Clojure를 학습하며 남기는 기록과 예제 0
- 버전 확인
- 수
- def, let
- 문자열 다루기
- 제어문
- Collection
- 구조체
- 함수 선언
- namespace
- 동등비교
- metadata
- Java 코드 호출
- try catch finally
- 참고문헌
- 주석
버전 확인
$ clojure --version
Clojure CLI version 1.10.3.1040
수
[[/clojure/study/number]]
def, let
def를 사용해 값에 이름을 붙일 수 있다.
(def a 10)
(println a)
def로 지정한 이름은 재지정도 가능하다.
(def a 10) (println a) ; 10
(def a 89) (println a) ; 89
def를 함수 내에서 사용하면 함수 호출이 끝난 후에도 def로 선언한 상수를 사용할 수 있다.
(defn hello
[]
(def a 3))
(hello)
(println a) ; 3
Javascript의 const와 같을 거라 생각했는데 착각이었다.
'프로그래밍 클로저' 책을 읽어보니 이런 설명이 있다.
def나defn을 사용해 새 객체를 정의할 때마다 그 객체는 클로저var속에 저장된다.
아직 자세히는 모르겠지만 Java의 stack에 들어가는 frame 같은 개념으로 보인다. 천천히 알아가보자.
한편 let은 Javascript의 let과 비슷한 느낌으로 쓸 수 있는 것 같다.
다음 코드의 a는 let이 선언된 스코프 내에서만 사용 가능하다.
(let [a 10]
(println (+ a 42)))
여러 값을 선언할 수도 있다.
(let [a 10, b 23]
(println (+ a b)))
Clojure에서 ,는 공백과 똑같이 판별되므로 위의 코드는 아래와 같은 의미를 갖는다.
(let [a 10 b 23]
(println (+ a b)))
문자열 다루기
Clojure의 문자열 concatenation은 str을 사용하면 된다.
(println (str "123" "456" "789"))
; 123456789
String.format은 Java와 똑같은 것 같다.
(println
(format "hello %s %d"
"world" 123))
; hello world 123
문자열의 길이는 count로 셀 수 있다. 물론 Java String의 length 메소드도 사용할 수 있다.
(println (count "hello"))
; 5
(println (.length "hello"))
; 5
(println (. "hello" length))
; 5
Java String의 length 메소드를 사용하는 방법이 2가지 있다는 점을 잘 기억해두자.
substring은 subs를 사용한다. 물론 Java String의 substring 메소드도 사용할 수 있다.
(println (subs "hello" 1 4))
; ell
(println (.substring "hello" 1 4))
; ell
(println (subs "hello" 1))
; ell
(println (.substring "hello" 1))
; ello
이렇게 Java의 메소드를 그대로 사용할 수 있는 건 꽤 편안하게 느껴진다.
반면 정규식을 사용한 replace는 Java보다 더 편리한 느낌이다. Clojure는 #"pattern"과 같이 정규식 리터럴을 따로 제공하는데, 정규식 내에서 역슬래시를 두 번 써서 이스케이프하지 않아도 된다.
(println (clojure.string/replace
"Hello World" #"^Hello\s" "---"))
; ---World
위의 ^Hello\s를 잘 보면 공백문자 패턴으로 \s를 그대로 사용하고 있다. Java였다면 \\s로 사용해야 했을 것이다.
Java에서 정규식을 사용할 때 이것 때문에 항상 짜증이 났다.
Perl처럼 엄청 간편하게 정규식을 선언할 수 있다면 훨씬 좋았겠지만 이 정도도 불편하진 않다. 괜찮아 보인다.
아무튼 위의 정규식 리터럴이 생성하는 타입은 java.util.regex.Pattern이다.
다음은 Clojure 레퍼런스 문서에 있는 정규식 예제의 모습을 조금 수정한 것이다.1
(re-seq #"[0-9]+" "abs123def345ghi567")
;("123" "345" "567")
(re-find #"([-+]?[0-9]+)/([0-9]+)" "22/7")
;["22/7" "22" "7"]
(let
[[a b c] (re-matches #"([-+]?[0-9]+)/([0-9]+)" "22/7")]
[a b c])
;["22/7" "22" "7"]
(re-seq #"(?i)[fq].." "foo bar BAZ QUX quux")
;("foo" "QUX" "quu")
잘 살펴보면 정규식의 옵션 플래그는 #"(?옵션)hello" 처럼 정규식 패턴 앞쪽에 둔다는 것도 알 수 있다.
제어문
분기
Clojure에서는 참/거짓을 구분해야 할 때에는 nil과 false가 아닌 모든 것은 true로 평가된다는 것만 기억하면 된다.
if는 true인 경우와 false인 경우의 표현식을 제공해주면 된다.
(def b 10)
(println
(if (> b 2)
"b는 2보다 큽니다."
"b는 2보다 크지 않습니다."))
cond를 else if처럼 쓸 수 있다.
(def x 28)
(println
(cond
(< x 10) "10 미만"
(< x 20) "10 이상 20 미만"
(< x 30) "20 이상 30 미만"
:else "30 초과")
)
; 20 이상 30 미만
case는 swtich와 비슷하다.
(def a "apple")
(case a
"test" (println "테스트")
"apple" (println "사과"))
; 사과
만약 각 분기에서 한 가지 이상의 일을 하는 것이 필요하다면 do를 쓰자.
(def b 10)
(println
(if (> b 2)
(do
(println "b는 2보다 큽니다.")
(println "하하하.."))
(do
(println "b는 2보다 크지 않습니다.")
(println "...."))))
; b는 2보다 큽니다.
; 하하하..
반복
loop를 사용해 반복을 시킬 수 있다. loop 키워드의 바로 뒤에 있는 [ ]에는 let처럼 변수를 선언할 수 있다.
(loop [i 0]
(when (< i 5)
(print i "")
(recur (+ i 1)))) ; 재귀
; 0 1 2 3 4
Java라면 같은 일을 하는 코드를 이렇게 작성했을 것이다.
for (int i = 0; i < 5; i++) {
System.out.print(i + " ");
}
// 0 1 2 3 4
하지만 Clojure 코드에서는 i를 재할당하지 않고 재귀를 하고 있다.
따라서 Java로 위의 에제와 비슷한 코드를 작성한다면 다음과 같을 것이다.
@Test
void execute() {
loopFunc(0); // 0은 i의 초기값
}
void loopFunc(int i) {
if (i < 5) {
System.out.print(i + " ");
loopFunc(i + 1); // 재귀
}
}
recur 키워드는 꽤 편리한 느낌이다.
Javascript에서는 재귀할 일이 있어도 이런 키워드가 없어서 익명함수에도 이름을 붙여줘야 했다.
(function loopFunc(i) { // 어쩔 수 없이 loopFunc 라는 이름을 붙여줌
if (i < 5) {
console.log(i);
loopFunc(i + 1); // 붙여준 이름을 사용해 재귀
}
})(0); // 0 은 i의 초기값
한편 recur은 loop에서만 작동하지 않는다. 함수에서도 작동한다.
(defn test-count [i]
(if (< i 5)
(do
(print i "")
(recur (+ i 1)))
(println)))
(test-count 0) ; 0 1 2 3 4
(test-count 2) ; 2 3 4
Collection
Map, List, Vector
([[/clojure/study/collection]]으로 문서를 분리했다.)
구조체
Clojure에 조금 익숙해지고 나니 Clojure 구조체보다 hashmap을 더 사용한다는 것을 알게 됐다.
구조체는 사실 쓸 일이 없다. 이런 게 있다고만 알아두자.
구조체 선언은 이렇게 한다.
(defstruct person :first-name :last-name :age)
Java라면 다음과 같이 할 것이다.
public class Person {
String firstName;
String lastName;
int age;
}
다음과 같이 새로운 인스턴스를 만들 수 있고, 값을 부를 수도 있다.
(defstruct person :first-name :last-name :age)
(def customer1 (struct person "John" "Grib" 28))
(println customer1)
; 출력 결과는 {:first-name John, :last-name Grib, :age 28}
(println (:age customer1))
; 출력 결과는 28
struct-map을 사용하면 순서를 신경쓰지 않고 키워드별로 값을 할당할 수 있다.
(struct-map person
:age 30
:first-name "John")
; {:first-name "John", :last-name nil, :age 30}
값을 지정하지 않은 키워드가 있다면 nil이 할당된다.
함수 선언
(defn function-name
"함수를 설명하는 주석"
[param1 param2 param3]
; 함수 본문은 여기에..
; 함수 마지막에 평가된 값이 return된다.
)
return
함수 마지막에 평가된 값이 return된다. 만약 이렇다 할 값이 없다면 nil이 return된다.
return 키워드가 없다는 점을 기억해두자.
Ruby나 Scala처럼 return 키워드를 생략 가능한 게 아니라 Elixir처럼 return 키워드가 없다.
early return을 즐겨 쓰는 편이라 좀 아쉽긴 하지만 이해가 가지 않는 상황은 아니다.
Clojure의 괄호는 단순한 표현식이 아니라 스코프를 의미하는 것 같다.
하나의 함수 내에서도 괄호가 계속해서 중첩이 될 수 있는 Clojure에서 (return 3)을 한다면
스택을 거슬러 올라가며 특정 순간에 값을 리턴해줄 수 있어야 하는데 그렇다면 defn이나 fn으로 생성한 함수를 특별취급해야 할 것 같다.
실제 구현체에서 이런 함수들을 어떻게 취급하는지는 아직 모르겠고, 나중에 자세히 조사해봐야 알겠지만 early return의 구현은
goto를 구현하는 느낌이었을듯. 꽤나 골치아픈 문제이지만 구현이 어려워서가 아니라 언어 철학과 상반되어 return이 빠진 느낌.
조사해보니 Common-Lisp의 경우 special keyword로 return-from을 제공해주는 것 같은데2 3 4, 위에서 생각한 것과 비슷한 이유로 정지 시점을 지정해 주는 형태로 사용해야 하는 것으로 보인다.
; common-lisp
(defun accumulate-list (list)
(when (null list)
(return-from accumulate-list 0)) ; return 값은 0. 대상은 accumulate-list을 지정하고 있다.
(+ (first list)
(accumulate-list (rest list))))
TODO: 이 부분은 나중에 좀 더 자세히 조사해 보고 업데이트해 두도록 하자.
따라서 early return이 아쉽다면 cond를 사용하는 정도로 만족하거나 return-from 매크로를 만들면 되겠다.
아무튼 이렇게 만든 함수를 (doc function-name)으로 조사해 보면 주석이 나온다.
(doc function-name)
-------------------------
hello.core/function-name
([] [name])
함수를 설명하는 주석
=> nil
함수 오버로딩
함수 이름이 같아도 입력 파라미터의 수가 다르면 Java의 오버로딩과 똑같이 작동한다.
(defn hello
"함수를 설명하기 위한 주석."
([] "hello world")
([name] (str "hello " name))
)
(hello) ; "hello world"
(hello "john") ; "hello john"
함수를 설명하기 위해 붙여주는 주석은 생략해도 문제없다.
위의 함수 선언문을 Java로 옮기면 다음과 같다.
/** 메소드를 설명하기 위한 주석. */
String hello() {
return "hello world";
}
/** 메소드를 설명하기 위한 주석. */
String hello(String name) {
return "hello " + name;
}
가변 인자
가변 인자를 사용하려면 &를 사용하면 된다.
(defn hello
[person1 person2 & other-people] ; & other-people에 주목
(println "안녕하세요." person1)
(println "안녕하세요." person2)
(if (< 0 (count other-people))
(println
"더 오신 분들이 있네요. 안녕하세요."
(clojure.string/join ", " other-people))
)
)
(hello "john" "mary")
; 안녕하세요. john
; 안녕하세요. mary
(hello "john" "mary" "tom" "hong")
; 안녕하세요. john
; 안녕하세요. mary
; 더 오신 분들이 있네요. 안녕하세요. tom, hong
위의 코드를 Java로 번역하면 다음과 같다. 즉, 인자 목록에서의 &은 Java의 ... 연산자와 같은 역할을 한다.
void hello(String person1, String person2, String... otherPeople) {
System.out.println("안녕하세요. " + person1);
System.out.println("안녕하세요. " + person2);
if (0 < otherPeople.length) {
System.out.println("더 오신 분들이 있네요. 안녕하세요. "
+ String.join(", ", otherPeople));
}
}
destructuring
구조체에 대한 destructuring
나는 Golang의 함수 하나만 정의하는 인터페이스를 꽤 좋아했으므로, Java에서도 비슷한 코드를 작성해 사용하는 경우가 종종 있었다.
// Java
interface IdSupplier {
String getId(); // 고의로 메소드 한 개만 선언한 인터페이스
}
class Member implements IdSupplier {
private String id;
private String name;
private int age;
@Override
public String getId() {
return this.id;
}
public void setId(String id) {
this.id = id;
}
// ...
}
이렇게 getId 메소드 하나만 선언한 IdSupplier 인터페이스를 정의해 주면 id만 필요한 메소드가 있을 때 다른 값에 대한 접근을 쉽게 제한할 수 있었다.
/** 실제로 필요한 것은 id 인데 member를 모두 넘긴다. */
void printId(Member member) {
String id = member.getId();
System.out.println("id: " + id);
member.setId(null); // 이렇게 하면 메소드 설계 의도에서 어긋난다.
}
이 메소드가 하는 일은 id를 출력하는 것 뿐이다. 그러나 Member 클래스에는 setId가 public으로 공개되어 있어 printId 메소드에 나중에 누군가가 setId 메소드를 호출할 위험도 있다.
따라서 다음과 같이 IdSupplier만 제공해 주면 안전하게 getId 메소드만을 사용할 수 있는 Member를 넘겨주는 셈이 된다.
/** 실제로 필요한 getId 메소드만 넘긴다. */
void printId(IdSupplier member) {
String id = member.getId();
System.out.println("id: " + id);
// member.setId(null); // IdSupplier는 setId를 제공하지 않으므로 setId를 쓰면 컴파일 에러 발생
}
그러므로 Clojure의 디스트럭처링은 나에게는 상당히 반가운 기능이다.
(defstruct member :id :name :age)
(defn print-id
[{id :id}] ; destructuring
(println id))
(let
[guest (struct member 42 "John" 28)]
(print-id guest))
; 42
defn print-id 바로 아랫줄의 [{id :id}] 부분이 디스트럭처링을 의미한다.
:id 필드를 갖고 있는 구조체가 입력되면 id 변수에 :id만 할당해 사용한다는 것.
member 구조체에는 :id외에 :name과 :age 필드가 있지만, print-id 함수 내에서는 :id만 사용할 수 있는 셈이다.
Vector에 대한 destructuring
이런 destructuring은 구조체에 대해서만 동작하는 것은 아니다. Vector에 대해서도 동작한다.
(def numbers [1 2 3 4 5])
(let [[x y] numbers]
(println x)
(println y))
; 1
; 2
위의 코드 중 let [[x y] numbers에 주목하자.
numbers Vector의 첫번째, 두번째 아이템만 x, y에 할당하고 있는 것.
만약 건너뛰고 싶은 아이템이 있다면 _를 사용하면 된다.
(def numbers [1 2 3 4 5])
(let [[_ _ x y] numbers]
(println x)
(println y)
)
; 3
; 4
_를 사용해 세번째 아이템부터 x, y에 할당한 것이다.
Perl의 $_, Scala의 _와 미묘하게 다른 느낌이므로 헷갈리지 않도록 주의하자.
그런데 갑자기 의문이 하나 들었다. _는 Vim의 black hole register "_ 처럼 작동하는 것일까?
(def numbers [1 2 3 4 5])
(let [[_ _ x y] numbers]
(println x)
(println y)
(println _)
)
; 3
; 4
; 2
그렇지는 않은 것 같다. 2가 할당되어 있다. 아마도 1, 2가 순서대로 할당된 것 같다.
프로그래밍 클로저 책을 찾아보니 destructuring에서의 _는 비할당을 표현하기 위해 관용적으로 사용하는 심벌이라 한다.5
한편, :as 변수명을 사용하면 destructuring을 하면서도 입력된 컬렉션을 변수명에 바인딩할 수 있다.
(def numbers [1 2 3 4 5])
(let [[x y :as total] numbers]
(println x)
(println y)
(println total)
)
; 1
; 2
; [1 2 3 4 5]
익명 함수
익명 함수는 fn으로 만들 수 있다.
(filter (fn [s] (< 2 (count s))) ["a" "bb" "ccc" "ddd"])
; (ccc ddd)
위의 코드에서 (fn [s] (< 2 (count s)))가 바로 익명 함수이다.
이 코드를 Java의 Stream을 사용해 번역하면 다음과 같다.
Stream.of("a", "bb", "ccc", "dddd")
.filter((s) -> 2 < s.length()) // lambda
.collect(Collectors.toList());
두 익명 함수를 잘 비교해 보자.
| Clojure | Java |
|---|---|
(fn [s] (< 2 (count s))) |
(s) -> 2 < s.length() |
익명 함수를 축약해 선언하기
#()를 사용해 익명 함수를 선언할 수 있다. 다음 코드6의 #(Character/isWhitespace %)가 익명 함수이다.
(defn blank? [s]
(every? #(Character/isWhitespace %) s))
이 함수는 다음과 같이 사용할 수 있다.
(println (blank? "")) ; true
(println (blank? "1a")) ; false
여기에서 인상적인 것들 몇 가지를 살펴보자.
- 함수 이름이
blank?이다. Clojure에서는 함수 이름에 물음표를 쓸 수 있다. Java였다면isBlank로 이름을 지었겠지만, Clojure에서는 그냥blank?로 지을 수 있다. #과%를 사용해 익명 함수를 만든다.- Perl이 떠오르는 축약 문법.
#는 익명 함수의 선언을,%는 첫 번째 argument를 의미한다.7
- Perl이 떠오르는 축약 문법.
#(Character/isWhitespace %)를 Java 코드로 표현하자면 다음과 같다.
Function<Character, Boolean> noname = ((Character c) -> Character.isWhitespace(c));
하지만 Java 사용자들은 아무도 이런 식으로 문자열이 공백인지 체크하지 않는다. 보통은 이렇게 한다.
"sentence".isBlank(); // Java
물론 Clojure에서도 String의 isBlank를 사용할 수 있다.
(.isBlank "sentence") ; Clojure
잘 살펴보면 세미콜론과 공백을 제외하고 모든 문자가 그대로 있다. 순서만 다를 뿐이다.
closure
당연히 Clojure에서도 closure 개념이 있다.
(defn hello [prefix]
(fn [name] (str prefix ", " name))
)
((hello "Hello") "Dexter Morgan") ; Hello, Dexter Morgan
((hello "안녕") "디지몬") ; 안녕, 디지몬
이건 Java보다 Javascript 예제를 함께 들어보는 것이 이해하기 쉬울 것 같다.
function hello(prefix) {
return function (name) {
return prefix + ", " + name;
}
}
hello("Hello")("Dexter Morgan"); // Hello, Dexter Morgan
hello("안녕")("디지몬"); // 안녕, 디지몬
Javascript의 최신 문법을 사용한다면 좀 더 심플하게 작성할 수 있다.
const hello = (prefix) => (name) => prefix + ", " + name;
hello("Hello")("Dexter Morgan"); // Hello, Dexter Morgan
hello("안녕")("디지몬"); // 안녕, 디지몬
물론 Clojure에서도 #, %를 써서 축약 문법으로 표현할 수 있다.
(defn hello [prefix]
#(str prefix ", " %)
)
((hello "Hello") "Dexter Morgan") ; Hello, Dexter Morgan
((hello "안녕") "디지몬") ; 안녕, 디지몬
namespace
resolve를 사용하면 namespace를 확인할 수 있다고 한다. php의 namespace와 비슷한 느낌으로 사용할 수 있을 것 같다.
(def foo 10)
(println (resolve 'foo)) ; #'tutorial.core/foo
나는 지금 tutorial이라는 이름의 프로젝트의 core.clj에서 REPL을 가동하고 있으므로, #'tutorial.core/foo가 이를 표현한 것 같다.
in-ns를 사용하면 새로운 namespace를 만들거나 다른 namespace를 선택할 수 있다고 한다. 일단은 기억만 해 두자.
(in-ns 'johngrib)
Java Class에 한정하여 import를 사용할 수 있다.
(import '(java.io InputStream File))
(println File/separator) ; /
import를 하지 않아도 전체 경로를 명시하면 사용할 수 있다.
(println java.io.File/separator) ; /
Java라면 이렇게 했을 것이다.
System.out.println(java.io.File.separator);
Clojure namespace에 대해서는 require를 사용할 수 있는 것 같다.
(require '(clojure.java.io))
(clojure.java.io/file "filename") ; java.io.File 클래스 인스턴스
그게 그거 같지만 clojure.java.io.File이 아니라 java.io.File을 new 하고 싶다면 이렇게 한다.
(new java.io.File "filename")
:as 키워드를 사용해 require한 namespace의 알리아스를 설정할 수도 있다.
(require '[clojure.java.io :as io])
(io/file "Filename")
use를 쓰면 현재 namespace에서 지정한 namespace를 참조할 수 있도록 한다.
(use 'clojure.java.io)
(file "Filename") ; clojure.java.io/file 을 그냥 file 로 사용 가능
만약 clojure.java.io namespace에서 file만 참조하고 싶다면 :only 키워드를 사용할 수 있다.
(use '[clojure.java.io :only (file)])
(file "Filename")
:reload를 사용하면 라이브러리를 다시 읽을 수 있다고 한다. 라이브러리가 동적으로 변경되는 경우에 사용할 수 있을 것으로 보인다.
(use :reload '[clojure.java.io :only (file)])
리로드하는 라이브러리와 유관된 모든 라이브러리를 읽으려면 :reload-all을 사용하면 된다고 한다.8
(use :reload-all 'clojure.java.io)
namespace의 특성상 소스코드 파일의 최상단에 나오는 경우가 흔한 것 같다. 천천히 학습하며 추가해 보도록 한다.
동등비교
이 부분을 공부하기 위해 Clojure 공식 사이트의 [[/clojure/equality]] 문서를 번역해 보았다. 그러므로 이 문서에서는 몇 가지 메모만 남겨두자.
여기에서 기억해둬야 하는 함수는 넷이다. =, ==, hash, identical?.
=
Clojure의 =는 숫자와 Clojure collection을 제외하고 Java의 equals와 똑같이 작동한다..
Clojure의 =는 기본적으로 다음 경우에는 항상 true 이다.
- immutable 한 값을 비교할 때, 두 값이 같은 경우
- mutable 객체를 비교할 때, 두 객체가 같은 경우
하지만 그 외의 경우는 편의 제공을 위해 타입이 다른 Collection일 경우에도 내용물이 같다고 판단되면 true를 리턴한다.
이 때, 내용물의 비교는 =를 사용한다. =를 사용할 때에는 이걸 주의해야 할 것으로 보인다.
세부사항은 꽤 복잡하지만 일단 이정도로 기억해두자.
그렇다면 =는 숫자에 대해서 어떻게 작동할까?
Java의 모든 숫자 타입들의 equals를 읽어보면 타입에 엄격하다. 다음은 Long::equals의 소스코드이다. 타입이 다르면 ==로 검사하지도 않는다.
public boolean equals(Object obj) {
if (obj instanceof Long) {
return value == ((Long)obj).longValue();
}
return false;
}
하지만 Clojure는 =로 숫자를 비교할 때 Java와 달리 숫자의 카테고리와 값이 같으면 true를 리턴한다.
Clojure의 숫자 카테고리는 다음과 같다. (A, B, C는 내가 붙였다.)
- 카테고리 A: Java의 모든 정수 타입들(Byte, Short, Integer, Long, BigInteger), clojure.lang.BigInt, clojure.lang.Ratio라는 Java 타입으로 표현되는 비율.
- 카테고리 B: Float, Double
- 카테고리 C: BigDecimal
Java는 타입이 기준이고 Clojure는 카테고리가 기준인 것이다. 따라서 다음과 같은 차이가 발생한다.
- Java에서
((Long) 1L).equals((Integer) 1)은false이다. 타입이 다르기 때문이다. - Clojure에서
(= (int 1) (long 1))는true이다. int와 long의 카테고리가 같기 때문이다.
BigDecimal로 실험해보면 좀 더 흥미롭다.
Java의 BigDecimal은 1과 1.0이 equals하지 않은데, scale이 다르기 때문이다.
(new BigDecimal("1")).equals(new BigDecimal("1.0"))가 false를 리턴하는 과정을 디버거로 확인해 봤다.
scale 때문에 false를 리턴하는 것을 볼 수 있다.
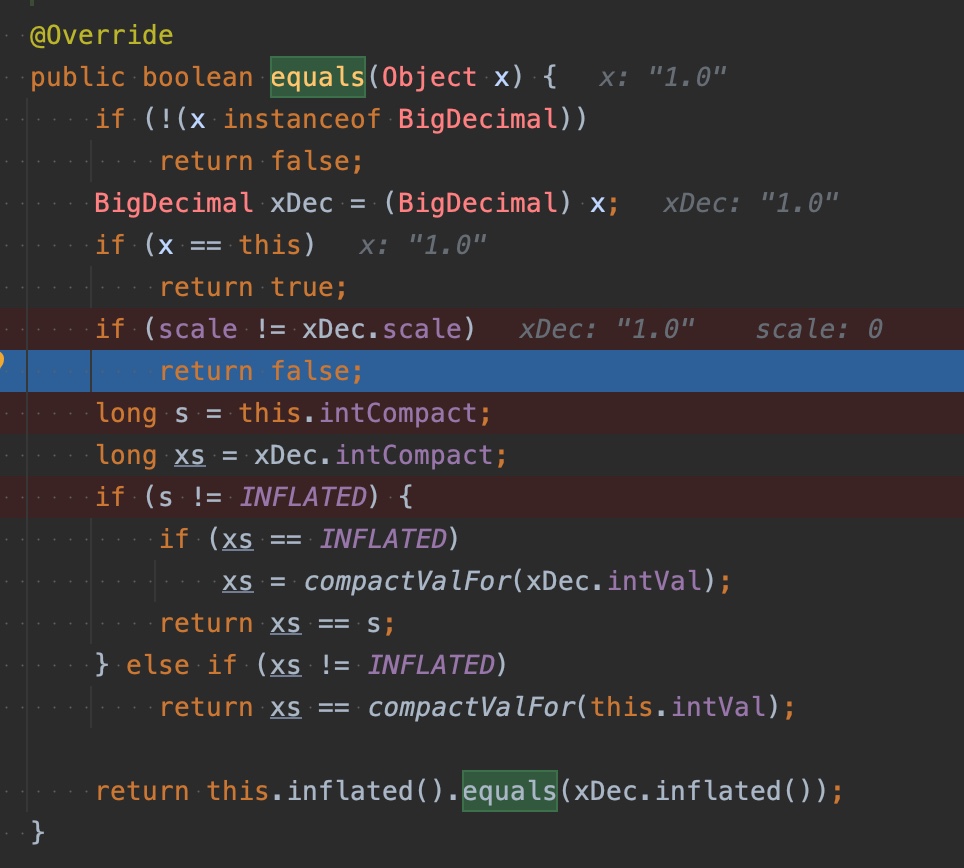
그러나 Clojure에서 (= 1M 1.0M)은 true이다.
==
한편 Clojure의 ==는 =와 다르다. ==는 카테고리를 넘나들며 숫자의 크기를 비교한다.
(= 0 0.0) ; false
(== 0 0.0) ; true
(= 1.0 1.0M) ; false
(== 1.0 1.0M) ; true
하지만 숫자 타입만 비교할 수 있다. 다음과 같이 문자열을 비교하려 하면 인자를 java.lang.Number 캐스팅하다 에러가 발생한다.
(== "123" "123")
Execution error (ClassCastException) at tutorial.core/eval1698 (form-init6027016705512429245.clj:1).
class java.lang.String cannot be cast to class java.lang.Number (java.lang.String and java.lang.Number are in module java.base of loader 'bootstrap')
identical?
identical? 함수는 Java의 ==와 똑같다.
richhickey의 "added identical?" commit을 읽어보면 identical?의 Java 코드는 다음과 같이 ==를 사용하고 있다.
public Object eval() throws Exception{
return expr1.eval() == expr2.eval() ?
RT.T : null;
}
==를 사용하므로 new String 테스트를 해볼 수 있을 것이다.
(== "123" (new String "123")) ; ClassCastException
(identical? "123" "123") ; true
(identical? "123" (new String "123")) ; false
(= "123" "123") ; true
(= "123" (new String "123")) ; true
예상대로 동작한다.
따라서 String 비교는 =를 사용하는 것이 바람직해 보인다.
NaN 문제
"같음"의 비교는 프로그래밍 언어별로 개념이 조금씩 다르므로 주의해야 한다. 다만 Clojure는 Java를 기반으로 하고 있으므로 Java의 스펙에 대한 지식이 도움이 될 거라 생각한다.
Java의 == 연산자는 Java Language Specification의 15.21 절에 등장한다.
해당 항목 중 중요한 몇 가지만 발췌해보자.
- 15.21 절
- 동등비교 연산자는 다음의 두 피연산자를 비교할 때 사용한다.
- numeric 타입으로 변환 가능한 두 피연산자
boolean또는Boolean타입의 두 피연산자- 레퍼런스 타입이거나 null 타입인 두 피연산자
- 그 외의 타입을 비교하려 하면 컴파일 에러가 발생한다.
- 동등비교 연산자는 언제나 boolean 타입으로 평가된다.
- 동등비교 연산자는 다음의 두 피연산자를 비교할 때 사용한다.
- 15.21.1 절
x가NaN이면x != x는true이다.
- 15.21.3 절
==의 결과는 피연산자 값이 둘 다null이거나 둘 다 같은 객체나 배열을 참조하면true이다. 그 외에는false이다.==가 String 타입의 참조를 비교할 때, 두 피연산자가 같은 String 객체를 참조하는지를 판별한다.- 두 피연산자가 같은 문자를 포함하더라도 다른 String 객체라면 결과는
false이다.
- 두 피연산자가 같은 문자를 포함하더라도 다른 String 객체라면 결과는
여기에서 주의깊게 기억해둬야 하는 것은 14.21.1 절의 NaN 비교이다.
IEEE 754에서는 NaN이 NaN을 포함해 어떤 것과도 같지 않다고 정의해놨으므로 NaN과 NaN을 !=으로 비교하면 true가 된다.
IEEE 754를 모른다면 다음 예제의 NaN 비교는 영문을 알 수 없는 정말 이상한 Java 코드로 보일 것이다.
// 기대한 대로 둘은 같다.
Float.NEGATIVE_INFINITY == Float.NEGATIVE_INFINITY; // true
// 느낌상 같아야 할 것 같은데 false가 나온다.
Float.NaN == Float.NaN; // false
여기에서 문제가 발생한다.
두 collection이 있는데 하나는 [1 1 NaN] 이고 다른 하나는 [1 1 NaN] 이다.
두 collection은 같은가 다른가?
Java 코드를 먼저 돌려보자. 다음 테스트 코드는 성공한다.
Set<Integer> seti1 = Set.of(1, 2);
Set<Integer> seti2 = Set.of(1, 2);
Assertions.assertTrue(seti1.equals(seti2));
Set<Double> set1 = Set.of(1.0, 2.0, Double.NaN);
Set<Double> set2 = Set.of(1.0, 2.0, Double.NaN);
Assertions.assertTrue(set1.equals(set2));
Assertions.assertTrue(set1.contains(Double.NaN));
이것이 성공하는 이유는 java의 Double에 구현된 equals가 NaN을 0x7ff8000000000000L로 변환해 비교하기 때문이다.
public static long doubleToLongBits(double value) {
if (!isNaN(value)) {
return doubleToRawLongBits(value);
}
return 0x7ff8000000000000L;
}
Double의 hashCode 또한 doubleToRawLongBits를 사용하고 있으므로 HashSet이나 HashMap에 NaN이 들어가도 별다른 문제가 없다.
public static int hashCode(double value) {
long bits = doubleToLongBits(value);
return (int)(bits ^ (bits >>> 32));
}
하지만 Clojure의 collection에 ##NaN이 들어가면 =은 기대한대로 작동하지 않는다.
(= [1 2 3] [1 2 3]) ; true
(= [1 2 ##NaN] [1 2 ##NaN]) ; false
##NaN을 제대로 비교하고 싶다면 =나 ==를 쓰면 안된다.
Java의 ==이나 equals를 사용해야 한다. 즉, identical이나 .equals를 쓰면 된다.
(= ##NaN ##NaN) ; false
(== ##NaN ##NaN) ; false
(identical? ##NaN ##NaN) ; true
(.equals ##NaN ##NaN) ; true
Clojure 공식 문서에서는 "=를 써서 true를 결과로 얻는 것이 필요한 경우에는 Clojure data structure에 ##NaN을 포함시키지 말 것"을 권장한다.
자세한 내용은 [[/clojure/equality]] 문서를 참고.
hash
Java에 hashCode 메소드가 있다면 Clojure에는 hash 함수가 있다.
주의해야 할 점은 Java의 collection과 Clojure 고유의 collection이 다른 해시값을 생산한다는 것이다.
ArrayList<Integer> a1 = new ArrayList<>(List.of(1, 2, 3));
LinkedList<Integer> a2 = new LinkedList<>(List.of(1, 2, 3));
Vector<Integer> v = new Vector<>(List.of(1, 2, 3));
System.out.println(a1.hashCode()); // 30817
System.out.println(a2.hashCode()); // 30817
System.out.println(v.hashCode()); // 30817
위의 코드를 보면 Java의 List 인터페이스 구현체들은 내용물이 모두 같으므로 해시값도 30817로 똑같다.
그러나 Clojure의 List들은 내용물이 같아도 Java collection과는 해시값이 다르다.
(hash (java.util.ArrayList. [1 2 3])) ; 30817
(hash (java.util.LinkedList. [1 2 3])) ; 30817
(hash (java.util.Vector. [1 2 3])) ; 30817
(hash '(1 2 3)) ; 736442005
(hash [1 2 3]) ; 736442005
따라서 Java의 collection을 Clojure 고유의 collection에 원소로 입력할 때에는 조심해야 한다.
(hash [1 2 [3 4 5]]) ; 952363223
(hash [1 2 '(3 4 5)]) ; 952363223
(hash [1 2 (java.util.ArrayList. [3 4 5])]) ; 911552362
(hash [1 2 (java.util.LinkedList. '(3 4 5))]) ; 911552362
(hash [1 2 (java.util.Vector. '(3 4 5))]) ; 911552362
Java collection이 들어가면 해시값이 달라지므로, 해시값을 통한 비교가 의도대로 되지 않을 수 있다.
metadata
collection이나 symbol에 메타데이터를 추가할 수 있다.
with-meta로 메타데이터를 추가하고 meta로 읽을 수 있다.
(def person {:name "John" :age 28})
(def person-2 (with-meta person {:serializable true}))
(meta person-2) ; {:serializable true}
특이한 점은 메타데이터가 비교에 영향을 주지 않는다는 것이다.
(= person person) ; true
(= person person-2) ; true
(identical? person person) ; true
(identical? person person-2) ; false ; 레퍼런스는 달라진다
(.equals person person) ; true
(.equals person person-2) ; true
Java 코드 호출
위에서 계속 사용하긴 했지만 이것도 이번에 기록해보자.
new는 두 가지 방법이 있다.
(new 클래스이름 인자)(클래스이름. 인자)
(new java.util.ArrayList [1 2 3]) ; [1 2 3]
(java.util.ArrayList. [1 2 3]) ; [1 2 3]
위의 두 코드는 new ArrayList(List.of(1, 2, 3))과 똑같다.
메소드 호출도 두 가지 방법이 있다.
(.메소드이름 객체 인자)(. 객체 메소드이름 인자)- Java에서 메소드를 호출할 때와 순서가 같아 비슷한 느낌으로 사용할 수 있다.
(def name "John Grib")
// name.equals("John Grib") 과 같음
(.equals name "John Grib") ; true
// name.equals("John Grib") 과 같음
(. name equals "John Grib") ; true
.. 연산자를 사용하면 .이 연쇄되는 Java 코드를 Clojure 코드로 작성할 수 있다.
// Java
System.getProperties().get("os.name")
아래의 세 코드는 같은 일을 한다. 쉬운 쪽을 고르자.
(. (. System (getProperties)) (get "os.name")) ; Linux
(.. System (getProperties) (get "os.name")) ; Linux
(-> (System/getProperties) (.get "os.name")) ; Linux
객체 하나에 대해 계속 메소드를 부를 일이 있다면 doto를 쓴다.
(doto (new java.util.HashMap)
(.put "a" 1)
(.put "b" 2))
; {a=1, b=2}
위의 코드는 아래의 Java 코드와 동일하다.
Map<String, Integer> map = new HashMap<>();
map.put("a", 1);
map.put("b", 2);
instanceof는 instance? 함수를 쓰면 된다.
(instance? String "") ; true
(instance? Comparable 10) ; true
try catch finally
다음은 clojuredocs.org의 예제를 복사해 온 것이다.
(try
(/ 1 0)
(catch ArithmeticException e (str "caught exception: " (.getMessage e)))
(finally (println "final exception.")))
참고문헌
- The Java® Language Specification Java SE 8 Edition
- 프로그래밍 클로저 / 스튜어트 할로웨이 저 / 유찬우 역 / 인사이트(insight) / 초판 1쇄 발행 2010년 06월 20일 / 원제 : Programming Clojure (2009)
주석
-
Common Lisp HyperSpec - Special Operator RETURN-FROM.
return-from은 스택을 거슬러 올라가는 작업을 멈춰줄 block을 지정해 주는 방식으로 사용하는 것 같다. ↩ -
Common Lisp HyperSpec - Macro RETURN. 이
return은 키워드가 아니라 매크로이며,nilblock에 대해 값을return하는 것으로 보인다. ↩ -
프로그래밍 클로저 2장. 50쪽. ↩
-
프로그래밍 클로저 1장. 2쪽. ↩
-
[[/clojure/reader]] 참고. ↩
-
프로그래밍 클로저 2장. 54쪽. ↩