 nil로 출력하도록 되어 있으니 Java의 null이 Clojure에서 nil로 표현된다는 것도 알 수 있다.
Vector
한편, Vector는 [ ]를 사용해 만들 수 있고, 타입은 clojure.lang.PersistentVector이다.
소스코드 PersistentVector.java도 틈날 때 읽어두자.
(type [])
=> clojure.lang.PersistentVector
Vector는 get을 사용해 인덱스에 해당하는 값을 꺼낼 수 있다.
(def v [12 52 34 61 19]) ; Vector 선언
(get v 2) ; 34
(get [65 31 58] 1) ; 31
get을 제외하면 Javascript와 비슷한 느낌이다.
const v = [12, 52, 34, 61, 19];
v[2]; // 34
[65, 31, 58][2]; // 31
길이는 count로 잴 수 있다.
(count v) ; 5
Vector에 아이템을 추가하려면 conj를 사용한다.
어원은 "conjoin(결합, 연합)"이라 한다.
(conj v 1 2 3)
; [12 52 34 61 19 1 2 3]
Javascript의 push와 비슷하게 작동하는 것 같이 보이지만…
v.push(1, 2, 3);
console.log(v); // [12, 52, 34, 61, 19, 1, 2, 3]
Javascript의 push는 list의 뒤에 아이템을 이어붙이기 때문에 list가 변경된다.
그러나 Clojure의 Vector는 불변 자료형이므로 conj를 통해 변경되지 않는다.
conj는 새로운 Vector를 만들어 리턴한 것이므로, conj의 결과에 이름을 붙일 필요가 있다면 따로 바인딩을 해줘야 한다.
(conj v 1 2 3)
; [12 52 34 61 19 1 2 3]
(println v)
; [12 52 34 61 19]
한편 Vector를 슬라이싱할 때에는 subvec을 사용한다. 이것도 새로운 Vector를 리턴한다는 점에 주의해야 한다.
이번 예제에서는 number가 아니라 char Vector를 만들어 보자.
(subvec [\a \b \c \d] 2)
=> [\c \d]
(subvec [\a \b \c \d] 2 3)
=> [\c]
Vector는 REPL에서도 [ ]와 같이 출력되는데, 이것도 RT.java를 보면 알 수 있다.
else if(x instanceof IPersistentVector) {
IPersistentVector a = (IPersistentVector) x;
w.write('[');
for(int i = 0; i < a.count(); i++) {
print(a.nth(i), w);
if(i < a.count() - 1)
w.write(' ');
}
w.write(']');
}
List와 Vector의 인덱스 접근과 Vector의 tailoff
PersistentList는 연결 리스트 구조이기 때문에 nth와 last를 사용할 때 효율이 좋지 않다.
PersistentList에서의 get 연산 코드를 읽어보면 랜덤 엑세스를 하지 않고 for 루프를 돌면서 값을 가지러 간다는 것을 알 수 있다.
else if(coll instanceof Sequential) {
ISeq seq = RT.seq(coll);
coll = null;
for(int i = 0; i <= n && seq != null; ++i, seq = seq.next()) {
if(i == n)
return seq.first(); // 해당 인덱스에 도달하면 시퀀스의 첫번째 아이템을 리턴한다.
}
throw new IndexOutOfBoundsException();
}
한편 Vector는 Java의 배열을 사용하고 있으므로 거의 모든 인덱스에 대해 좀 더 효율적인 엑세스가 가능하다.
public Object[] arrayFor(int i){
if(i >= 0 && i < cnt)
{
if(i >= tailoff())
return tail;
Node node = root;
for(int level = shift; level > 0; level -= 5)
node = (Node) node.array[(i >>> level) & 0x01f];
return node.array;
}
throw new IndexOutOfBoundsException();
}
public Object nth(int i){
Object[] node = arrayFor(i);
return node[i & 0x01f]; // 여기!
}
arrayFor 메소드를 잘 살펴보면 if(i >= tailoff()) 인 경우에는 tail을 리턴한다는 것을 알 수 있다.
PersistentVector의 tail은 평범한 Object 배열이다. 따라서 인덱스가 tailoff 이상인 경우에는 그냥 배열을 사용하는 셈이다.
public final Object[] tail;
하지만 tailoff보다 작다면 뭔가 for 루프를 돌게 된다.
그렇다면 tailoff는 무엇일까? tailoff() 메소드의 코드를 읽어보면 다음과 같다.
final int tailoff(){
if(cnt < 32)
return 0;
return ((cnt - 1) >>> 5) << 5;
}
cnt는 벡터에 포함된 아이템의 수이므로, 아이템의 수가 32개 미만이면 0을 리턴하게 되고, arrayFor 메소드는 그냥 tail 배열을 리턴하게 될 것이다.
한편, 그 외의 경우는 >>>, << 를 사용해 숫자의 오른쪽 비트 5개를 0으로 채운다. tailoff가 cnt에 따라 리턴하는 수를 정리해 보자.
| cnt | 리턴값 | 설명 |
|---|---|---|
| 0 ~ 31 | 0 | 32 미만인 경우 그냥 0 리턴 |
| 32 | 0 | 32 - 1 = 31 이고, 31은 \(11111_2\) 이므로 0. |
| 33 ~ 64 | 32 | 33 = \(1000001_2\), 64 = \(1000000_2\) |
| 65 ~ 96 | 64 | 65 = \(1000001_2\), 96 = \(1100000_2\) |
| … |
즉 tailoff리턴값은 32의 배수로 뛴다.
만약 아이템이 60개가 들어있는 벡터에 대해 50번째 아이템을 get 하려 했다고 가정하자.
그렇다면 tailoff는 32가 될 것이고, 50은 32보다 큰 수이므로 tail에 엑세스하여 값을 리턴할 것이다.
하지만 인덱스가 tailoff보다 작은 경우라면?
아이템이 60개가 들어있는 벡터에 대해 3번째 아이템을 get 하려 했다고 해보자.
그렇다면 tailoff보다 i가 작으므로 root 노드부터 level을 5씩 줄여가며 i 인덱스에 해당하는 아이템이 있는 노드를 찾아 리턴한다.
즉, Clojure의 PersistentVector는 Java의 ArrayList와는 달리 하나의 배열을 다이나믹하게 조절하는 클래스가 아니다.
PersistentVector는 사이즈 32의 배열로 이루어진 각 노드를 연결해 놓은 것이며, 마지막 노드가 tail인 것으로 보인다.
TransientVector의 conj 메소드를 살펴보자. //full tail, push into tree라는 주석이 보인다. tail이 꽉 차면 새로운 루트(newroot.array[1])에 tail을 추가하고, 새로운 tail로 new Object[32]를 만들고 있다.
public TransientVector conj(Object val){
ensureEditable();
int i = cnt;
//room in tail?
if(i - tailoff() < 32)
{
tail[i & 0x01f] = val;
++cnt;
return this;
}
//full tail, push into tree
Node newroot;
Node tailnode = new Node(root.edit, tail);
tail = new Object[32];
tail[0] = val;
int newshift = shift;
//overflow root?
if((cnt >>> 5) > (1 << shift))
{
newroot = new Node(root.edit);
newroot.array[0] = root;
newroot.array[1] = newPath(root.edit,shift, tailnode);
newshift += 5;
}
else
newroot = pushTail(shift, root, tailnode);
root = newroot;
shift = newshift;
++cnt;
return this;
}
이는 32개를 초과하는 아이템을 갖는 PersistentVector를 생성해보면서 디버거를 돌려보면 눈으로 확인할 수 있다.
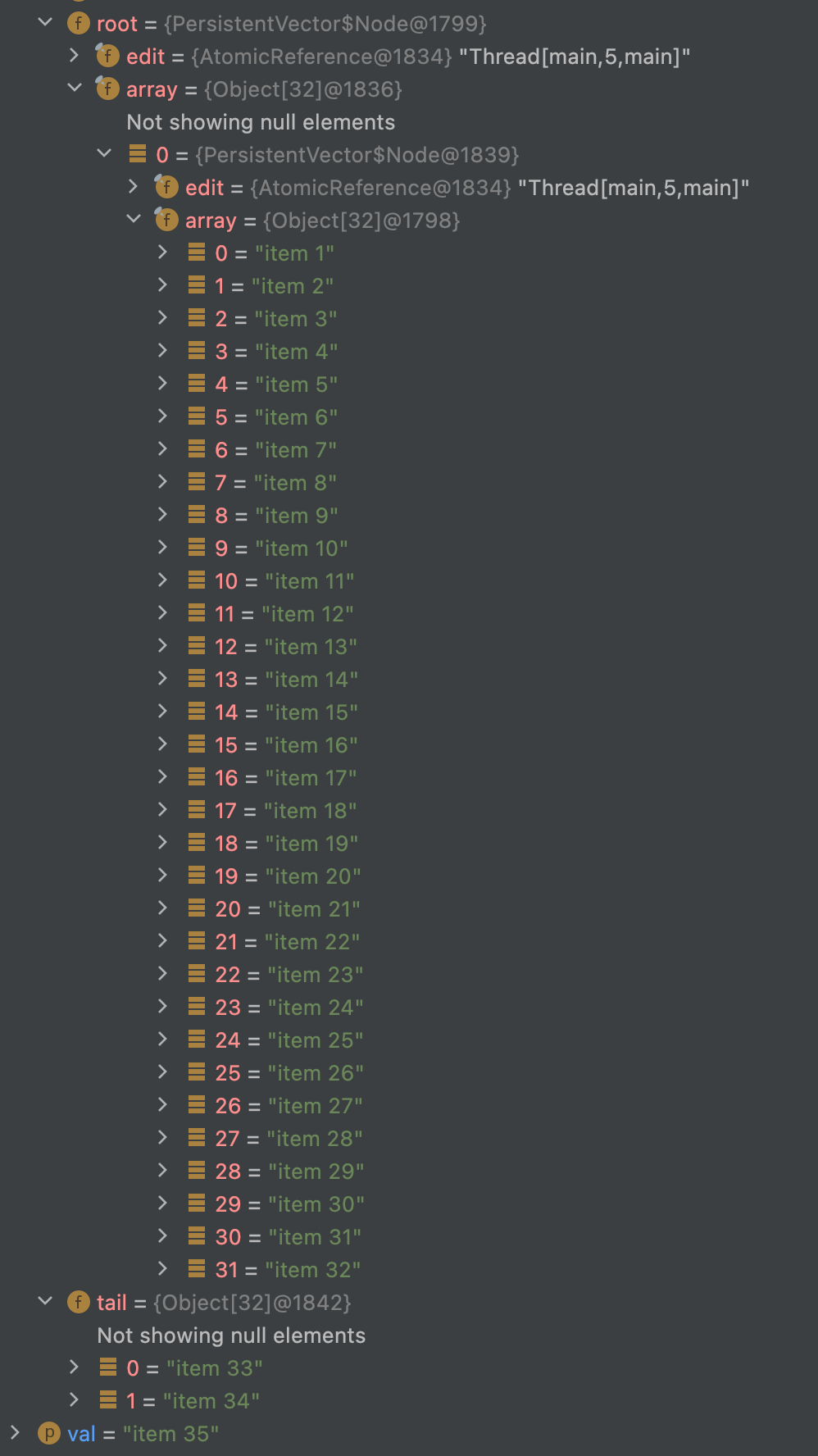
32개의 아이템은 root에 있고, 그 이후의 아이템은 tail에 있다.
64개를 초과하는 아이템을 갖는 벡터를 만들어보면 다음과 같은 구조를 갖는 것도 확인할 수 있다.
- root
- array
- [0] - 1 ~ 32 번째 아이템
- [1] - 33 ~ 64 번째 아이템
- array
- tail
- [0] - 65번째 아이템
- [1] - 66번째 아이템
- …
java.util.Map 구현체
Map 생성
Clojure에서는 {}를 사용해 HashMap을 만들 수 있다.
(def fruit {
"apple" "사과"
"orange" "오렌지"
})
그런데 Clojure에서는 Map의 key로 String보다 Keyword를 주로 사용한다고 한다.
키워드는 Clojure의 기본 타입 중 하나이며, 다양한 용도로 사용한다.
키워드는 :로 시작한다.
(type :foo) ; clojure.lang.Keyword
키워드를 key로 사용하는 Map을 다시 만들어보자.
(def fruit
{
:apple "사과"
:orange "오렌지"
})
(fruit :orange) ; "오렌지"
한편, key 와 value를 따로 표시해주지는 않고 홀수번째 아이템은 key, 짝수번째 아이템은 value가 된다는 것에 주목하자.
이 방식은 PersistentHashMap의 create 구현 코드를 보면 확실히 알 수 있다.
public static PersistentHashMap create(Object... init){
ITransientMap ret = EMPTY.asTransient();
for(int i = 0; i < init.length; i += 2)
{
ret = ret.assoc(init[i], init[i + 1]);
}
return (PersistentHashMap) ret.persistent();
}
Java 코드를 잘 읽어보면 for문이 인덱스를 2씩 증가시키면서 key와 value를 ret(ITransientMap)에 put(assoc)하고 있음을 알 수 있다.
한편 ,는 Clojure에서는 공백으로 인식되는 문자이므로, 위의 코드가 헷갈린다면 편의를 위해 콤마를 집어넣어도 아무런 문제가 없다.
(def fruit {
:apple "사과",
:orange "오렌지",
})
:과 ,만 없을 뿐, Javascript의 Object를 만드는 것과 비슷해 보인다.
var fruit = {
"apple" : "사과",
"orange" : "오렌지"
}
Java에서는 다음과 같이 Map을 만들어 사용한다.
Map<String, String> fruit = new HashMap<>();
fruit.put("apple", "사과");
fruit.put("orange", "오렌지");
하지만 버전이 올라가면서 이렇게 작성할 수도 있게 됐다.
Map<String, String> fruit = Map.of(
"apple", "사과",
"orange", "오렌지"
);
Java의 Map.of가 사용하고 있는 MapN 메소드도 살펴보면 for에서 2씩 인덱스를 증가시키는 방법이다. 즉 Clojure와 크게 다르지 않다.
MapN(Object... input) {
if ((input.length & 1) != 0) { // implicit nullcheck of input
throw new InternalError("length is odd");
}
size = input.length >> 1;
int len = EXPAND_FACTOR * input.length;
len = (len + 1) & ~1; // ensure table is even length
table = new Object[len];
for (int i = 0; i < input.length; i += 2) {
@SuppressWarnings("unchecked")
K k = Objects.requireNonNull((K)input[i]);
@SuppressWarnings("unchecked")
V v = Objects.requireNonNull((V)input[i+1]);
int idx = probe(k);
if (idx >= 0) {
throw new IllegalArgumentException("duplicate key: " + k);
} else {
int dest = -(idx + 1);
table[dest] = k;
table[dest+1] = v;
}
}
}
PersistentArrayMap과 PersistentHashMap
똑같이 {}를 사용해 생성하더라도 아이템의 수에 따라 구현체가 달라진다는 것은 기억해 둘 필요가 있어보인다.
엔트리가 8개 이하인 경우에는 PersistentArrayMap이 생성되고, 8개를 초과한 경우에는 PersistentHashMap이 생성된다.
(type {1 1, 2 2})
=> clojure.lang.PersistentArrayMap
(type {1 1, 2 2, 3 3, 4 4, 5 5, 6 6, 7 7, 8 8})
=> clojure.lang.PersistentArrayMap
(type {1 1, 2 2, 3 3, 4 4, 5 5, 6 6, 7 7, 8 8, 9 9})
=> clojure.lang.PersistentHashMap
엔트리의 수가 적은 경우에 사용되는 PersistentArrayMap은 내부에 배열을 두고 있다. 오버헤드를 줄이고 퍼포먼스 향상을 위한 선택인 것으로 보인다.
public class PersistentArrayMap extends APersistentMap implements IObj, IEditableCollection, IMapIterable, IKVReduce{
final Object[] array;
static final int HASHTABLE_THRESHOLD = 16;
HASHTABLE_THRESHOLD가 16이라는 것은 배열의 사이즈 최대값을 의미한다.
배열에 들어간 key와 value가 번갈아가며 있다는 것도 확인할 수 있다.
public IMapEntry entryAt(Object key){
int i = indexOf(key);
if(i >= 0)
return (IMapEntry) MapEntry.create(array[i],array[i+1]);
return null;
}
배열이기 때문에 count나 containsKey 메소드의 구현도 배열답게 되어 있다.
public int count(){
return array.length / 2;
}
public boolean containsKey(Object key){
return indexOf(key) >= 0;
}
get
Clojure에서 Map의 값을 꺼내는 것은 엄청 단순하다. Map이 바인딩된 상수를 그대로 함수처럼 쓰면 된다.
(def fruit {
:apple "사과"
:orange "오렌지"
})
(fruit :apple) ; "사과"
(:apple fruit) ; "사과" ; 이렇게 반대로 해도 된다
(get fruit :apple) ; "사과" ; get 함수를 쓰는 방법
없는 값에 대한 대안이 필요하다면 get을 쓰면 된다.
(get fruit "apple" "없는 과일입니다.") ; "사과"
(get fruit "fineapple" "없는 과일입니다.") ; "없는 과일입니다."
get이 생각이 안 난다면 Java Map의 getOrDefault를 써도 되긴 하지만 기왕이면 Java의 메소드보다 Clojure 함수를 사용하도록 하자.
(.getOrDefault fruit "fineapple" "없는 과일입니다.") ; "없는 과일입니다."
assoc
assoc 함수를 쓰면 새로운 엔트리를 추가한 map을 생성할 수 있다. 그러나 Clojure의 map은 불변이라는 점에 주의할 필요가 있다.
(assoc fruit :banana "바나나")
=> {:apple "사과", :orange "오렌지", :banana "바나나"}
fruit
=> {:apple "사과", :orange "오렌지"}
dissoc
엔트리를 제거한 map 생성은 dissoc을 사용하면 된다.
(dissoc fruit :apple)
=> {:orange "오렌지"}
keys, vals
keys, vals 함수를 사용해서 key와 values의 리스트를 얻을 수 있다.
(keys fruit)
=> (:apple :orange)
(vals fruit)
=> ("사과" "오렌지")
java.util.Set 구현체
collection 다루기
first
first는 첫 번째 아이템을 리턴한다.
(first [12 52 34 61 19]) ; 12
Map에 사용하면 첫 번째 엔트리를 얻을 수 있다.
(first {:a 1 :b 2 :c 3}) ; [:a 1]
rest
첫 번째 아이템을 제거한 리스트는 rest로 얻는다. 재귀할 일이 있을 때 종종 사용하게 되겠지.
(rest [12 52 34 61 19]) ; (52 34 61 19)
(rest [1 2 3]) ; (2 3)
cons
cons는 아이템 하나를 컬렉션의 앞에 추가한다.
(cons 3 [:a :b]) ; (3 :a :b)
(cons 3 #{:a :b}) ; (3 :b :a)
Map에 cons를 사용하면 리스트를 리턴하므로 주의하자.
(cons :a {:b 7 :c 8}) ; (:a [:b 7] [:c 8])
take
take는 앞에서부터 잘라낸 리스트를 리턴한다.
(take 2 [12 52 34 61 19]) ; (12 52)
reverse
reverse는 뒤집는다.
(reverse [12 52 34 61 19]) ; (19 61 34 52 12)