Out of the Tar Pit
타르 구덩이에서 탈출하기
- 번역
- Abstract
- 1 Introduction
- 2 Complexity
- 3 Approaches to Understanding
- 4 Causes of Complexity
- 5 Classical approaches to managing complexity
- 6 Accidents and Essence
- 7 Recommended General Approach
- 8 The Relation Model
- 9 Functional Relational Programming
- 10 Example of an FRP system
- 11 Related Work
- 12 Conclusions
- References
- 주석
- 원문
- Out of the Tar Pit (PDF)
- Out of the Tar Pit (papers-we-love)
- Ben Moseley 와 Peter Marks의 2006년 2월 6일 논문.
번역
Abstract
초록
Complexity is the single major difficulty in the successful development of large-scale software systems. Following Brooks we distinguish accidental from essential difficulty, but disagree with his premise that most complexity remaining in contemporary systems is essential. We identify common causes of complexity and discuss general approaches which can be taken to eliminate them where they are accidental in nature. To make things more concrete we then give an outline for a potential complexity-minimizing approach based on functional programming and Codd’s relational model of data.
'복잡성'은 대규모 소프트웨어 시스템을 성공적으로 개발하는 데 있어 가장 큰 어려움입니다. 우리는 [[/people/fred-brooks]]{Brooks}가 제시한 우발적인 복잡성과 본질적인 복잡성을 구분하는 접근방법에는 동의하지만, 그가 주장하는 대로 현대 시스템에 남아있는 대부분의 복잡성이 본질적인 것이라는 주장에는 동의하지 않습니다. 우리는 복잡성의 주요 원인들을 파악하고, 그것들이 우연한 성격의 복잡성인 경우 제거할 수 있는 일반적인 접근 방식을 논의합니다. 그리고 더 구체적으로 설명하기 위해 함수형 프로그래밍과 Codd의 관계형 데이터 모델에 기반을 둔 복잡성을 최소화하는 잠재적인 접근법에 대한 개요를 제시합니다.
1 Introduction
1 서론
The "software crisis" was first identified in 1968 [NR69, p70] and in the intervening decades has deepened rather than abated. The biggest problem in the development and maintenance of large-scale software systems is complexity — large systems are hard to understand. We believe that the major contributor to this complexity in many systems is the handling of state and the burden that this adds when trying to analyse and reason about the system. Other closely related contributors are code volume, and explicit concern with the flow of control through the system.
"소프트웨어 위기"론은 1968년에 처음으로 등장했습니다. 그 이후 수십 년, 소프트웨어의 위기는 더 심각해졌으며 해결되지 못했습니다. 대규모 소프트웨어 시스템의 개발 및 유지 관리에서 가장 큰 문제는 복잡성입니다(시스템이 클수록 이해하기 어렵습니다). 우리는 많은 시스템에서 이 복잡성의 주요 원인이 '상태의 처리'와 이것이 시스템을 분석하고 이해하는 데 부과하는 부담이라고 믿습니다. 코드의 양과 시스템을 통한 제어 흐름에 대한 명확한 고려 등이 밀접하게 관련된 기여자들입니다.
The classical ways to approach the difficulty of state include object-oriented programming which tightly couples state together with related behaviour, and functional programming which — in its pure form — eschews state and side-effects all together. These approaches each suffer from various (and differing) problems when applied to traditional large-scale systems.
상태의 어려움에 접근하는 고전적인 방법은 주로 두 가지입니다. 하나는 상태를 관련된 동작과 밀접하게 결합시키는 객체지향 프로그래밍이고, 다른 하나는 순수한 형식을 통해 상태와 사이드 이펙트를 모두 배제하는 함수형 프로그래밍입니다.
이런 접근법들은 각각 전통적인 대규모 시스템에 적용할 때 각각 다양하고 서로 다른 문제들을 겪게 됩니다.
We argue that it is possible to take useful ideas from both and that — when combined with some ideas from the relational database world — this approach offers significant potential for simplifying the construction of large-scale software systems.
우리는 두 가지 접근법 모두 우리에게 유용한 아이디어를 제공해 주며, 관계형 데이터베이스의 일부 아이디어와 결합하면 이런 접근법이 대규모 소프트웨어 시스템 구축을 단순화하는 데 상당한 잠재력을 발휘하게 될 것이라고 생각합니다.
The paper is divided into two halves. In the first half we focus on complexity. In section 2 we look at complexity in general and justify our assertion that it is at the root of the crisis, then we look at how we currently attempt to understand systems in section 3. In section 4 we look at the causes of complexity (i.e. things which make understanding difficult) before discussing the classical approaches to managing these complexity causes in section 5. In section 6 we define what we mean by “accidental” and “essential” and then in section 7 we give recommendations for alternative ways of addressing the causes of complexity — with an emphasis on avoidance of the problems rather than coping with them.
In the second half of the paper we consider in more detail a possible approach that follows our recommended strategy. We start with a review of the relational model in section 8 and give an overview of the potential approach in section 9. In section 10 we give a brief example of how the approach might be used.
Finally we contrast our approach with others in section 11 and then give conclusions in section 12.
이 논문은 크게 두 부분으로 나눌 수 있습니다.
- 전반부는 복잡성에 초점을 맞춥니다.
- 제2장에서는 일반적인 복잡성을 살펴보고, 이것이 위기의 근본적인 원인이라는 주장을 정당화한 다음,
- 제3장에서 우리가 시스템을 이해하려고 시도하는 현재의 방법들을 살펴봅니다.
- 제4장에서는 복잡성의 원인(이해를 어렵게 만드는 것들)을 살펴본 다음,
- 제5장에서 이런 복잡성의 원인이 되는 것들을 관리하기 위한 고전적인 접근 방식을 논의합니다.
- 제6장에서는 "우발적인"과 "본질적인"이라는 용어를 정의한 다음,
- 제7장에서 복잡성의 원인을 해결하는 대안적인 접근 방식을 제시합니다. 이때, 문제를 해결하는 것보다는 문제를 피하는 것에 중점을 둡니다.
- 논문의 후반부에서는 우리가 권장하는 전략을 따르는 가능한 접근 방식을 더 자세히 살펴봅니다.
- 제8장에서는 관계형 모델에 대한 검토를 시작하고,
- 제9장에서 잠재적인 접근 방식에 대한 개요를 제시합니다.
- 제10장에서는 이런 접근 방식이 어떻게 사용될 수 있는지에 대한 간단한 예를 들어봅니다.
- 마지막으로, 제11장에서는 우리의 접근 방식을 다른 접근 방식과 대조하고,
- 제12장에서 결론을 내립니다.
2 Complexity
In his classic paper — "No Silver Bullet" Brooks[Bro86] identified four properties of software systems which make building software hard: Complexity, Conformity, Changeability and Invisibility. Of these we believe that Complexity is the only significant one — the others can either be classified as forms of complexity, or be seen as problematic solely because of the complexity in the system.
[[/people/fred-brooks]]{프레드 브룩스}는 그의 고전이 된 논문인 "은총알은 없다"에서 소프트웨어 구축을 어렵게 만드는 소프트웨어 시스템의 네 가지 특성을 규명했습니다. 그것은 바로 '복잡성', '적합성', '변경 가능성', '비가시성'입니다.
우리는 이들 중 복잡성만이 유일하게 중요하다고 생각하며, 다른 세 가지는 복잡성의 한 형태로 분류되거나, 시스템의 복잡성 때문에 문제가 되는 것으로 봅니다.
Complexity is the root cause of the vast majority of problems with software today. Unreliability, late delivery, lack of security — often even poor performance in large-scale systems can all be seen as deriving ultimately from unmanageable complexity. The primary status of complexity as the major cause of these other problems comes simply from the fact that being able to understand a system is a prerequisite for avoiding all of them, and of course it is this which complexity destroys.
복잡성은 오늘날 소프트웨어와 관련된 대부분의 문제의 근본 원인이라 할 수 있습니다. 불안정성, 지연된 일정, 부족한 보안, 심지어 대규모 시스템의 성능 저하까지 모두 따지고 보면 복잡성을 관리하기 어렵다는 것에서 비롯된 것으로 볼 수 있습니다.
복잡성이 이렇게 다른 다양한 문제들의 주요 원인이 되는 이유는, 단순히 시스템을 일단 이해할 수 있어야 모든 가능한 문제를 피해낼 수 있다는 사실에서 비롯되는 것입니다. 그리고 복잡성이 파괴하는 것은 바로 그러한 '시스템을 이해하는 능력'입니다.
The relevance of complexity is widely recognised. As Dijkstra said [Dij97, EWD1243]:
"…we have to keep it crisp, disentangled, and simple if we refuse to be crushed by the complexities of our own making…"
…and the Economist devoted a whole article to software complexity [Eco04] — noting that by some estimates software problems cost the American economy $59 billion annually.
복잡성의 중요성은 널리 인식된 것이기도 합니다. Dijkstra가 말한 바와 같이,
"만약 우리가 자신이 만든 복잡성에 짓눌리고 싶지 않다면, 우리는 그것을 선명하게, 엉키지 않게, 그리고 단순하게 유지해야 합니다."
…그리고 Economist지는 소프트웨어 복잡성을 주제로 전체 기사를 할애하기도 했는데, 해당 기사에서는 소프트웨어 문제로 미국 경제가 연간 약 590억 달러의 손실을 보고 있다는 추정값에 주목했습니다.
Being able to think and reason about our systems (particularly the effects of changes to those systems) is of crucial importance. The dangers of complexity and the importance of simplicity in this regard have also been a popular topic in ACM Turing award lectures. In his 1990 lecture Corbato said [Cor91]:
"The general problem with ambitious systems is complexity.", "…it is important to emphasize the value of simplicity and elegance, for complexity has a way of compounding difficulties"
시스템에 대해 생각하고, 특히 그 시스템에 변화가 생길 경우 그 영향에 대해 추론할 수 있는 능력은 매우 중요합니다. 복잡성이 얼마나 위험하고 단순함이 얼마나 중요한지는 ACM Turing award 강연에서도 인기 있는 주제였습니다. Corbato는 1990년 튜링상 수상 강연에서 다음과 같이 말했습니다.
- "야심차게 만든 시스템에서 일반적으로 발생하는 문제는 복잡성입니다."
- "…단순함과 우아함의 가치를 강조하는 것이 중요합니다. 왜냐하면 복잡성은 어려움을 복리적으로 증가시키는 경향이 있기 때문입니다."
In 1977 Backus [Bac78] talked about the "complexities and weaknesses" of traditional languages and noted:
"there is a desperate need for a powerful methodology to help us think about programs. … conventional languages create unnecessary confusion in the way we think about programs"
그리고 1997년, Backus도 튜링상 수상 강연에서 전통적인 언어들의 "복잡성과 약점"을 언급하며 다음과 같이 이야기했습니다.
"프로그램에 대해 생각하는 데 도움이 되는 강력한 방법론이 절실하게 필요합니다. … 기존의 언어들은 우리가 프로그램을 생각하는 방식에 오히려 불필요한 혼란을 일으킵니다."
Finally, in his Turing award speech in 1980 Hoare [Hoa81] observed:
"…there is one quality that cannot be purchased… — and that is reliability. The price of reliability is the pursuit of the utmost simplicity"
and
"I conclude that there are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies and the other way is to make it so complicated that there are no obvious deficiencies. The first method is far more difficult."
마지막으로, 1980년 튜링상 수상 강연에서 Hoare는 다음과 같이 말했습니다.
"…돈으로도 얻을 수 없는 하나의 품질이 있습니다… 그것은 신뢰성입니다. 신뢰성의 대가는 극도의 단순함을 추구하는 것입니다."
그리고
"나는 소프트웨어를 설계하는 방법에는 두 가지가 있다고 결론내렸습니다. 한 가지 방법은 결함이 없다는 것이 명백한 정도로 단순하게 만드는 것이고, 다른 한 가지 방법은 결함이 없다는 것이 명백한 정도로 복잡하게 만드는 것입니다. 그리고 첫 번째 방법이 훨씬 더 어렵습니다."
This is the unfortunate truth:
Simplicity is Hard
…but the purpose of this paper is to give some cause for optimism.
불행히도 이것이 진실입니다.
단순함은 달성하기 어렵다.
…하지만 이 논문의 목적은 긍정적으로 볼 수 있는 근거를 제시하는 것입니다.
One final point is that the type of complexity we are discussing in this paper is that which makes large systems hard to understand. It is this that causes us to expend huge resources in creating and maintaining such systems. This type of complexity has nothing to do with complexity theory — the branch of computer science which studies the resources consumed by a machine executing a program. The two are completely unrelated — it is a straightforward matter to write a small program in a few lines which is incredibly simple (in our sense) and yet is of the highest complexity class (in the complexity theory sense). From this point on we shall only discuss complexity of the first kind.
We shall look at what we consider to be the major common causes of complexity (things which make understanding difficult) after first discussing exactly how we normally attempt to understand systems.
마지막으로 이 논문에서 논의하는 종류의 복잡성은, '대규모 시스템을 이해하기 어렵게 만드는 종류의 복잡성'을 말한다는 것입니다. '이런 종류의 복잡성' 때문에 우리는 시스템을 만들고 유지보수하는 데에 막대한 자원을 소모하게 됩니다. 프로그램을 실행하는 기계가 소비하는 리소스를 연구하는 컴퓨터 과학의 한 분야인 '복잡성 이론'과 '이런 종류의 복잡성'은 아무런 관련이 없습니다. 몇 줄로 된 작은 프로그램은 우리가 보기에는 매우 간단한 것이지만, 복잡성 이론의 관점에서 보면 가장 높은 복잡성 유형에 속하는 문제인 것입니다.
이제부터 우리는 첫 번째 종류의 복잡성에 대해서만 논의하겠습니다.
우리는 일단 시스템을 이해하려고 할 때 보통 어떤 방식으로 노력하는지에 대해 정확히 논의한 후, 이해를 어렵게 만드는 복잡성의 주요한 공통적인 원인들에 대해 살펴보려 합니다.
3 Approaches to Understanding
시스템을 이해하려 할 때의 접근 방식들
We argued above that the danger of complexity came from its impact on our attempts to understand a system. Because of this, it is helpful to consider the mechanisms that are commonly used to try to understand systems. We can then later consider the impact that potential causes of complexity have on these approaches. There are two widely-used approaches to understanding systems (or components of systems):
Testing This is attempting to understand a system from the outside — as a "black box". Conclusions about the system are drawn on the basis of observations about how it behaves in certain specific situations. Testing may be performed either by human or by machine. The former is more common for whole-system testing, the latter more common for individual component testing.
Informal Reasoning This is attempting to understand the system by examining it from the inside. The hope is that by using the extra information available, a more accurate understanding can be gained.
앞에서 우리는 '시스템을 이해하기 어렵게 만든다'는 지점에서 복잡성이 위험하다고 주장했습니다. 따라서, 시스템을 이해하려 할 때 일반적으로 사용되곤 하는 메커니즘을 살펴보는 것이 도움이 될 것입니다. 그리고 나서 복잡성의 잠재적 원인이 이러한 접근 방식에 미치는 영향을 나중에 고려할 수 있을 것입니다. 시스템, 또는 시스템을 구성하는 컴포넌트들을 이해하려 할 때 널리 사용되는 두 가지 접근 방식은 다음과 같습니다.
테스팅
이 방법은 시스템을 '블랙박스'처럼 외부의 관점에서 이해하려 시도하는 것입니다. 따라서 특정한 상황에서 시스템이 어떻게 동작하는지에 대한 관찰을 바탕으로 시스템에 대한 결론을 도출합니다. 이러한 테스트는 사람 또는 머신에 의해 수행될 수 있습니다. 전자는 전체 시스템 테스트에 더 많이 사용되고, 후자는 개별 컴포넌트 테스트에 더 많이 사용됩니다.
비형식적 추론
이 방법은 시스템을 내부에서 살펴보면서 이해하려는 것입니다. 가용한 추가적인 정보를 사용하여 보다 정확한 이해를 얻기를 바라는 활동입니다.
Of the two informal reasoning is the most important by far. This is because — as we shall see below — there are inherent limits to what can be achieved by testing, and because informal reasoning (by virtue of being an inherent part of the development process) is always used. The other justification is that improvements in informal reasoning will lead to less errors being created whilst all that improvements in testing can do is to lead to more errors being detected. As Dijkstra said in his Turing award speech [Dij72, EWD340]:
"Those who want really reliable software will discover that they must find means of avoiding the majority of bugs to start with."
and as O’Keefe (who also stressed the importance of “understanding your problem” and that “Elegance is not optional”) said [O’K90]:
“Our response to mistakes should be to look for ways that we can avoid making them, not to blame the nature of things.”
이들 중 '비형식적 추론'이 훨씬 중요합니다. 아래에서 살펴보겠지만, 테스팅을 통해 얻을 수 있는 것에는 본질적인 한계가 있는 반면, '비형식적 추론'은 개발 프로세스의 본질적인 부분이므로 항상 사용되고 있기 때문입니다. 그리고 비형식적 추론이 개선되면 오류가 더 적게 발생하게 되지만, 테스팅은 개선한다 해도 더 많은 오류를 찾아낼 수 있을 뿐입니다. Dijkstra는 튜링상 수상 강연에서 다음과 같이 말한 바 있습니다.
"정말 신뢰할 수 있는 소프트웨어를 원하는 사람들은, 처음부터 대부분의 버그를 피할 수 있는 방법을 찾아야 한다는 것을 깨닫게 될 것입니다."
그리고 ("문제를 이해하는 것"의 중요성과 "우아함은 선택 사항이 아니다"라는 것을 강조한) O'Keefe는 다음과 같이 말했습니다.
"실수에 대한 우리의 대응은, 사물의 본질을 탓하는 것이 아니라 실수를 저지르지 않을 방법을 찾는 것이어야 합니다."
The key problem with testing is that a test (of any kind) that uses one particular set of inputs tells you nothing at all about the behaviour of the system or component when it is given a different set of inputs. The huge number of different possible inputs usually rules out the possibility of testing them all, hence the unavoidable concern with testing will always be — have you performed the right tests?. The only certain answer you will ever get to this question is an answer in the negative — when the system breaks. Again, as Dijkstra observed [Dij71, EWD303]:
“testing is hopelessly inadequate….(it) can be used very effectively to show the presence of bugs but never to show their absence.”
We agree with Dijkstra. Rely on testing at your peril.
테스팅의 중요한 문제점은 (어떤 종류가 되었건 간에) 특정 입력 세트를 사용하는 테스트는, 다른 입력 세트가 주어졌을 때 시스템 또는 컴포넌트의 동작에 대해 전혀 알려주지 않는다는 것입니다.
가능한 입력의 경우의 수가 너무 많기 때문에 일반적으로 모든 입력을 테스트하는 것은 불가능합니다. 따라서 테스트에 대한 피할 수 없는 고민은 항상 '올바른 테스트를 수행했는가?'가 될 수 밖에 없습니다. 이 질문에 대한 유일하고 확실한 답은 바로, 시스템에 고장이 났을 때 발생하는 부정적인 결과를 확인하는 것입니다. 다시 Dijkstra를 인용해보겠습니다.
"테스트는 절망적으로 부적절하다… (테스트는) 버그의 존재를 보여주는 데는 매우 효과적으로 사용될 수 있지만 버그가 없다는 것을 보여주는 데에는 결코 사용될 수 없다."
우리도 Dijkstra의 말에 동의합니다. 테스팅에 과도하게 의존하면 위험합니다.
This is not to say that testing has no use. The bottom line is that all ways of attempting to understand a system have their limitations (and this includes both informal reasoning — which is limited in scope, imprecise and hence prone to error — as well as formal reasoning — which is dependent upon the accuracy of a specification). Because of these limitations it may often be prudent to employ both testing and reasoning together.
It is precisely because of the limitations of all these approaches that simplicity is vital. When considered next to testing and reasoning, simplicity is more important than either. Given a stark choice between investment in testing and investment in simplicity, the latter may often be the better choice because it will facilitate all future attempts to understand the system — attempts of any kind.
이것은 테스팅이 무의미하다는 말이 아닙니다. 시스템을 이해하려는 모든 방법에는 한계가 있다는 것이 핵심입니다. (여기에는 범위가 제한적이고 부정확해서 오류가 발생하기 쉬운 '비형식적 추론'과, 스펙의 정확성에 의존하는 '형식적 추론'이 모두 포함됩니다.) 이러한 한계로 인해 테스팅과 추론을 함께 사용하는 것이 현명한 선택일 수 있습니다.
이러한 모든 접근 방법들에 한계가 있기 때문에, 단순성이 매우 중요합니다. 테스팅, 그리고 추론과 동등하게 놓고 고려해 봤을 때, 단순성은 이들 중 어느 것보다 더 중요합니다. 테스팅에 대한 투자와 단순성에 대한 투자 사이에서 강력한 선택을 해야 하는 상황이라면, 단순성에 대한 투자가 더 나은 선택일 수 있습니다. 왜냐하면 단순성은 '어떠한 방식으로든 시스템을 이해하려 하는 모든 미래의 시도'들을 용이하게 만들어주기 때문입니다.
4 Causes of Complexity
복잡성의 원인
In any non-trivial system there is some complexity inherent in the problem that needs to be solved. In real large systems however, we regularly encounter complexity whose status as “inherent in the problem” is open to some doubt. We now consider some of these causes of complexity.
사소하지 않은 모든 시스템에서는 해결해야 하는 문제 자체에 복잡성이 내재되어 있습니다. 그러나 실제의 대규모 시스템에서 마주하게 되는 복잡성들은 '문제에 내재된'것인지 아닌지 구별하기 어려운 경우가 자주 있습니다. 이제 이러한 복잡성의 원인들 중 몇 가지를 살펴보겠습니다.
4.1 Complexity caused by State
Anyone who has ever telephoned a support desk for a software system and been told to “try it again”, or “reload the document”, or “restart the program”, or “reboot your computer” or “re-install the program” or even “re-install the operating system and then the program” has direct experience of the problems that state1 causes for writing reliable, understandable software.
The reason these quotes will sound familiar to many people is that they are often suggested because they are often successful in resolving the problem. The reason that they are often successful in resolving the problem is that many systems have errors in their handling of state. The reason that many of these errors exist is that the presence of state makes programs hard to understand. It makes them complex.
누구든지 소프트웨어 시스템 서비스 센터에 전화를 걸었을 때 "다시 시도해 보세요", "문서 파일을 다시 로드해보세요", "프로그램을 재시작하세요", "컴퓨터를 재부팅하세요", "프로그램을 재설치하세요", 심지어 "운영체제를 다시 설치한 다음, 프로그램을 재설치하세요" 같은 말들을 들어본 사람이라면, 신뢰할 수 있고 이해하기 쉬운 소프트웨어를 작성하는 데 '상태'1가 일으키는 문제를 직접 경험한 적이 있는 셈입니다.
고객센터 전화통화에서 듣는 이런 말들이 많은 사람들에게 친숙하게 들리는 이유는, 문제를 해결하는 데 성공하는 경우가 많은 편이기 때문입니다. 그리고 이런 방법들이 종종 문제를 해결하는 데 성공하는 이유는, 많은 시스템들이 '상태'를 처리하는 데 오류가 있기 때문입니다. 이러한 오류가 많이 발생하는 이유는 상태의 존재가 프로그램을 이해하기 어렵게 만들기 때문입니다. 상태는 프로그램을 복잡하게 만듭니다.
When it comes to state, we are in broad agreement with Brooks’ sentiment when he says [Bro86]:
“From the complexity comes the difficulty of enumerating, much less understanding, all the possible states of the program, and from that comes the unreliability”
— we agree with this, but believe that it is the presence of many possible states which gives rise to the complexity in the first place, and:
“computers. . . have very large numbers of states. This makes conceiving, describing, and testing them hard. Software systems have orders-of-magnitude more states than computers do.”
상태에 대해 [[/people/fred-brooks]]{Fred Brooks}가 다음과 같이 말한 것에 대해 우리는 폭넓게 동의합니다.
"복잡성으로 인해, 프로그램의 모든 가능한 상태를 열거하는 것이 어려워지며, 이를 이해하는 것도 더욱 어려워지고, 그로 인해 결국 신뢰성이 떨어지게 됩니다."
이에 동의하긴 하지만, 우리는 애초에 가능한 상태가 많다는 것 자체가 복잡성을 야기한다고 믿습니다.
"컴퓨터는 매우 많은 수의 상태를 갖고 있습니다. 따라서 상태를 구상하고, 설명하고, 테스트하기란 어렵습니다. 소프트웨어 시스템은 컴퓨터보다 훨씬 더 많은 상태를 갖고 있습니다."
4.1.1 Impact of State on Testing
상태가 테스트에 미치는 영향
The severity of the impact of state on testing noted by Brooks is hard to over-emphasise. State affects all types of testing — from system-level testing (where the tester will be at the mercy of the same problems as the hapless user just mentioned) through to component-level or unit testing. The key problem is that a test (of any kind) on a system or component that is in one particular state tells you nothing at all about the behaviour of that system or component when it happens to be in another state.
[[/people/fred-brooks]]{Brooks}가 언급한 상태가 테스트에 미치는 영향의 심각성은 아무리 강조해도 지나치지 않습니다. 상태는 시스템 수준 테스트(테스터가 방금 언급한 불행한 사용자와 같은 문제를 겪게 될 것입니다)에서부터 컴포넌트 수준 테스트, 단위 테스트에 이르기까지 모든 유형의 테스트에 영향을 미칩니다. 핵심적인 문제는 특정 상태에 있는 시스템이나 컴포넌트에 대한 테스트(모든 종류의 테스트)가 해당 시스템이나 컴포넌트가 '다른 상태일 때의 동작'에 대해 전혀 알려주지 않는다는 것입니다.
The common approach to testing a stateful system (either at the component or system levels) is to start it up such that it is in some kind of “clean” or “initial” (albeit mostly hidden) state, perform the desired tests using the test inputs and then rely upon the (often in the case of bugs ill-founded) assumption that the system would perform the same way — regardless of its hidden internal state — every time the test is run with those inputs.
상태기반 시스템(컴포넌트 또는 시스템 레벨에서)을 테스트하는 일반적인 접근방법은,
- 시스템이 '깨끗'하거나 '초기' 상태가 되도록 시작하고(초기 상태라 해도 대부분의 상태값은 숨겨져 있다),
- 테스트 입력을 사용하여 원하는 테스트를 수행한 다음,
- 해당 입력으로 테스트를 실행할 때마다 시스템이 숨겨진 내부 상태와 관계 없이 똑같은 방식으로 작동할 거라는 가정(종종 원인을 알 수 없는 버그가 나온다)에 의존하는 것입니다.
In essence, this approach is simply sweeping the problem of state under the carpet. The reasons that this is done are firstly because it is often possible to get away with this approach and more crucially because there isn’t really any alternative when you’re testing a stateful system with a complicated internal hidden state.
이 접근방법은 본질적으로 '상태 문제'를 바닥 청소를 하지 않고 카펫 밑으로 쑤셔넣는 것에 불과합니다. 이렇게 하는 이유는,
- 첫째, 이 접근법을 통해 문제를 피할 수 있는 경우가 많기 때문이고,
- 둘쟤, 결정적으로 더 복잡한 '내부적으로 숨겨진 상태'가 있는 상태기반 시스템을 테스트할 때는 실제로 별다른 대안이 없기 때문입니다.
The difficulty of course is that it’s not always possible to “get away with it” — if some sequence of events (inputs) can cause the system to “get into a bad state” (specifically an internal hidden state which was different from the one in which the test was performed) then things can and do go wrong. This is what is happening to the hypothetical support-desk caller discussed at the beginning of this section. The proposed remedies are all attempts to force the system back into a “good internal state”.
물론, 어떤 연속된 이벤트(입력)들로 인해 시스템이 "나쁜 상태"로 빠질 수 있다면(특히 테스트해본 상태와 다른, 내부의 숨겨진 상태로), 상황이 실제로 잘못될 수 있다는 점이 어렵습니다.
이 장의 시작 부분에서 설명한 가상의 고객센터로 전화를 건 발신자에게는 이런 일이 발생하고 있는 것입니다. 그 고객에게 제안된 해결 방법은 모두, 시스템을 "좋은 내부 상태"로 되돌리려는 시도였습니다.
This problem (that a test in one state tells you nothing at all about the system in a different state) is a direct parallel to one of the fundamental problems with testing discussed above — namely that testing for one set of inputs tells you nothing at all about the behaviour with a different set of inputs. In fact the problem caused by state is typically worse — particularly when testing large chunks of a system — simply because even though the number of possible inputs may be very large, the number of possible states the system can be in is often even larger.
이 문제(하나의 상태를 토대로 한 테스트가 다른 상태의 시스템에 대해 전혀 알려주지 않는다는 점)는 위에서 설명한 테스팅의 근본적인 문제 중 하나, 즉 '하나의 입력 세트에 대한 테스트'가 '다른 입력 세트의 동작에 대해 전혀 알려주지 않는다'는 문제와 직접적으로 유사합니다.
사실 상태로 인한 문제는 일반적으로 특히 시스템의 큰 덩어리를 테스트하는 경우일수록 더 심각합니다. 가능한 입력의 수도 매우 많을 수 있지만, 시스템이 가질 수 있는 가능한 상태의 수가 그보다 훨씬 더 많은 경우가 많기 때문입니다.
These two similar problems — one intrinsic to testing, the other coming from state — combine together horribly. Each introduces a huge amount of uncertainty, and we are left with very little about which we can be certain if the system/component under scrutiny is of a stateful nature.
이 두 가지의 유사한 문제(하나는 테스트에 내재된 문제, 다른 하나는 상태에서 비롯된 문제)는 끔찍할 정도로 결합되어 있습니다. 이 문제들 각각은 엄청난 불확실성을 야기하며, 조사 대상인 시스템/컴포넌트가 상태의 성격을 띄고 있는지를 확신할 수 있는 방법도 거의 없습니다.
4.1.2 Impact of State on Informal Reasoning
상태가 비형식적 추론에 미치는 영향
In addition to causing problems for understanding a system from the outside, state also hinders the developer who must attempt to reason (most commonly on an informal basis) about the expected behaviour of the system “from the inside”.
상태는 외부에서 시스템을 이해하는 데 문제를 일으킬 뿐만 아니라, '내부에서' 시스템의 예상 동작을 추론(일반적으로 비형식적인 추론 기반)해야 하는 개발자에게도 방해가 됩니다.
The mental processes which are used to do this informal reasoning often revolve around a case-by-case mental simulation of behaviour: “if this variable is in this state, then this will happen — which is correct — otherwise that will happen — which is also correct”. As the number of states — and hence the number of possible scenarios that must be considered — grows, the effectiveness of this mental approach buckles almost as quickly as testing (it does achieve some advantage through abstraction over sets of similar values which can be seen to be treated identically).
이러한 비형식적 추론에 동원되는 정신적 프로세스는 종종 동작 사례에 대한 정신적인 시뮬레이션을 중심으로 이루어집니다. "만약에 이 변수가 이런 상태에 있다면, 이런 일이 일어나겠지. 음 이건 맞고, 그렇지 않으면 저런 일이 일어나겠지. 음 이것도 맞고." 이런 식으로 말이죠.
상태의 수와 고려해야 하는 가능한 시나리오들의 수가 증가함에 따라, 이런 정신적인 접근 방식의 효율성은 테스팅만큼이나 빠르게 떨어져버립니다. (다만 테스팅은 동일하게 취급되는 것으로 볼 수 있는 유사한 값 집합에 비해서는 추상화를 통해 꽤나 이득을 얻을 수 있습니다.)
One of the issues (that affects both testing and reasoning) is the exponential rate at which the number of possible states grows — for every single bit of state that we add we double the total number of possible states. Another issue — which is a particular problem for informal reasoning — is contamination.
테스팅과 추론 모두에 영향을 미치는 문제 중 하나는, 가능한 상태의 수가 기하급수적으로 증가한다는 것입니다. 상태를 하나 추가할 때마다 가능한 상태의 총 수가 두 배로 늘어납니다. 그리고 비형식적 추론에서 특히 문제가 되는 또 다른 문제는 오염(contamination)입니다.
Consider a system to be made up of procedures, some of which are stateful and others which aren’t. We have already discussed the difficulties of understanding the bits which are stateful, but what we would hope is that the procedures which aren’t themselves stateful would be more easy to comprehend. Alas, this is largely not the case. If the procedure in question (which is itself stateless) makes use of any other procedure which is stateful — even indirectly — then all bets are off, our procedure becomes contaminated and we can only understand it in the context of state. If we try to do anything else we will again run the risk of all the classic state-derived problems discussed above. As has been said, the problem with state is that “when you let the nose of the camel into the tent, the rest of him tends to follow”.
어떤 시스템 하나가 프로시저들로 만들어져 있는데, 그 프로시저 중 몇몇은 상태 기반이고 나머지는 그렇지 않다고 가정해 봅시다. 우리는 이미 상태 기반 비트를 이해하는 것에 대한 어려움을 이야기한 바 있습니다. 따라서 상태 기반이 아닌 프로시저는 이해하기 쉬우면 좋겠지만, 아쉽게도 그렇지 않습니다.
만약 문제의 프로시저(stateless)가 '간접적으로라도' 상태 기반의 다른 프로시저를 사용한다면, 이 프로시저도 오염이 되어 '상태의 문맥'에서만 이해할 수 있게 되어버립니다. 그리고 그 외의 다른 작업을 시도한다 해도 위에서 언급한 전형적인 상태 기반 문제들을 다시 한 번 마주하게 될 위험이 있습니다. 앞에서 말했듯이, 상태의 문제는 "낙타의 코를 텐트 안으로 들여보내면, 낙타의 나머지 몸뚱이도 코를 따라가는 경향이 있다" 는 말과 비슷합니다.
As a result of all the above reasons it is our belief that the single biggest remaining cause of complexity in most contemporary large systems is state, and the more we can do to limit and manage state, the better.
위의 모든 이유로 인해, 대부분의 현대적인 대규모 시스템에서 복잡성을 유발하는 가장 큰 원인은 상태이며, 상태를 제한하고 관리하기 위해 할 수 있는 일이 많을수록 더 좋다고 생각합니다.
4.2 Complexity caused by Control
제어로 인한 복잡성
Control is basically about the order in which things happen.
'제어'는 기본적으로 일이 진행되는 순서에 대한 것입니다.
The problem with control is that very often we do not want to have to be concerned with this. Obviously — given that we want to construct a real system in which things will actually happen — at some point order is going to be relevant to someone, but there are significant risks in concerning ourselves with this issue unnecessarily.
제어의 문제점은 우리가 이 문제에 대해 신경쓰고 싶지 않은 경우가 많다는 것입니다. 물론, '실제로 뭔가 일이 일어나는 시스템'을 구축하고자 한다면 순서 문제는 언젠가는 중요해질 것입니다. 그러나 이 문제에 불필요하게 신경을 쓰는 것은 상당한 위험이 따르는 일입니다.
Most traditional programming languages do force a concern with ordering — most often the ordering in which things will happen is controlled by the order in which the statements of the programming language are written in the textual form of the program. This order is then modified by explicit branching instructions (possibly with conditions attached), and subroutines are normally provided which will be invoked in an implicit stack.
대부분의 전통적인 프로그래밍 언어는 '순서'에 대한 고려를 필요로 합니다. 주로 프로그래밍 언어의 명령문이 프로그램의 텍스트 형식으로 작성된 순서가 실행될 일들의 순서를 결정하는 방식입니다. 이렇게 결정된 순서는 명시적인 제어 분기 명령어를 통해 변경될 수 있고, 이런 분기 명령에는 분기를 위한 조건이 붙을 수 있으며, 일반적으로 암묵적 스택에서 호출되는 서브루틴이 제공됩니다.
Of course a variety of evaluation orders is possible, but there is little variation in this regard amongst widespread languages.
물론 평가 순서는 다양한 방식으로도 가능하지만, 널리 사용되는 프로그래밍 언어들 사이에서는 큰 차이가 없습니다.
The difficulty is that when control is an implicit part of the language (as it almost always is), then every single piece of program must be understood in that context — even when (as is often the case) the programmer may wish to say nothing about this. When a programmer is forced (through use of a language with implicit control flow) to specify the control, he or she is being forced to specify an aspect of how the system should work rather than simply what is desired. Effectively they are being forced to over-specify the problem. Consider the simple pseudo-code below:
어려운 지점은 제어가 언어의 암묵적인 부분인 경우(거의 대부분이 해당됨), 프로그래머가 이에 대해 어떤 것도 명시적으로 표현하고 싶지 않은 경우에도 모든 프로그램을 해당 맥락에서 이해해야만 한다는 것입니다.
프로그래머가 (암묵적 제어 흐름을 가진 언어를 사용해서) 제어를 명시하도록 강요받고 있는 경우라면, 원하건 원하지 않건 시스템이 어떻게 작동해야 하는지에 대한 상세 내역을 지정할 수 밖에 없게 됩니다. 사실상 문제를 과도할 정도로 상세히 명시하도록 강요당하고 있는 것입니다.
아래의 간단한 의사 코드를 읽어 봅시다.
a := b + 3 c := d + 2 e := f * 4
In this case it is clear that the programmer has no concern at all with the order in which (i.e. how) these things eventually happen. The programmer is only interested in specifying a relationship between certain values, but has been forced to say more than this by choosing an arbitrary control flow. Often in cases such as this a compiler may go to lengths to establish that such a requirement (ordering) — which the programmer has been forced to make because of the semantics of the language — can be safely ignored.
이런 코드의 경우, 프로그래머는 이런 일들이 발생하는 순서(즉, 방법)에 대해서는 전혀 관심이 없음이 분명해 보입니다. 이 코드를 작성한 프로그래머는 특정한 값들 사이의 관계를 지정하는 데에만 관심이 있습니다. 그러나 임의의 제어 흐름을 선택함으로써 의도한 것보다 더 많은 것을 표현하도록 강요받고 있습니다.
이런 경우 컴파일러는 '언어의 의미론 때문에 프로그래머가 어쩔 수 없이 만든' 이런 요구 사항들(순서)을 안전하게 무시할 수 있다는 것을 입증하기 위해 많은 노력을 기울이게 될 수 있습니다.
In simple cases like the above the issue is often given little consideration, but it is important to realise that two completely unnecessary things are happening — first an artificial ordering is being imposed, and then further work is done to remove it.
위의 예제와 같은 단순한 경우에는 이런 문제를 거의 고려하지 않는 경우가 많습니다. 그러나 먼저 '인위적인 순서'가 부여되었다가 이런 것을 또 제거하기 위한 추가적인 작업이 수행되는 등, 완전히 불필요한 두 가지 일이 발생하고 있다는 사실을 인식하는 것이 중요합니다.
This seemingly innocuous occurrence can actually significantly complicate the process of informal reasoning. This is because the person reading the code above must effectively duplicate the work of the hypothetical compiler — they must (by virtue of the definition of the language semantics) start with the assumption that the ordering specified is significant, and then by further inspection determine that it is not (in cases less trivial than the one above determining this can become very difficult). The problem here is that mistakes in this determination can lead to the introduction of very subtle and hard-to-find bugs.
별로 해롭지 않아 보이기도 하는 이 문제는, 실제로 비형식적 추론 과정을 상당히 복잡하게 만들 수 있습니다.
왜냐하면 위의 코드를 읽는 사람은 언어 의미론의 정의에 따라 지정된 '순서'가 중요하다는 가정 하에서 생각을 시작하여, 추가적인 검사를 통해 사실은 순서가 중요하지 않았다는 것을 판단해야 하기 때문입니다(위의 경우보다 덜 사소한 경우에는 이를 결정하는 것이 매우 어려워질 수 있습니다).
여기에서 문제는 이러한 판단을 잘못 내리면 매우 미묘하고 찾기 어려운 버그가 발생할 수 있다는 것입니다.
It is important to note that the problem is not in the text of the program above — after all that does have to be written down in some order — it is solely in the semantics of the hypothetical imperative language we have assumed. It is possible to consider the exact same program text as being a valid program in a language whose semantics did not define a run-time sequencing based upon textual ordering within the program.2
(프로그램을 결국 어떤 순서에 맞게 작성해야 한다는 것은 맞는 말이지만) 문제가 위의 예제 프로그램 텍스트에 있는 것이 아니라, 우리가 가정한 가상의 명령형 언어의 의미론에 문제가 있다는 점에 주목하는 것이 중요합니다.
프로그램 내의 텍스트 순서에 따른 런타임 순서를 정의하지 않는 언어에서는, 동일한 프로그램 텍스트가 (실행 순서에 대한 가정을 포함하지 않아도) '유효한 프로그램'으로 해석될 수 있습니다.2
Having considered the impact of control on informal reasoning, we now look at a second control-related problem, concurrency, which affects testing as well.
제어가 비형식적 추론에 미치는 영향을 고려했으니, 이제 테스팅에도 영향을 미치는 또 다른 제어 문제인 '동시성(concurrency)'에 대해서도 살펴보겠습니다.
Like basic control such as branching, but as opposed to sequencing, concurrency is normally specified explicitly in most languages. The most common model is “shared-state concurrency” in which specification for explicit synchronization is provided. The impacts that this has for informal reasoning are well known, and the difficulty comes from adding further to the number of scenarios that must mentally be considered as the program is read. (In this respect the problem is similar to that of state which also adds to the number of scenarios for mental consideration as noted above).
분기와 같은 기본 제어와 비슷하긴 하지만, 시퀀싱과는 달리 '동시성'은 일반적으로 대부분의 프로그래밍 언어에서는 명시적으로 지정됩니다.
가장 일반적인 모델은 명시적인 동기화를 위한 스펙이 제공되는 "공유 상태 동시성(shared-state concurrency)"입니다.
이것이 비형식적 추론에 미치는 영향은 잘 알려져 있으며, 프로그램을 읽는 동안 고려해야 하는 가능한 시나리오의 수가 증가함으로써 어려움이 따르는 것도 알려져 있습니다. (이 문제는 이전에 언급한 '상태'의 문제와 비슷하게, 고려해야 하는 가능한 시나리오의 수가 증가한다는 점에서 어려움이 있습니다.)
Concurrency also affects testing, for in this case, we can no longer even be assured of result consistency when repeating tests on a system — even if we somehow ensure a consistent starting state. Running a test in the presence of concurrency with a known initial state and set of inputs tells you nothing at all about what will happen the next time you run that very same test with the very same inputs and the very same starting state… and things can’t really get any worse than that.
동시성은 테스팅에도 영향을 미치는데, 동시성이 관여되는 경우 초기 상태를 어떻게든 일정하게 유지한다 해도 시스템에서 테스트를 반복할 때마다 결과의 일관성은 보장할 수 없게 됩니다.
알려진 초기 상태와 입력 집합이 있어도 동시성이 있는 상태에서 테스트를 실행하면, 똑같은 입력과 똑같은 초기 상태로 똑같은 테스트를 다시 실행한다 하더라도 어떤 일이 일어날지 전혀 예측할 수 없습니다… 이보다 더 나쁠 수는 없습니다.
4.3 Complexity caused by Code Volume
코드의 양 때문에 발생하는 복잡성
The final cause of complexity that we want to examine in any detail is sheer code volume.
마지막으로 살펴볼 복잡성의 원인은 코드의 양입니다.
This cause is basically in many ways a secondary effect — much code is simply concerned with managing state or specifying control. Because of this we shall often not mention code volume explicitly. It is however worth brief independent attention for at least two reasons — firstly because it is the easiest form of complexity to measure, and secondly because it interacts badly with the other causes of complexity and this is important to consider.
Brooks noted [Bro86]:
“Many of the classic problems of developing software products derive from this essential complexity and its nonlinear increase with size”
이 원인은 많은 측면에서 부차적인 효과(secondary effect)에 불과합니다. 많은 양의 코드는 단순히 상태를 관리하거나 제어를 지정하는 데 관여합니다. 따라서 코드의 양에 대해서는 가급적 명시적으로 언급하지 않을 것입니다. 그러나 적어도 두 가지 이유 때문에 이 문제는 별도로 주목할만한 가치가 있습니다.
- 첫째, 코드의 양은 측정하기 가장 쉬운 형태의 복잡성이기 때문입니다.
- 둘째, 코드의 양은 복잡성의 다른 원인과 부정적으로 상호작용을 하는데, 이는 중요하게 고려해야 하는 문제입니다.
[[/people/fred-brooks]]{Brooks}는 다음과 같이 말했습니다.
"소프트웨어 제품 개발의 고전적인 문제들 중 상당수는, '본질적인 복잡성'과 그러한 복잡성이 크기에 따라 비선형적으로 증가한다는 것으로부터 유래합니다."
We basically agree that in most current systems this is true (we disagree with the word “essential” as already noted) — i.e. in most systems complexity definitely does exhibit nonlinear increase with size (of the code). This non-linearity in turn means that it’s vital to reduce the amount of code to an absolute minimum.
우리는 기본적으로 현대적인 시스템의 대부분에서 이 문제가 사실이라는 점에 동의합니다(이미 언급했듯이 "본질적인"이라는 단어에는 동의하지 않습니다). 즉, 대부분의 시스템에서 복잡성은 코드의 규모에 따라 비선형적으로 증가하는 것이 확실합니다.
이러한 비선형성은 결국 코드의 양을 가능한 한 최소한으로 줄이는 것이 중요하다는 것을 의미합니다.
We also want to draw attention to one of Dijkstra’s [Dij72, EWD340] thoughts on this subject:
“It has been suggested that there is some kind of law of nature telling us that the amount of intellectual effort needed grows with the square of program length. But, thank goodness, no one has been able to prove this law. And this is because it need not be true. … I tend to the assumption — up till now not disproved by experience — that by suitable application of our powers of abstraction, the intellectual effort needed to conceive or to understand a program need not grow more than proportional to program length.”
우리는 또한 이 주제에 대한 Dijkstra의 생각 중 하나에 주목하고 싶습니다.
"지적 노력의 양이, 프로그램 길이의 제곱에 비례하여 증가한다는 일종의 자연법칙이 있다는 주장이 제기되어 왔습니다. 하지만 다행히도, 아무도 이 법칙을 증명하지 못했습니다. 그리고 이 법칙은 꼭 사실일 필요도 없습니다. … 나는 지금까지의 경험을 통해, 추상화 능력을 적절히 적용하면 프로그램을 구상하거나 이해하는 데 필요한 지적 능력이 프로그램 길이에 비례하지 않아도 된다고 생각하는 편입니다.
We agree with this — it is the reason for our “in most current systems” caveat above.
We believe that — with the effective management of the two major complexity causes which we have discussed, state and control — it becomes far less clear that complexity increases with code volume in a non-linear way.
우리는 Dijkstra의 이 말에 동의하기 때문에 앞에서 "현대적인 시스템의 대부분에서"라고 주의깊게 언급한 것입니다.
앞에서 논의한 두 가지의 주요한 복잡성 원인인 '상태'와 '제어'를 효과적으로 관리한다면, 코드의 양에 따라 복잡성이 비선형적으로 증가하는 문제를 훨씬 약화시킬 것이라고 믿습니다.
4.4 Other causes of complexity
복잡성의 다른 원인들
Finally there are other causes, for example: duplicated code, code which is never actually used (“dead code”), unnecessary abstraction,3 missed abstraction, poor modularity, poor documentation…
All of these other causes come down to the following three (inter-related) principles:
마지막으로 그 외의 다른 원인들이 있습니다. 중복된 코드, 실제로는 사용되지 않는 코드("죽은 코드"), 불필요한 추상화,3 누락된 추상화, 적절하지 않은 모듈화, 좋지 않은 문서화…
Complexity breeds complexity There are a whole set of secondary causes of complexity. This covers all complexity introduced as a result of not being able to clearly understand a system. Duplication is a prime example of this — if (due to state, control or code volume) it is not clear that functionality already exists, or it is too complex to understand whether what exists does exactly what is required, there will be a strong tendency to duplicate. This is particularly true in the presence of time pressures.
복잡성은 복잡성을 낳는다
복잡성의 이차적인 원인은 다양합니다. 시스템을 명확하게 이해할 수 없기 때문에 발생하는 모든 복잡성이 여기에 포함됩니다. 중복이 이러한 복잡성의 대표적인 예입니다. (상태, 제어 또는 코드의 양 때문에) 기능이 이미 존재하는지 명확하지 않거나, 기존의 기능이 요구되는 기능을 정확히 수행하는지 이해하기가 너무 복잡하다면, 중복의 가능성이 높아집니다. 특히 일정의 압박이 있는 경우에 더욱 그렇습니다.
Simplicity is Hard This was noted above — significant effort can be required to achieve simplicity. The first solution is often not the most simple, particularly if there is existing complexity, or time pressure. Simplicity can only be attained if it is recognised, sought and prized.
단순함은 달성하기 어렵다
앞에서 언급한 바와 같이 단순성을 달성하기 위해서는 상당한 노력이 필요할 수 있습니다. 이미 존재하는 복잡성이 있거나 일정의 압박이 있는 경우에는, 첫 번째 솔루션이 가장 단순한 종류의 것이 아닌 경우가 많습니다.
단순함을 인식하고, 추구하고, 중요하게 여기는 경우에만 단순함을 달성할 수 있습니다.
Power corrupts What we mean by this is that, in the absence of language-enforced guarantees (i.e. restrictions on the power of the language) mistakes (and abuses) will happen. This is the reason that garbage collection is good — the power of manual memory management is removed. Exactly the same principle applies to state — another kind of power. In this case it means that we need to be very wary of any language that even permits state, regardless of how much it discourages its use (obvious examples are ML and Scheme). The bottom line is that the more powerful a language (i.e. the more that is possible within the language), the harder it is to understand systems constructed in it.
권력은 부패한다
이것은 언어에 대한 제한(즉, 언어의 권력에 대한 제한)이 없으면 실수 및 남용이 발생할 수 있다는 뜻입니다. 가비지 컬렉션이 좋은 이유이기도 합니다. 가비지 컬렉션은 수동 메모리 관리의 권력을 제거하기 때문입니다.
이와 동일한 원칙이 '상태'라는 또 다른 형태의 권력에도 적용됩니다. 이 경우에는 상태를 허용하는 모든 언어를 사용할 때에는 아무리 사용을 억제하더라도, 극도로 주의해야 한다는 뜻입니다(ML과 Scheme이 대표적인 예입니다).
결론은 강력한 언어일수록(즉, 언어 내에서 가능한 것이 많을수록) 그 언어로 구성된 시스템은 이해하기가 더 어렵다는 것입니다.
Some of these causes are of a human-nature, others due to environmental issues, but all can — we believe — be greatly alleviated by focusing on effective management of the complexity causes discussed in sections 4.1–4.3.
이러한 원인 중 일부는 인간의 본성에 기인하는 것이고, 다른 일부는 환경 문제로 비롯된 것들입니다. 그러나 우리는 4.1~4.3 절에서 논의한 복잡성의 원인을 효과적으로 관리하는 데 집중하면 이런 원인들을 모두 상당히 완화할 수 있다고 믿습니다.
5 Classical approaches to managing complexity
복잡성 관리를 위한 고전적인 접근법
The different classical approaches to managing complexity can perhaps best be understood by looking at how programming languages of each of the three major styles (imperative, functional, logic) approach the issue. (We take object-oriented languages as a commonly used example of the imperative style).
복잡성 관리에 대한 다양한 고전적인 접근법은, 세 가지의 주요 스타일(명령형, 함수형, 논리형)의 프로그래밍 언어가 이 문제에 접근하는 방식을 살펴보면 가장 잘 이해할 수 있을 것입니다. (우리는 객체지향 언어를 명령형 스타일의 일반적인 예로 삼습니다.)
5.1 Object-Orientation
객체지향
Object-orientation — whilst being a very broadly applied term (encompassing everything from Java-style class-based to Self-style prototype-based languages, from single-dispatch to CLOS-style multiple dispatch languages, and from traditional passive objects to the active / actor styles) — is essentially an imperative approach to programming. It has evolved as the dominant method of general software development for traditional (von-Neumann) computers, and many of its characteristics spring from a desire to facilitate von-Neumann style (i.e. state-based) computation.
객체지향은 매우 광범위하게 적용되는 용어이지만(Java 스타일의 class 기반 언어에서 Self 스타일의 prototype 기반 언어, 단일 디스패치 언어부터 CLOS 스타일의 다중 디스패치 언어, 그리고 전통적인 수동 객체부터 active/actor 스타일까지 모두 객체지향에 포함됩니다), 그 본질은 명령형(imperative) 프로그래밍 접근법입니다.
이는 전통적인(폰 노이만) 컴퓨터에 대한 일반적인 소프트웨어 개발 방법으로 발전해 왔으며, 그 특성 중 많은 것들은 폰 노이만 스타일(즉, 상태 기반)의 계산을 용이하게 하고자 하는 욕구에서 비롯됩니다.
5.1.1 State
상태
In most forms of object-oriented programming (OOP) an object is seen as consisting of some state together with a set of procedures for accessing and manipulating that state.
This is essentially similar to the (earlier) idea of an abstract data type (ADT) and is one of the primary strengths of the OOP approach when compared with less structured imperative styles. In the OOP context this is referred to as the idea of encapsulation, and it allows the programmer to enforce integrity constraints over an object’s state by regulating access to that state through the access procedures (“methods”).
대부분의 객체지향 프로그래밍(OOP)에서 '객체'는 특정한 상태와 그 상태에 접근하고 조작하기 위한 절차들의 집합으로 구성되는 것으로 간주할 수 있습니다.
이는 본질적으로 추상 데이터 타입(ADT)의 (이전) 개념과 유사하며, 덜 구조화된 명령형 스타일과 비교했을 때 OOP 접근법의 주요 장점 중 하나입니다. OOP 맥락에서는 이것을 캡슐화라 부릅니다. 이를 통해 프로그래머는 접근 프로시저("메소드")를 통한 상태 접근을 제한하는 방법으로 객체의 상태에 대한 무결성을 유지하게 합니다.
One problem with this is that, if several of the access procedures access or manipulate the same bit of state, then there may be several places where a given constraint must be enforced (these different access procedures may or may not be within the same file depending on the specific language and whether features, such as inheritance, are in use). Another major problem4 is that encapsulation-based integrity constraint enforcement is strongly biased toward single-object constraints and it is awkward to enforce more complicated constraints involving multiple objects with this approach (for one thing it becomes unclear where such multiple-object constraints should reside).
이 방법의 한 가지 문제점은 여러 접근 프로시저가 하나의 상태 비트에 접근하거나 그걸 조작하는 경우에, 주어진 제약 조건을 적용해야 하는 위치가 여러 곳에 있을 수 있다는 것입니다(특정 언어와 상속과 같은 기능의 사용 여부에 따라 서로 다른 접근 프로시저가 같은 파일에 있을 수도 있고, 다른 파일에 있을 수도 있습니다).
그리고 또 다른 주요한 문제점4은 '캡슐화 기반의 무결성 제약 조건' 적용이, 주로 '단일 객체에 대한 제약'을 중심으로 하기 때문에, 이런 접근 방식으로는 여러 객체가 관련된 더 복잡한 제약 조건을 적용하기가 어렵다는 것입니다(일단 이런 다중 객체 제약 조건을 어디에 위치시켜야 하는지가 불분명합니다).
Identity and State
동일성과 상태
There is one other intrinsic aspect of OOP which is intimately bound up with the issue of state, and that is the concept of object identity.
상태 문제와 밀접하게 연관되어 있는 OOP의 또다른 본질적인 측면이 하나 더 있습니다. 바로 객체의 동일성 개념입니다.
In OOP, each object is seen as being a uniquely identifiable entity regardless of its attributes. This is known as intensional identity (in contrast with extensional identity in which things are considered the same if their attributes are the same). As Baker observed [Bak93]:
In a sense, object identity can be considered to be a rejection of the “relational algebra” view of the world in which two objects can only be distinguished through differing attributes.
OOP에서 각 객체는 속성값들과는 관계없이 고유하게 식별 가능한 엔티티로 간주됩니다. 이를 '내재적 동일성'이라 합니다(속성값들이 같으면 동일한 것으로 간주하는 '확장적 동일성'과 대조적인 개념입니다). Baker는 다음과 같이 언급한 바 있습니다.
어떤 의미에서, 객체 동일성은 서로 다른 속성을 통해서만 두 객체를 구별할 수 있는 '관계 대수'의 세계관을 거부하는 것으로 간주할 수 있습니다.
Object identity does make sense when objects are used to provide a (mutable) stateful abstraction — because two distinct stateful objects can be mutated to contain different state even if their attributes (the contained state) happen initially to be the same.
객체 동일성은 객체가 (변경 가능한) 상태 추상화(stateful abstraction)를 제공하는 데 사용될 때 의미가 있습니다. 왜냐하면 두 개의 서로 다른 상태 저장 객체는 초기에는 속성(포함된 상태)이 같더라도, 나중에는 서로 다른 상태를 갖고 있게 변경될 수 있기 때문입니다.
However, in other situations where mutability is not required (such as — say — the need to represent a simple numeric value), the OOP approach is forced to adopt techniques such as the creation of “Value Objects”, and an attempt is made to de-emphasise the original intensional concept of object identity and re-introduce extensional identity. In these cases it is common to start using custom access procedures (methods) to determine whether two objects are equivalent in some other, domain-specific sense. (One risk — aside from the extra code volume required to support this — is that there can no longer be any guarantee that such domain-specific equivalence concepts conform to the standard idea of an equivalence relation — for example there is not necessarily any guarantee of transitivity).
그러나 이런 변경 가능(mutability)이 필요하지 않은 다른 상황(예: 단순한 숫자값을 표현하는 경우)에서는 OOP식 접근 방법은 "값 객체(Value Objects)" 생성과 같은 기술을 채택할 수 밖에 없으며, 본래 의도했던 객체 동일성 컨셉이 아니라 확장적 동일성을 다시 도입하는 상황이 됩니다. 이러한 경우에는 커스텀 접근 프로시저(메소드)를 사용해 두 객체가 다른 도메인별 의미에서 동등한지 아닌지를 결정하는 것이 일반적입니다.
(이를 위해 추가해야 하는 코드의 양을 제외하고 생각한다 해도) 이런 방식은 도메인별 동등성 개념이 동등 관계(equivalence relation)의 표준 개념과 일치하는지에 대한 보장이 없다는 위험을 안고 있습니다. 예를 들어, 이행성(transitivity)을 보장할 수 없다는 문제도 있습니다.)
The intrinsic concept of object identity stems directly from the use of state, and is (being part of the paradigm itself) unavoidable. This additional concept of identity adds complexity to the task of reasoning about systems developed in the OOP style (it is necessary to switch mentally between the two equivalence concepts — serious errors can result from confusion between the two).
객체 동일성의 본질적인 개념은 '상태'의 사용에서 직접적으로 비롯되며, (패러다임 자체에서 나온 것이므로) 피할 수 없습니다. 이런 추가적인 동일성 개념은 OOP 스타일로 개발된 시스템에 대한 추론 작업에 복잡성을 더해줍니다(두 가지의 동등성 개념 사이를 정신적으로 전환해야 하며, 두 개념을 혼동하면 심각한 오류가 발생할 수 있습니다).
State in OOP
OOP의 상태
The bottom line is that all forms of OOP rely on state (contained within objects) and in general all behaviour is affected by this state. As a result of this, OOP suffers directly from the problems associated with state described above, and as such we believe that it does not provide an adequate foundation for avoiding complexity.
결론은 모든 형태의 OOP는 객체 내에 포함되는 상태에 의존하며, 일반적으로 모든 동작이 이 상태의 영향을 받는다는 것입니다. 그 결과, OOP는 앞에서 설명한 '상태'와 관련된 문제를 직접적으로 겪게 됩니다. 따라서 복잡성을 피하기 위한 적절한 기반을 제공하지 못한다고 생각합니다.
5.1.2 Control
제어
Most OOP languages offer standard sequential control flow, and many offer explicit classical “shared-state concurrency” mechanisms together with all the standard complexity problems that these can cause. One slight variation is that actor-style languages use the “message-passing” model of concurrency — they associate threads of control with individual objects and messages are passed between these. This can lead to easier informal reasoning in some cases, but the use of actor-style languages is not widespread.
대부분의 OOP 언어는 표준적인 순차적 제어 흐름을 제공합니다. 따라서 많은 언어가 명시적으로 고전적인 "공유 상태 동시성(shared-state concurrency)" 메커니즘을 제공하게 되기 때문에 이로 인해 발생할 수 있는 모든 표준적인 복잡성 문제도 함께 발생하게 됩니다.
한 가지 차이점이 있다면 액터 스타일의 언어에서는 제어 스레드를 개별 객체와 연결하고 그 객체들 사이에 메시지를 전달하는 '메시지 전달' 동시성을 사용한다는 점입니다. 이 기법을 사용하면 비형식적 추론이 더 쉬워질 수 있습니다. 그러나 액터 스타일 언어는 널리 사용되고 있지는 않습니다.
5.1.3 Summary — OOP
OOP 요약
Conventional imperative and object-oriented programs suffer greatly from both state-derived and control-derived complexity.
현존하는 명령형 및 객체지향 프로그램은 상태와 제어로 인한 복잡성에 큰 어려움을 겪습니다.
5.2 Functional Programming
함수형 프로그래밍
Whilst OOP developed out of a desire to offer improved ways of managing and dealing with the classic stateful von-Neumann architecture, functional programming has its roots in the completely stateless lambda calculus of Church (we are ignoring the even simpler functional systems based on combinatory logic). The untyped lambda calculus is known to be equivalent in power to the standard stateful abstraction of computation — the Turing machine.
고전적인 상태 기반(stateful) 폰 노이만 아키텍처를 관리하고 처리하는 개선된 방법을 제공하려는 의도에서 OOP는 개발되었습니다. 반면 함수형 프로그래밍은 Church의 완전한 무상태 기반의(stateless) 람다 계산법에 뿌리를 두고 있습니다(조합 논리에 기반한 더 단순한 함수형 시스템은 여기에서는 언급하지 않겠습니다).
타입 없는 람다 계산법은 표준 상태 저장 추상화 계산, 즉 튜링 머신과 동등한 성능을 발휘하는 것으로 알려져 있습니다.
5.2.1 State
상태
Modern functional programming languages are often classified as ‘pure’ — those such as Haskell[PJ+03] which shun state and side-effects completely, and ‘impure’ — those such as ML which, whilst advocating the avoidance of state and side-effects in general, do permit their use. Where not explicitly mentioned we shall generally be considering functional programming in its pure form.
현대적인 함수형 프로그래밍 언어는 '상태와 사이드 이펙트를 완전히 배제하는' Haskell 같은 '순수한' 언어와, '상태와 부작용의 회피를 옹호하면서도 사용을 허용하기는 하는' ML과 같은 '불순한' 언어로 분류되곤 합니다.
여기에서는 별도로 언급하지 않는 이상, 일반적으로는 순수한 형태의 함수형 프로그래밍을 고려하겠습니다.
The primary strength of functional programming is that by avoiding state (and side-effects) the entire system gains the property of referential transparency — which implies that when supplied with a given set of arguments a function will always return exactly the same result (speaking loosely we could say that it will always behave in the same way). Everything which can possibly affect the result in any way is always immediately visible in the actual parameters.
함수형 프로그래밍의 가장 큰 장점은 상태(와 부작용)를 피함으로써 전체 시스템이 참조 투명성이라는 특성을 얻게 된다는 것입니다. 이는 특정한 인수 집합이 제공될 때 함수가 항상 정확히 같은 결과를 반환한다는 것을 의미합니다(대충 말하자면 항상 같은 방식으로 동작한다고 할 수 있습니다).
어떤 방식으로든 '결과에 영향을 줄 수 있는 모든 것'을 항상 실제 매개변수에서 바로 확인할 수 있다는 것입니다.
It is this cast iron guarantee of referential transparency that obliterates one of the two crucial weaknesses of testing as discussed above. As a result, even though the other weakness of testing remains (testing for one set of inputs says nothing at all about behaviour with another set of inputs), testing does become far more effective if a system has been developed in a functional style.
참조 투명성의 이런 철저한 보장은, 앞에서 설명한 테스팅의 두 가지 중요한 약점 중 하나를 원천봉쇄하는 것입니다.
결과적으로 테스트의 다른 약점(어떤 입력 집합에 대한 테스트만으로는, 다른 입력 집합에 대한 동작에 대해 전혀 알 수 없음)이 남아있게 되긴 하지만, 시스템이 함수형 스타일로 개발되었다면 테스트는 훨씬 효과적이 됩니다.
By avoiding state functional programming also avoids all of the other state-related weaknesses discussed above, so — for example — informal reasoning also becomes much more effective.
상태를 회피함으로써, 함수형 프로그래밍은 상태와 관련된 앞에서 언급한 모든 약점을 회피하게 됩니다. 따라서 비형식적인 추론도 훨씬 효과적이 됩니다.
5.2.2 Control
제어
Most functional languages specify implicit (left-to-right) sequencing (of calculation of function arguments) and hence they face many of the same issues mentioned above. Functional languages do derive one slight benefit when it comes to control because they encourage a more abstract use of control using functionals (such as fold / map) rather than explicit looping.
There are also concurrent versions of many functional languages, and the fact that state is generally avoided can give benefits in this area (for example in a pure functional language it will always be safe to evaluate all arguments to a function in parallel).
(함수 인수의 계산 우선순위에 대해) 대부분의 함수형 언어는 암묵적으로 (왼쪽에서 오른쪽으로) 순서를 지정하므로 위에서 언급한 것과 동일한 문제에 직면하게 됩니다.
함수형 언어는 명시적인 loop 대신, 함수(예: fold/map5)를 사용하여 제어를 더 추상적으로 사용하도록 권장하므로, 제어에 관해서는 약간의 이점을 얻게 됩니다.
또한 많은 함수형 언어들에는 동시성에 대한 버전도 있으며, 이 언어들이 일반적으로 '상태'를 피하는 방식이라는 사실 덕분에 동시성 측면에서 이점을 얻을 수 있습니다(예를 들어 순수한 함수형 언어에서는 함수의 모든 인수를 병렬로 평가해도 안전합니다).
5.2.3 Kinds of State
상태의 종류
In most of this paper when we refer to “state” what we really mean is mutable state.
이 페이퍼에서 사용하는 '상태(state)'라는 용어는, '변경 가능한 상태(mutable state)'를 의미합니다.
In languages which do not support (or discourage) mutable state it is common to achieve somewhat similar effects by means of passing extra parameters to procedures (functions). Consider a procedure which performs some internal stateful computation and returns a result — perhaps the procedure implements a counter and returns an incremented value each time it is called:
변경 가능한 상태(mutable state)를 지원하지 않거나 권장하지 않는 언어에서는 프로시저(함수)에 추가 매개변수를 전달하는 방식으로 비슷한 효과를 얻는 것이 일반적입니다.
내부적으로 상태를 갖는 계산을 수행하고 결과를 반환하는 프로시저를 생각해 봅시다. 다음의 프로시저는 카운터를 구현하고 호출될 때마다 증가된 값을 반환합니다.
procedure int getNextCounter() // ’counter’ is declared and initialized elsewhere in the code counter := counter + 1 return counter
The way that this is typically implemented in a basic functional programming language is to replace the stateful procedure which took no arguments and returned one result with a function which takes one argument and returns a pair of values as a result.
기본적인 함수형 프로그래밍 언어에서 이런 프로시저를 구현하는 일반적인 방법은, '인수를 받지 않고 하나의 결과를 리턴하는 상태를 갖는 프로시저'(위의 예제)를, '인수를 하나 받고 두 개의 값을 리턴하는 함수'로 대체하는 것입니다.
function (int,int) getNextCounter(int oldCounter)
let int result = oldCounter + 1
let int newCounter = oldCounter + 1
return (newCounter, result)
There is then an obligation upon the caller of the function to make sure that the next time the
getNextCounterfunction gets called it is supplied with thenewCounterreturned from the previous invocation. Effectively what is happening is that the mutable state that was hidden inside thegetNextCounterprocedure is replaced by an extra parameter on both the input and output of thegetNextCounterfunction. This extra parameter is not mutable in any way (the entity which is referred to byoldCounteris a different value each time the function is called).
이렇게 하면, 함수 호출자는 다음번에 getNextCounter 함수를 호출할 때, 이전 호출의 리턴값으로 받은 newCounter를 인수로 전달해야 합니다.
즉, getNextCounter 프로시저 내부에 숨겨져 있었던 변경 가능한 상태가 getNextCounter 함수의 입력과 출력 모두에서 추가 매개변수로 대체된 것입니다.
이런 추가 매개변수는 어떤 방식으로도 변경할 수 없습니다(oldCounter가 참조하는 엔티티는 함수가 호출될 때마다 다른 값입니다).
As we have discussed, the functional version of this program is referentially transparent, and the imperative version is not (hence the caller of the
getNextCounterprocedure has no idea what may influence the result he gets — it could in principle be dependent upon many, many different hidden mutable variables — but the caller of thegetNextCounterfunction can instantly see exactly that the result can depend only on the single value supplied to the function).
앞에서 설명했듯이, 이 프로그램의 함수 버전은 참조 투명성(referential transparency)을 갖고 있지만, 명령형 버전은 참조 투명성을 갖고 있지 않습니다.
getNextCounter 프로시저를 호출하는 쪽에서는 어떤 것이 결과에 영향을 미칠 수 있는지를 알 수 없으며, 이론적으로는 수많은 숨겨진 mutable 변수에 따라 결과가 달라질 수 있습니다.
하지만 getNextCounter 함수의 호출자 입장에서는 함수에 전달하는 단일 값에만 결과가 의존한다는 것을 즉시 알 수 있습니다.
Despite this, the fact is that we are using functional values to simulate state. There is in principle nothing to stop functional programs from passing a single extra parameter into and out of every single function in the entire system. If this extra parameter were a collection (compound value) of some kind then it could be used to simulate an arbitrarily large set of mutable variables. In effect this approach recreates a single pool of global variables — hence, even though referential transparency is maintained, ease of reasoning is lost (we still know that each function is dependent only upon its arguments, but one of them has become so large and contains irrelevant values that the benefit of this knowledge as an aid to understanding is almost nothing). This is however an extreme example and does not detract from the general power of the functional approach.
그럼에도 불구하고 우리는 함수형 값을 사용해 '상태'를 시뮬레이션하고 있는 것이 사실입니다. 원칙적으로는 함수형 프로그램에서 전체 시스템의 모든 함수에 하나의 추가 매개변수를 전달하는 것을 막을 수 있는 방법은 없습니다. 이러한 추가 매개변수가 어떤 종류의 컬렉션(복합 값)이라면, 이를 사용해 임의로 큰 크기의 mutable 변수 집합을 시뮬레이션할 수도 있습니다.
사실상 이 접근 방식은 하나의 전역 변수 풀을 다시 생성하게 되므로, 참조 투명성은 유지되지만 추론의 용이성은 손실됩니다(각 함수가 그 인자에만 의존한다는 것은 여전히 알고 있지만, 그 추가 매개변수가 너무 커져서 불필요한 값들을 포함하게 되기 때문입니다. 이러한 것은 이해를 돕는다는 측면의 장점을 거의 없애버립니다).
그러나 이것은 극단적인 사례이며, 함수형 접근법의 일반적인 효과를 떨어뜨리는 것은 아닙니다.
It is worth noting in passing that — even though it would be no substitute for a guarantee of referential transparency — there is no reason why the functional style of programming cannot be adopted in stateful languages (i.e. imperative as well as impure functional ones). More generally, we would argue that — whatever the language being used — there are large benefits to be had from avoiding hidden, implicit, mutable state.
참조 투명성 보장을 대체할 수는 없지만, statueful 언어(명령형, 순수하지 못한 함수형)에서 함수형 프로그래밍 스타일을 채택하지 못할 이유가 없다는 점은 언급해 둘 가치가 있습니다. 더 일반적으로는, 어떤 프로그래밍 언어를 사용하건 간에 암시적이고 변경 가능한 숨겨진 상태를 피함으로써 얻을 수 있는 이점이 크다고 주장할 수 있겠습니다.
5.2.4 State and Modularity
상태와 모듈성
It is sometimes argued (e.g. [vRH04, p315]) that state is important because it permits a particular kind of modularity. This is certainly true. Working within a stateful framework it is possible to add state to any component without adjusting the components which invoke it. Working within a functional framework the same effect can only be achieved by adjusting every single component that invokes it to carry the additional information around (as with the
getNextCounterfunction above).
상태는 특정 유형의 모듈성을 허용하기 때문에 중요하다는 주장이 있습니다. 그 주장은 확실한 사실입니다.
상태 기반 프레임워크 내에서 작업을 하면, 상태를 호출하는 컴포넌트를 조정하지 않고도 모든 컴포넌트에 상태를 추가할 수 있습니다.
그러나 함수형 프레임워크 내에서 작업할 때는 위의 getNextCounter 함수처럼, 추가 정보를 전달하기 위해 호출하는 모든 컴포넌트를 조정해야만 동일한 효과를 얻을 수 있습니다.
There is a fundamental trade off between the two approaches. In the functional approach (when trying to achieve state-like results) you are forced to make changes to every part of the program that could be affected (adding the relevant extra parameter), in the stateful you are not.
두 접근 방식 사이에는 근본적인 트레이드 오프가 있습니다. 함수형 접근방식에서는 (state기반 방식과 유사한 결과를 얻으려 한다면) 영향을 받을 수 있는 프로그램의 모든 부분을 변경(관련된 부가적인 매개변수를 추가)해야 하지만, 상태 기반(stateful) 방식에서는 그렇지 않습니다.
But what this means is that in a functional program you can always tell exactly what will control the outcome of a procedure (i.e. function) simply by looking at the arguments supplied where it is invoked. In a stateful program this property (again a consequence of referential transparency) is completely destroyed, you can never tell what will control the outcome, and potentially have to look at every single piece of code in the entire system to determine this information.
하지만 함수형 접근방식의 의미는, 함수형 프로그램에서는 프로시저(함수) 호출시에 제공되는 인자를 살펴보면 어떤 것이 프로시저의 결과를 제어하는지에 대해 항상 정확히 알 수 있다는 것에 있습니다.
상태 기반 프로그램에서는 이러한 속성(참조 투명성의 결과)이 완전히 파괴됩니다. 따라서 무엇이 결과를 제어하는지 알기 어려우며, 이 정보를 파악하기 위해 전체 시스템의 모든 코드를 살펴봐야 할 수도 있습니다.
The trade-off is between complexity (with the ability to take a shortcut when making some specific types of change) and simplicity (with huge improvements in both testing and reasoning).
이 트레이드 오프는 복잡성(특정 유형의 변경을 수행할 때 지름길을 선택할 수 있는 능력)과 단순성(테스트와 추론이 모두 크게 향상됨) 사이에 있습니다.
As with the discipline of (static) typing, it is trading a one-off up-front cost for continuing future gains and safety (“one-off” because each piece of code is written once but is read, reasoned about and tested on a continuing basis).
(정적) 타이핑의 규칙과 마찬가지로, 일회성의 초기 비용을 미래의 지속적인 이득과 안전성을 위해 교환하는 것입니다. ("일회성"이라 표현한 것은 각 코드 조각이 한 번만 작성되지만 지속적으로 읽히고, 추론의 대상이 되고, 테스트되기 때문입니다.)
A further problem with the modularity argument is that some examples — such as the use of procedure (function) invocation counts for debugging / performance-tuning purposes — seem to be better addressed within the supporting infrastructure / language, rather than within the system itself (we prefer to advocate a clear separation between such administrative/diagnostic information and the core logic of the system).
(상태가 특정 유형의 모듈성을 가능하게 한다는 내용의) '모듈화 주장'의 또 다른 문제점은 디버깅/성능 튜닝을 위한 프로시저(함수) 호출 횟수를 사용하는 것 같은 일부 사례는, 시스템 자체보다는 지원하는 인프라/언어 내에서 더 잘 해결될 수 있다는 것입니다(우리는 이런 관리/진단 정보와 시스템의 핵심 로직을 명확하게 분리하는 것을 선호합니다).
Still, the fact remains that such arguments have been insufficient to result in widespread adoption of functional programming. We must therefore conclude that the main weakness of functional programming is the flip side of its main strength — namely that problems arise when (as is often the case) the system to be built must maintain state of some kind.
그러나, 함수형 프로그래밍이 널리 받아들여지지 않았다는 사실은 여전히 변하지 않습니다. 이런 점에서 우리는 함수형 프로그래밍의 가장 큰 장점이 동시에 가장 큰 단점이라는 결론을 내릴 수밖에 없습니다. 바로 시스템이 (자주 그렇듯이) 어떤 형태의 상태를 유지해야 한다면 함수형 프로그래밍의 개념에서는 문제가 발생한다는 것입니다.
The question inevitably arises of whether we can find some way to “have our cake and eat it”. One potential approach is the elegant system of monads used by Haskell [Wad95]. This does basically allow you to avoid the problem described above, but it can very easily be abused to create a stateful, side-effecting sub-language (and hence re-introduce all the problems we are seeking to avoid) inside Haskell — albeit one that is marked by its type. Again, despite their huge strengths, monads have as yet been insucient to give rise to widespread adoption of functional techniques.
그렇다면 "두 마리 토끼를 잡을 수 있는" 방법이 있는지에 대한 질문이 불가피하게 제기됩니다.
한 가지 잠재성 있는 접근 방식은 Haskell에서 사용하는 우아한 monad 시스템입니다. monad 시스템은 기본적으로 위에서 설명한 문제를 피할 수 있습니다. 그러나 Haskell 에서는 이 기법을 악용해 타입을 통해 표시되는, 상태 기반의 부작용이 있는 서브 언어(stateful, side-effecting sub-language)를 쉽게 만들어 낼 수 있으며, 우리가 피하려고 하는 모든 문제를 다시 도입할 수도 있습니다. 다시 말하지만, monad 시스템 같은 엄청난 장점이 있는데도 불구하고 아직까지 함수형 기법은 널리 받아들여지게 하는 데에는 부족함이 있습니다.
5.2.5 Summary - Functional Programming
요약 - 함수형 프로그래밍
Functional programming goes a long way towards avoiding the problems of state-derived complexity. This has very significant benefits for testing (avoiding what is normally one of testing’s biggest weaknesses) as well as for reasoning.
함수형 프로그래밍은 상태 기반 복잡성의 문제를 피하는 데에 큰 도움이 됩니다.
이는 테스트에 대해 매우 중요한 장점을 가져다 주며(테스팅의 가장 큰 약점 중 하나를 피하는 데에 도움이 됩니다), 추론에도 도움이 됩니다.
5.3 Logic Programming
Together with functional programming, logic programming is considered to be a declarative style of programming because the emphasis is on specifying what needs to be done rather than exactly how to do it. Also as with functional programming — and in contrast with OOP — its principles and the way of thinking encouraged do not derive from the stateful von-Neumann architecture.
함수형 프로그래밍과 논리 프로그래밍은 선언형 프로그래밍 스타일로 간주할 수 있습니다. 왜냐하면 이 둘은 '정확한 수행 방법'이 아니라 '수행하고 싶은 작업'을 명시하는 데에 중점을 두기 때문입니다.
또한 함수형 프로그래밍과 마찬가지로(OOP와는 달리) 논리 프로그래밍의 원칙과 권장되는 사고 방식은 '상태 기반의 von-Neumann 아키텍처'에서 유래한 것이 아니라는 특징이 있습니다.
Pure logic programming is the approach of doing nothing more than making statements about the problem (and desired solutions). This is done by stating a set of axioms which describe the problem and the attributes required of something for it to be considered a solution. The ideal of logic programming is that there should be an infrastructure which can take the raw axioms and use them to find or check solutions. All solutions are formal logical consequences of the axioms supplied, and “running” the system is equivalent to the construction of a formal proof of each solution.
순수한 논리 프로그래밍은 문제와 원하는 해답에 대한 명제만을 작성하는 접근 방식입니다. 이는 문제를 설명하고 해답을 얻기 위해 요구되는 속성들을 명시하는 일련의 공리(axiom)를 세우는 것으로 이루어집니다. 논리 프로그래밍의 이상적인 모델은 이러한 기본이 되는 공리들을 적용해 해결책을 찾거나 검증할 수 있는 인프라를 갖춰야 한다는 것입니다. 모든 해답은 제공된 공리들을 통한 형식적 논리의 결과이며, 시스템을 '실행'한다는 것은 각 해답에 대한 형식적인 증명을 구성하는 것과 동일합니다.
The seminal “logic programming” language was Prolog. Prolog is best seen as a pure logical core (pure Prolog) with various extra-logical extensions.6 Pure Prolog is close to the ideals of logic programming, but there are important differences. Every pure Prolog program can be “read” in two ways — either as a pure set of logical axioms (i.e. assertions about the problem domain — this is the pure logic programming reading), or operationally — as a sequence of commands which are applied (in a particular order) to determine whether a goal can be deduced (from the axioms). This second reading corresponds to the actual way that pure Prolog will make use of the axioms when it tries to prove goals. It is worth noting that a single Prolog program can be both correct when read in the first way, and incorrect (for example due to non-termination) when read in the second.
"논리 프로그래밍"의 기원은 Prolog입니다. Prolog는 순수한 논리적 핵심(pure logical core)에 다양한 추가적인 논리 확장6이 결합된 형태로 이해하는 것이 가장 바람직합니다. 순수한 Prolog는 논리 프로그래밍의 이상에 가깝지만, 중요한 차이점이 있습니다.
모든 순수한 Prolog 프로그램은 두 가지 방법으로 해석할 수 있습니다.
- 순수한 논리적 공리들의 집합(즉, 문제 도메인에 대한 주장(assertions))
- 순수한 논리 프로그래밍으로 Prolog 프로그램을 해석하는 방식.
- 공리로부터 목표를 추론할 수 있는지를 결정하기 위해 (특정한 순서로) 적용하는 명령어들의 시퀀스.
- 작동방식을 기준으로 Prolog 프로그램을 해석하는 방식.
두 번째 해석 방식은 순수한 Prolog가 공리들을 활용하여 목표를 입증하려고 시도할 때의 실제 작동 방식에 해당합니다.
하나의 Prolog 프로그램은 첫 번째 해석 방식으로 보면 논리적으로 모순이 없을 수 있지만, 두 번째 해석 방식으로 볼 때에는 (예를 들어 무한 루프 등으로 인해) 잘못된 프로그램일 수 있다는 점을 주목해야 합니다.
It is for this reason that Prolog falls short of the ideals of logic programming. Specifically it is necessary to be concerned with the operational interpretation of the program whilst writing the axioms.
Prolog가 논리 프로그래밍의 이상적인 지점에 도달하지 못하는 이유가 바로 여기에 있습니다. 공리를 작성하는 동안에도 프로그램의 작동 방식에 주의를 기울여야 한다는 점이 문제입니다.
5.3.1 State
상태
Pure logic programming makes no use of mutable state, and for this reason profits from the same advantages in understandability that accrue to pure functional programming. Many languages based on the paradigm do however provide some stateful mechanisms. In the extra-logical part of Prolog for example there are facilities for adjusting the program itself by adding new axioms for example. Other languages such as Oz (which has its roots in logic programming but has been extended to become “multi-paradigm”) provide mutable state in a traditional way — similar to the way it is provided by impure functional languages.
순수한 논리 프로그래밍은 변경 가능한 상태(mutable state)를 전혀 사용하지 않으므로, 순수한 함수형 프로그래밍과 같이 '이해'하기 용이하다는 장점을 누리게 됩니다.
그러나 논리 패러다임에 기반한 많은 언어들은 상태 기반 메커니즘도 제공합니다. 예를 들어 Prolog의 논리 확장 부분에서는 새로운 공리를 추가하여 프로그램 자체를 조정할 수 있는 기능이 있습니다. (논리 프로그래밍에 뿌리를 두고 있지만 "다중 패러다임"으로 확장된) Oz 프로그래밍 언어와 같은 다른 언어들은, 순수하지 않은 함수형 언어에서 제공하는 방식과 유사하게 '변경 가능한 상태'를 제공합니다.
All of these approaches to state sacrifice referential transparency and hence potentially suffer from the same drawbacks as imperative languages in this regard. The one advantage that all these impure non-von-Neumann derived languages can claim is that — whilst state is permitted its use is generally discouraged (which is in stark contrast to the stateful von-Neumann world). Still, without purity there are no guarantees and all the same state-related problems can sometimes occur.
이런 종류의 상태 관리 접근법은 참조 투명성을 희생하므로, 이 관점에서 명령형 언어와 같은 단점을 갖게 됩니다. 이런 식의 순수하지 않은 'non-폰 노이만' 파생 언어들이 주장하는 것은, 상태의 사용을 허용하긴 하지만 권장은 하지 않는다는 것입니다. (이는 상태 중심으로 돌아가는 폰 노이만 세계와는 대조적인 점입니다.) 그러나 순수성이 없기 때문에 어떤 것도 보장할 수 없으며 때때로 상태 관련 문제가 발생할 수 있습니다.
5.3.2 Control
제어
In the case of pure Prolog the language specifies both an implicit ordering for the processing of sub-goals (left to right), and also an implicit ordering of clause application (top down) — these basically correspond to an operational commitment to process the program in the same order as it is read textually (in a depth first manner). This means that some particular ways of writing down the program can lead to non-termination, and — when combined with the fact that some extra-logical features of the language permit side-effects — leads inevitably to the standard difficulty for informal reasoning caused by control flow. (Note that these reasoning difficulties do not arise in ideal world of logic programming where there simply is no specified control — as distinct from in pure Prolog programming where there is).
순수한 Prolog의 경우, 프로그래밍 언어는 하위 목표(sub-goal)의 처리 순서(왼쪽에서 오른쪽으로)와 절(clause) 적용에 대한 순서(위에서 아래로)를 모두 암묵적으로 지정합니다.
이는 기본적으로 프로그램이 텍스트로 읽힐 때와 같은 순서로(깊이 우선 방식) 처리하도록 약속하는 방식과 같습니다. 이것은, 특정한 방식으로 프로그램을 작성하면 비종료(non-termination)를 유발할 수 있다는 것으로 연결됩니다. 이 사실은 언어의 일부 비논리적 특징이 '부작용(side-effect)'을 허용한다는 사실과 결합되어, 결국 '제어 흐름' 때문에 '비형식적 추론'이 어려워지는 문제를 피할 수 없게 됩니다.
(이렇게 추론이 어려워지는 문제는 제어를 전혀 지정하지 않는 이상적인 논리 프로그래밍의 세계에서는 발생하지 않습니다. 이는 순수한 Prolog 프로그래밍과는 달리, 그 외의 언어들에서는 제어 흐름을 지정하기 때문입니다.)
As for Prolog’s other extra-logical features, some of them further widen the gap between the language and logic programming in its ideal form. One example of this is the provision of “cuts” which offer explicit restriction of control flow. These explicit restrictions are intertwined with the pure logic component of the system and inevitably have an adverse affect on attempts to reason about the program (misunderstandings of the effects of cuts are recognised to be a major source of bugs in Prolog programs [SS94, p190]).
Prolog의 다른 논리 확장 기능들은, 프로그래밍 언어와 이상적인 형태의 논리 프로그래밍 사이의 격차를 더욱 넓히는데 일조합니다.
한 가지 예를 들자면, 제어 흐름을 명시적으로 제한하는 "cuts" 기능을 들 수 있습니다. 이러한 명시적인 제한은 시스템의 순수한 논리적 컴포넌트와 얽혀 있어, 프로그램에 대한 추론을 시도할 때 불리한 영향을 미칩니다. (cut의 효과에 대한 오해는 Prolog 프로그램의 주요 버그 원인으로 인식되고 있습니다.)
It is worth noting that some more modern languages of the logic programming family offer more flexibility over control than the implicit depth-first search used by Prolog. One example would be Oz which offers the ability to program specific control strategies which can then be applied to different problems as desired. This is a very useful feature because it allows significant explicit control flexibility to be specified separately from the main program (i.e. without contaminating it through the addition of control complexity).
논리 프로그래밍 계열의 최신 언어들 중 어떤 것들은 Prolog에서 사용하는 '암시적 깊이 우선' 탐색보다 더 유연한 제어를 제공한다는 점에 주목할 필요가 있습니다.
한 가지 예로, Oz가 있습니다. Oz는 특정한 제어 전략을 프로그래밍할 수 있도록 하여, 원하는 대로 다른 문제에 적용할 수 있습니다. 이는 메인 프로그램과 별도로 (즉, 제어 복잡성을 추가하여 프로그램을 오염시키지 않고) 상당히 명시적인 제어 유연성을 지정할 수 있기 때문에 매우 유용한 기능입니다.
5.3.3 Summary — Logic Programming
요약 - 논리 프로그래밍
One of the most interesting things about logic programming is that (despite the limitations of some actual logic-based languages) it offers the tantalising promise of the ability to escape from the complexity problems caused by control.
논리 프로그래밍의 가장 흥미로운 점 하나는 (몇몇 로직 기반 언어들의 한계에도 불구하고) 제어로 인한 복잡성 문제에서 벗어날 수 있다는 매력적인 가능성을 제공한다는 것입니다.
6 Accidents and Essence
우발적 복잡성과 본질적 복잡성
Brooks defined difficulties of “essence” as those inherent in the nature of software and classified the rest as “accidents”.
We shall basically use the terms in the same sense — but prefer to start by considering the complexity of the problem itself before software has even entered the picture. Hence we define the following two types of complexity:
[[/people/fred-brooks]]{Brooks}는 소프트웨어의 본질에 내재된 어려움을 "본질적" 어려움으로 정의하고, 나머지를 "우발적" 어려움으로 분류했습니다.
우리는 기본적으로 그와 같은 의미의 용어를 사용할 것입니다. 그러나 소프트웨어라는 틀에 대해 논의하기 전에 문제 자체의 복잡성을 고려하는 것으로 시작하고자 합니다. 따라서 우리는 다음 두 가지 유형의 복잡성을 정의합니다.
Essential Complexity is inherent in, and the essence of, the problem (as seen by the users).
Accidental Complexity is all the rest — complexity with which the development team would not have to deal in the ideal world (e.g. complexity arising from performance issues and from suboptimal language and infrastructure).
- 본질적 복잡성
- 문제의 본질에 내재되어 있으며, 사용자 관점에서 중요한 복잡성.
- 우발적 복잡성
- 본질적 복잡성이 아닌 모든 복잡성.
- 이상적인 세계에서는 개발팀이 처리할 필요가 없는 복잡성
- (예: 성능 문제와 최적화되지 않은 언어와 인프라에서 발생하는 복잡성)을 의미.
Note that the definition of essential is deliberately more strict than common usage. Specifically when we use the term essential we will mean strictly essential to the users’ problem (as opposed to — perhaps — essential to some specific, implemented, system, or even — essential to software in general). For example — according to the terminology we shall use in this paper — bits, bytes, transistors, electricity and computers themselves are not in any way essential (because they have nothing to do with the users’ problem).
'본질적'이라는 용어를 의도적으로 일반적인 사용법보다 더 엄격하게 정의했다는 점에 주목해야 합니다. 특히 '본질적'이라는 용어를 사용할 때는 엄격하게 '사용자의 문제에 본질적'이라는 의미로 사용할 것입니다. 구현된 특정 시스템에 본질적이거나, 심지어 소프트웨어 전반에 본질적이라는 의미가 아닙니다. 예를 들어 이 논문에서 사용하는 용법을 적용하면 비트, 바이트, 트랜지스터, 전기, 컴퓨터 자체는 사용자의 문제와 관련이 없으므로 어떤 방식으로도 '본질적'이지 않습니다.
Also, the term “accident” is more commonly used with the connotation of “mishap”. Here (as with Brooks) we use it in the more general sense of “something non-essential which is present”.
또한, "우발적"이라는 용어는 "실수"라는 의미로 사용되는 경우가 더 흔합니다. 여기에서는 [[/people/fred-brooks]]{Brooks}와 마찬가지로 "이미 존재하는 비본질적인 무언가"이라는 다소 일반적인 의미로 사용합니다.
In order to justify these two definitions we start by considering the role of a software development team — namely to produce (using some given language and infrastructure) and maintain a software system which serves the purposes of its users. The complexity in which we are interested is the complexity involved in this task, and it is this which we seek to classify as accidental or essential. We hence see essential complexity as “the complexity with which the team will have to be concerned, even in the ideal world”.
우리의 이 두 가지 용어 정의를 정당화하기 위해 소프트웨어 개발팀의 역할을 고려해 본다면, '소프트웨어 개발팀'의 역할은 주어진 언어와 인프라를 사용하여 사용자의 목적을 달성하는 소프트웨어 시스템을 생성(생산)하고 유지하는 것이라 할 수 있습니다.
우리가 관심을 갖는 종류의 복잡성은 바로 이러한 작업에 포함된 복잡성이며, 이런 복잡성을 '우발적 복잡성'과 '본질적 복잡성'으로 분류하고자 합니다. 그리고 우리는 본질적인 복잡성을 "이상적인 세계에서도 팀이 신경써야 할 복잡성"으로 정의합니다.
Note that the “have to” part of this observation is critical — if there is any possible way that the team could produce a system that the users will consider correct without having to be concerned with a given type of complexity then that complexity is not essential.
여기에서 "신경써야 할" 부분이 매우 중요합니다. 팀이 특정한 유형의 복잡성에 신경을 쓰지 않고도 '사용자가 올바르다고 인정할 수 있는 시스템'을 만들 수 있다면, 그 복잡성은 본질적인 것이라 할 수 없습니다.
Given that in the real world not all possible ways are practical, the implication is that any real development will need to contend with some accidental complexity. The definition does not seek to deny this — merely to identify its secondary nature.
실제 세계에서 실제로 가능한 방법이라 해서 모두 실용적인 방법인 것이 아니라는 점을 감안하면, 어떠한 실제적인 개발 활동에서도 어느 정도의 우발적 복잡성을 다루어야 할 것입니다. '우발적 복잡성'의 정의는 이런 사실을 부정하려는 것이 아니라, 그것이 부차적인 성격을 갖고 있다는 점을 드러내려는 것입니다.
Ultimately (as we shall see below in section 7) our definition is equivalent to saying that what is essential to the team is what the users have to be concerned with. This is because in the ideal world we would be using language and infrastructure which would let us express the users’ problem directly without having to express anything else — and this is how we arrive at the definitions given above.
(7장에서 살펴보겠지만) 우리의 용어 정의는 결국 '팀에게 본질적인 것'이란 곧 '사용자의 관심사'라고 말하는 것과 마찬가지입니다. 이상적인 세계에서는 사용자의 문제를 직접 표현할 수 있는 언어와 인프라를 사용할 수 있을 것이므로, 앞에서 제시한 정의에 자연스럽게 도달하게 될 것입니다.
The argument might be presented that in the ideal world we could just find infrastructure which already solves the users’ problem completely. Whilst it is possible to imagine that someone has done the work already, it is not particularly enlightening — it may be best to consider an implicit restriction that the hypothetical language and infrastructure be general purpose and domain-neutral.
이상적인 세계에서는 이미 '사용자의 문제를 완전히 해결하는 인프라'가 존재한다는 주장이 있을 수 있습니다.
누군가가 이런 작업을 이미 수행했다고 상상할 수는 있습니다. 하지만 별로 도움이 되는 상상은 아닙니다. 이상적인 언어와 인프라가 범용적이고 도메인 중립적이어야 한다는 암묵적인 제약을 갖는다는 가정을 고려하는 것이 좋을 것입니다.
One implication of this definition is that if the user doesn’t even know what something is (e.g. a thread pool or a loop counter — to pick two arbitrary examples) then it cannot possibly be essential by our definition (we are assuming of course — alas possibly with some optimism — that the users do in fact know and understand the problem that they want solved).
이 정의의 한 가지 의의는 '사용자가 뭔지 전혀 모르고 있는 대상'이 있다면(예를 들어 스레드 풀이나 루프 카운터와 같은 것들), 우리의 정의에 따라서 그것은 본질적인 것이 아니게 된다는 것입니다. (물론 우리는 사용자가 해결하고자 하는 문제를 알고 잘 이해하고 있다고 - 가능한 한 긍정적으로 - 가정하고 있습니다.)
Brooks asserts [Bro86] (and others such as Booch agree [Boo91]) that “The complexity of software is an essential property, not an accidental one”. This would suggest that the majority (at least) of the complexity that we find in contemporary large systems is of the essential type.
Brooks는 "소프트웨어의 복잡성은 우발적인 것이 아니라 본질적인 것이다"라고 주장합니다. (그리고 Booch와 같은 다른 사람들도 이에 동의합니다.) Brooks의 주장은 현대적인 대규모 시스템에서 발견되는 복잡성의 대부분이 본질적인 복잡성이라는 것을 시사합니다.
We disagree. Complexity itself is not an inherent (or essential) property of software (it is perfectly possible to write software which is simple and yet is still software), and further, much complexity that we do see in existing software is not essential (to the problem). When it comes to accidental and essential complexity we firmly believe that the former exists and that the goal of software engineering must be both to eliminate as much of it as possible, and to assist with the latter.
그러나 우리는 [[/people/fred-brooks]]{Brooks}의 주장에 동의하지 않습니다. 복잡성 자체는 소프트웨어의 고유한(본질적인) 속성이 아닙니다. (단순한 소프트웨어를 작성하는 것 자체는 완벽하게 가능합니다.) 또한, 기존 소프트웨어에서 발견되는 복잡성의 대부분은 (문제에 대해) 본질적인 것이 아닙니다.
우리는 우발적 복잡성이 존재한다는 것을 인정하고, 본질적 복잡성을 다루는 일에 도움을 주며, 가능한 한 많은 우발적 복잡성을 제거하는 것이 소프트웨어 공학의 목표가 되어야 한다고 확신합니다.
Because of this it is vital that we carefully scrutinize accidental complexity. We now attempt to classify occurrences of complexity as either accidental or essential.
따라서 우발적인 복잡성을 주의 깊게 조사하는 것이 매우 중요합니다. 이제 우리는 우발적인 복잡성과 본질적인 복잡성으로 복잡성의 발생 사례를 분류하고자 합니다.
7 Recommended General Approach
권장하는 일반적인 접근 방법
Given that our main recommendations revolve around trying to avoid as much accidental complexity as possible, we now need to look at which bits of the complexity must be considered accidental and which essential.
우리의 주요 권장 사항은 우발적인 복잡성을 가능한 한 많이 피하려는 방향을 중심으로 하고 있습니다. 따라서 이제 복잡성의 어떤 부분이 우발적이고, 어떤 부분이 본질적인 것으로 파악해야 하는지 살펴보아야 합니다.
We shall answer this by considering exactly what complexity could not possibly be avoided even in the ideal world (this is basically how we define essential). We then follow this up with a look at just how realistic this ideal world really is before finally giving some recommendations.
우리는 이상적인 세계에서도 피할 수 없는 복잡성(본질적인 복잡성)이 무엇인지를 정확히 살펴보는 것으로 이 질문에 대해 답하려 합니다. 그런 다음 이상적인 환경이 현실과 얼마나 다른지 살펴보고, 마지막으로 몇 가지 권장 사항을 제시하겠습니다.
7.1 Ideal World
이상적인 세계
In the ideal world we are not concerned with performance, and our language and infrastructure provide all the general support we desire. It is against this background that we are going to examine state and control. Specifically, we are going to identify state as accidental state if we can omit it in this ideal world, and the same applies to control.
이상적인 세계에서는 성능에 대해 걱정할 필요가 없으며, 프로그래밍 언어와 인프라는 우리가 원하는 모든 것을 제공한다고 합시다. 우리는 이러한 세계를 전제하고 상태와 제어에 대해 살펴볼 것입니다.
특히, 이상적인 세계에서 생략할 수 있는 상태를 '우발적인 상태'로 분류하고, 제어에 대해서도 동일한 원칙을 적용할 것입니다.
Even in the ideal world we need to start somewhere, and it seems reasonable to assume that we need to start with a set of informal requirements from the prospective users.
이상적인 세계에서도 우리는 여전히 어딘가에서부터 시작해야 합니다. 그렇다면 잠재적인 사용자의 비공식적인 요구 사항부터 시작하는 것이 합리적일 것입니다.
Our next observation is that because we ultimately need something to happen — i.e. we are going to need to have our system processed mechanically (on a computer) — we are going to need formality.
We are going to need to derive formal requirements from the informal ones.
다음으로 우리가 원하는 것은 결국 무언가가 일어나는 것이며, 이는 달리 말해 시스템이 컴퓨터를 통해 기계적으로 처리되어야 한다는 뜻입니다. 때문에 우리에게는 '형식적인 것'이 필요합니다.
So, taken together, this means that even in the ideal world we have:
Informal requirements → Formal requirements
따라서 이 모든 것을 종합해보면 이상적인 세계에서도 다음과 같은 과정이 필요합니다.
비공식적인 요구 사항 → 형식적인 요구 사항
Note that given that we’re aiming for simplicity, it is crucial that the formalisation be done without adding any accidental aspects at all. Specifically this means that in the ideal world, formalisation must be done with no view to execution whatsoever. The sole concern when producing the formal requirements must be to ensure that there is no relevant7 ambiguity in the informal requirements (i.e. that it has no omissions).
우리는 단순함을 목표로 삼고 있기 때문에 형식화 과정에서 우발적인 측면을 전혀 추가하지 않는 것이 매우 중요합니다. 즉, 이상적인 세계에서의 형식화 과정은 '실행'에 대한 고려 없이 이루어져야 합니다. 형식적인 요구 사항을 작성할 때 유일하게 고려해야 할 사항이 있다면, 비공식적인 요구 사항에 관련된7 모호함이 없는지(즉, 누락된 것이 없는지) 확인하는 것 뿐입니다.
So, having produced the formalised requirements, what should the next step be? Given that we are considering the ideal world, it is not unreasonable to assume that the next step is simply to execute these formal requirements directly on our underlying general purpose infrastructure.8
이제 형식화된 요구 사항을 만들었습니다. 다음 단계는 무엇이어야 할까요? 우리가 가정하고 있는 이상적인 세계를 고려한다면, 다음 단계는 이렇게 형식화한 요구사항을 우리의 기반 인프라에서 직접 실행해보는 것이 합리적일 것입니다.8
This state of affairs is absolute simplicity — it does not seem conceivable that we can do any better than this even in an ideal world.
It is interesting to note that effectively what we have just described is in fact the very essence of declarative programming — i.e. that you need only specify what you require, not how it must be achieved.
We now consider the implications of this “ideal” approach for the causes of complexity discussed above.
이러한 상태는 절대적으로 단순합니다. 이상적인 세계에서도 이보다 더 나은 방법은 없을 것 같습니다.
방금 설명한 내용은 사실 선언적 프로그래밍의 본질이라는 점에 주목할 만합니다. 즉, '내가 원하는 것만 명시하면' 되며, '어떻게 수행해야 하는지'는 명시할 필요가 없다는 것입니다.
이제 이러한 "이상적인" 세계를 가정한 접근 방식이 앞에서 설명한 복잡성의 원인에 대해 어떤 의미가 있는지를 생각해 봅시다.
7.1.1 State in the ideal world
이상적인 세계에서의 상태
Our main aim for state in the ideal world is to get rid of it — i.e. we are hoping that most state will turn out to be accidental state.
We start from the perspective of the users’ informal requirements. These will mention data of various kinds — some of which can give rise to state — and it is these kinds which we now classify.
이상적인 세계에서 우리의 주요 목표는 상태를 제거하는 것입니다. 즉, 우리는 대부분의 상태가 우발적으로 발생한 것이라고 기대하고 있습니다.
우리는 사용자의 비형식적인 요구 사항의 관점에서 시작합니다. 이 요구 사항은 여러 종류의 데이터를 언급하는데, 이들 중 일부는 상태를 유발할 수도 있습니다. 우리는 바로 이런 종류의 데이터를 분류하려 합니다.
All data will either be provided directly to the system (input) or derived. Additionally, derived data is either immutable (if the data is intended only for display) or mutable (if explicit reference is made within the requirements to the ability of users to update that data).
모든 데이터는 시스템에 직접 '제공'(입력)되거나 '파생'됩니다. 그리고 '파생'된 데이터는 불변(immutable)이거나(데이터가 표시용으로만 사용되는 경우), 변경 가능(mutable)합니다(요구 사항에서 사용자가 해당 데이터를 업데이트할 수 있는 능력을 명시적으로 언급하는 경우).
All data mentioned in the users’ informal requirements is of concern to the users, and is as such essential. The fact that all such data is essential does not however mean that it will all unavoidably correspond to essential state. It may well be possible to avoid storing some such data, instead dealing with it in some other essential aspect of the system (such as the logic) — this is the case with derived data, as we shall see. In cases where this is possible the data corresponds to accidental state.
사용자의 비형식적 요구 사항에서 언급하는 모든 데이터는 사용자의 관심사이므로 필수적인 데이터입니다.
그러나 이러한 모든 데이터가 필수적이라고 해서, 그런 데이터들이 모두 본질적인 상태에 해당한다는 것을 의미하지는 않습니다.
이러한 데이터 중 어떤 것들은 저장하지 않고, 대신 시스템의 다른 본질적인 부분(예: 로직)에서 처리할 수도 있습니다. 파생된 데이터의 경우가 이에 해당되며, 이에 대해서는 뒤에서 살펴볼 것입니다. 이런 방식이 가능한 경우라면 데이터는 '우발적인 상태'에 해당합니다.
Input Data
입력 데이터
Data which is provided directly (input) will have to have been included in the informal requirements and as such is deemed essential. There are basically two cases:
- There is (according to the requirements) a possibility that the system may be required to refer to the data in the future.
- There is no such possibility.
In the first case, even in the ideal world, the system must retain the data and as such it corresponds to essential state.
In the second case (which will most often happen when the input is designed simply to cause some side-effect) the data need not be maintained at all.
(입력을 통해) 직접 제공된 데이터는 비형식적 요구 사항에 포함되어 있어야 하며, 따라서 필수적인 데이터로 간주됩니다. 기본적으로 두 가지 경우가 있습니다.
- (요구사항에 따라) 시스템이 나중에 데이터를 참조해야 할 가능성이 있는 경우.
- 그런 가능성이 없는 경우.
첫 번째 경우에는 이상적인 세계에서도 시스템이 데이터를 유지해야 하므로, 필수적인 상태에 해당합니다. 두 번째 경우(입력이 단순히 부수 효과를 일으키기 위해 설계된 경우가 대부분)에는 데이터를 전혀 유지할 필요가 없습니다.
Essential Derived Data — Immutable
본질적인 파생 데이터 - 불변
Data of this kind can always be re-derived (from the input data — i.e. from the essential state) whenever required. As a result we do not need to store it in the ideal world (we just re-derive it when it is required) and it is clearly accidental state.
이런 종류의 데이터는 필요할 때마다 (입력데이터, 즉 필수 상태로부터) 언제든지 다시 파생할 수 있습니다. 따라서 이상적인 세계에서는 이런 데이터를 저장할 필요가 없으며(필요할 때마다 다시 파생하면 됨) 우발적인 상태임이 분명합니다.
Essential Derived Data — Mutable
본질적인 파생 데이터 - 변경 가능
As with immutable essential derived data, this can be excluded (and the data re-derived on demand) and hence corresponds to accidental state.
Mutability of derived data makes sense only where the function (logic) used to derive the data has an inverse (otherwise — given its mutability — the data cannot be considered derived on an ongoing basis, and it is effectively input). An inverse often exists where the derived data represents simple restructurings of the input data. In this situation modifications to the data can simply be treated identically to the corresponding modifications to the existing essential state.
본질에서 파생된 불변 데이터와 마찬가지로, 이 데이터는 저장하지 않아도 되므로(필요할 때마다 데이터를 다시 파생시킴) 우발적인 상태에 해당합니다. 파생된 데이터의 '변경 가능성'은 데이터를 파생시키는 데 사용되는 함수(로직)에 역함수가 있는 경우에만 의미가 있습니다. (그렇지 않으면 - 변경 가능성 때문에 - 데이터는 파생되는 것으로 간주할 수 없으며, 이는 사실상 입력이 됩니다). 파생된 데이터가 입력 데이터의 구조를 단순하게 재구축한 경우에는 역함수가 존재하는 경우가 흔합니다. 이런 경우, 데이터에 대한 수정은 기존의 본질적인 상태에 대한 수정과 동일하게 처리할 수 있습니다.
Accidental Derived Data
우발적인 파생 데이터
State which is derived but not in the users’ requirements is also accidental state. Consider the following imperative pseudo-code:
파생되었지만 사용자의 요구사항에는 없는 상태도 우발적인 상태입니다. 다음의 명령형 의사 코드를 살펴봅시다.
procedure int doCalculation(int y) // 'subsidaryCalcCache' is declared and initialized // elsewhere in the code if (subsidaryCalcCache.contains(y) == false) { subsidaryCalcCache.y := slowSubsidaryCalculation(y) } return 3 * (4 + subsidaryCalcCache.y)
The above use of state in the
doCalculationprocedure seems to be unnecessary (in the ideal world), and hence of the accidental variety. We cannot actually be sure without knowing whether and how thesubsidaryCalcCacheis used elsewhere in the program, but for this example we shall assume that there are no other uses aside from initialization. The above procedure is thus equivalent to:
위의 doCalculation 프로시저와 같이 상태를 사용하는 것은 (이상적인 세계에서는) 불필요한 것처럼 보입니다.
따라서 우발적인 상태입니다.
실제로 프로그램의 다른 곳에서 subsidaryCalcCache가 사용되는지 여부와 그 방법을 알지 못하므로 확실하지는 않지만, 이 예제에서는 초기화 이외에 다른 사용이 없다고 가정하겠습니다.
procedure int doCalculation(int y)
return 3 * (4 + slowSubsidaryCalculation(y))
It is almost certain that this use of state would not have been part of the users’ informal requirements. It is also derived. Hence, it is quite clear that we can eliminate it completely from our ideal world, and that hence it is accidental.
이런 방식으로 상태를 사용하는 것은 사용자의 비형식적 요구 사항의 일부가 아니었을 것입니다. 또한, 이 상태는 파생된 것이기도 합니다. 그러므로 이런 상태를 이상적인 세계에서 완전히 제거할 수 있으며, 따라서 이는 우발적인 상태임이 분명합니다.
Summary — State in the ideal world
요약 - 이상적인 세계에서의 상태
For our ideal approach to state, we largely follow the example of functional programming which shows how mutable state can be avoided. We need to remember though that:
상태에 대한 이상적인 세계를 전제한 접근 방식은 주로 함수형 프로그래밍의 예를 따르며, 이는 변경 가능한 상태를 피하는 방법을 보여줍니다. 하지만 기억해둬야 할 것들이 있습니다.
- even in the ideal world we are going to have some essential state — as we have just established
- pure functional programs can effectively simulate accidental state in the same way that they can simulate essential state (using techniques such as the one discussed above in section 5.2.3) — we obviously want to avoid this in the ideal world.
- 이상적인 세계에서도 우리는 방금 본 것처럼 몇 가지 본질적인 상태를 갖게 될 것입니다.
- 순수 함수형 프로그램은 본질적인 상태를 시뮬레이션할 수 있는 것처럼, 우발적인 상태도 효과적으로 시뮬레이션할 수 있습니다(5.2.3절에서 논의하는 방법과 같은 기술을 사용함) - 이상적인 세계에서라면 우리는 이런 상태를 피하고 싶습니다.
The data type classifications are summarized in Table 1. Wherever the table shows data as corresponding to accidental state it means that it can be excluded from the ideal world (by re-deriving the data as required).
데이터 유형 분류는 Table 1에 요약해 두었습니다. 이 표에서 데이터가 우발적인 상태에 해당한다고 표시되는 경우, 이는 필요에 따라 데이터를 다시 파생시켜 이상적인 세계에서는 제외해도 된다는 것을 의미합니다.
Data Essentiality Data Type Data Mutability Classification Essential Input - Essential State Essential Derived Immutable Accidental State Essential Derived Mutable Accidental State Accidental Derived - Accidental State
Table 1: Data and State
| 데이터 본질성 | 데이터 유형 | 변경 가능성 | 구분 |
|---|---|---|---|
| 본질적 | 입력 | - | 본질적 상태 |
| 본질적 | 파생 | 변경 불가 | 우발적 상태 |
| 본질적 | 파생 | 변경 가능 | 우발적 상태 |
| 우발적 | 파생 | - | 우발적 상태 |
Table 1: 데이터와 상태
The obvious implication of the above is that there are large amounts of accidental state in typical systems. In fact, it is our belief that the vast majority of state (as encountered in typical contemporary systems) simply isn’t needed (in this ideal world). Because of this, and the huge complexity which state can cause, the ideal world removes all non-essential state. There is no other state at all. No caches, no stores of derived calculations of any kind. One effect of this is that all the state in the system is visible to the user of (or person testing) the system (because inputs can reasonably be expected to be visible in ways which internal cached state normally is not).
위의 내용이 시사하는 바는 일반적인 시스템에는 많은 양의 우발적인 상태가 있다는 것입니다. 사실, 우리는 (일반적으로 현대적인 시스템에서 볼 수 있는) 대부분의 상태는 (이상적인 세계에서는) 필요하지 않다고 믿습니다. 이러한 이유로, 그리고 상태가 일으킬 수 있는 엄청난 복잡성 때문에 이상적인 세계에서는 모든 비본질적인 상태를 제거합니다. 그 외의 다른 상태는 전혀 존재하지 않는 것입니다. 캐시도 없고, 어떤 종류의 파생 계산 결과도 저장하지 않습니다. 이것의 한 가지 효과는 시스템의 사용자 또는 테스트하는 사람에게 시스템의 모든 상태가 보이게 된다는 것입니다(입력은 일반적으로 내부 캐시 상태와 다르게 보여 구별이 잘 될 것으로 합리적으로 예상할 수 있기 때문입니다).
7.1.2 Control in the ideal world
이상적인 세계에서의 제어
Whereas we have seen that some state is essential, control generally can be completely omitted from the ideal world and as such is considered entirely accidental. It typically won’t be mentioned in the informal requirements and hence should not appear in the formal requirements (because these are derived with no view to execution).
우리는 어떤 상태는 본질적이라는 것을 살펴보았습니다. 그러나 제어는 일반적으로 이상적인 세계에서 완전히 생략될 수 있는 것입니다. 따라서 '제어'는 완전히 우발적이라고 간주됩니다.
일반적으로 비형식적 요구사항에는 제어가 언급되지 않으므로 형식적 요구사항에는 나타나지 않아야 합니다(실행을 고려하지 않고 파생되기 때문입니다).
What do we mean by this? Clearly if the program is ever to run, some control will be needed somewhere because things will have to happen in some order — but this should no more be our concern than the fact that the chances are some electricity will be needed somewhere. The important thing is that we (as developers of the system) should not have to worry about the control flow in the system. Specifically the results of the system should be independent of the actual control mechanism which is finally used.
이것이 의미하는 바는 무엇일까요?
프로그램이 실행되려면 분명히 어떤 순서대로 일이 진행되어야 하므로, 어딘가에서는 제어가 필요할 것입니다. 그러나 이것은 우리가 어딘가에 전기가 필요하다는 사실이나 다를 바 없으며 우리의 관심사가 되어서는 안 됩니다.
중요한 것은 시스템 개발자인 우리가 시스템의 제어 흐름에 대해 걱정할 필요가 없어야 한다는 것입니다. 특히 시스템의 결과는 최종적으로 사용되는 실제 제어 메커니즘과는 독립적이어야 합니다.
These are precisely the lessons which logic programming teaches us, and because of this we would like to take the lead for our ideal approach to control from logic programming which shows that control can be separated completely.
이것이 바로 논리 프로그래밍에서 배울 수 있는 교훈이며, 이 때문에 우리는 이상적인 제어 접근 방식에 대한 지침을 논리 프로그래밍에서 얻고자 합니다. 논리 프로그래밍은 제어를 완전히 분리할 수 있음을 보여줍니다.
It is worth noting that because typically the informal requirements will not mention concurrency, that too is normally of an accidental nature. In an ideal world we can assume that finite (stateless) computations take zero time9 and as such it is immaterial to a user whether they happen in sequence or in parallel.
일반적으로 비형식적인 요구사항에서는 동시성을 언급하지 않습니다. 따라서 동시성 또한 일반적으로 우발적인 성격을 띱니다.
'이상적인 세계'에서는 유한한(상태가 없는) 연산에 0초의 시간이 걸리며,9 이로 인해 연산이 순차적으로 일어나건 병렬적으로 일어나건 사용자에게는 전혀 중요하지 않다고 가정할 수 있을 것입니다.
7.1.3 Summary
요약
In the ideal world we have been able to avoid large amounts of complexity — both state and control. As a result, it is clear that a lot of complexity is accidental. This gives us hope that it may be possible to significantly reduce the complexity of real large systems. The question is — how close is it possible to get to the ideal world in the real one?
이상적인 세계에서는 상태와 제어 양쪽에서 많은 양의 복잡성을 피할 수 있었습니다. 결과적으로 많은 복잡성이 우발적이라는 것이 분명해 졌습니다. 이는 실제 대규모 시스템의 복잡성을 상당히 줄일 수 있을 것이라는 희망을 줍니다.
문제는 현실이 이상적인 세계에 얼마나 근접할 수 있는지입니다.
7.2 Theoretical and Practical Limitations
이론과 실제의 한계
The real world is not of course ideal. In this section we examine a few of the assumptions made in the section 7.1 and see where they break down.
As already noted, our vision of an ideal world is similar in many ways to the vision of declarative programming that lies behind functional and logic programming.
물론 현실세계는 이상적이지 않습니다. 이 섹션에서는 7.1절에서 제시한 몇 가지 가정을 검토하고 어디에 문제가 있는지를 살펴보겠습니다.
이미 언급한 바 있듯이 이상적인 세게에 대한 우리의 비전은 함수형 프로그래밍과 논리 프로그래밍의 기반이 되는 선언적 프로그래밍의 비전과 많은 면에서 유사합니다.
Unfortunately we have seen that functional and logic programming ultimately had to confront both state and control. We should note that the reasons for having to confront each are slightly different. State is required simply because most systems do have some state as part of their true essence. Control generally is accidental (the users normally are not concerned about it at all) but the ability to restrict and influence it is often required from a practical point of view. Additionally practical (e.g. efficiency) concerns will often dictate the use of some accidental state.
불행히도 우리는 함수형 프로그래밍과 논리 프로그래밍이라 하더라도 결국에는 상태와 제어를 모두 다뤄야 한다는 것을 알게 되었습니다. 상태와 제어를 다뤄야 하는 이유가 조금씩 다르다는 점에 유의할 필요가 있습니다. 상태는 일단 대부분의 시스템이 자신의 본질적인 부분으로서 어느 정도의 상태를 가지고 있기 때문에 필요합니다. 제어는 일반적으로 우발적이지만(제어는 사용자의 관심 사항이 아님), 실용적인 관점에서 제어를 제한하고 제어에 영향을 미칠 수 있는 능력은 필요한 경우가 종종 있습니다. 또한, 실용적인 문제(예: 효율성)로 인해 우발적인 상태를 사용해야 할 때도 좀 있습니다.
These observations give some indication of where we can expect to encounter difficulties.
이러한 면들을 통해 어떤 부분에서 어려움을 겪을 수 있는지에 대해 어느 정도 짐작할 수 있습니다.
7.2.1 Formal Specification Languages
형식적 명세 언어
First of all, we want to consider two problems (one of a theoretical kind, the other practical) that arise in connection with the ideal-world formal requirements.
일단 이상적인 세계의 형식적 요구사항과 관련하여 발생하는 두 가지 문제, 즉 이론적인 문제와 실용적인 문제 두 가지를 고려해 보고자 합니다.
In that section we discussed the need for formal requirements derived directly from the informal requirements. We observed that in the ideal world we would like to be able to execute the formal requirements without first having to translate them into some other language.
우리는 앞에서 비형식적 요구 사항에서 직접 파생된 형식적 요구 사항이 필요하다고 논의했습니다. 그리고 이상적인 세계에서는 형식적 요구 사항을 다른 언어로 번역하지 않고도 실행할 수 있으면 좋겠다고 생각했습니다.
The phrase “formal requirements” is basically synonymous with “formal specification”, so what effectively we’re saying would be ideal are executable specifications. Indeed both the declarative programming paradigms discussed above (functional programming and logic programming) have been proposed as approaches for executable specifications.
"형식적 요구사항"이라는 용어는 기본적으로 "형식적 명세"와 동의어이므로, 우리가 말하고자 하는 것은 '실행 가능한 명세'가 이상적이라는 것입니다. 실제로, 위에서 설명한 두 가지 선언적 프로그래밍 패러다임(함수형 프로그래밍과 논리 프로그래밍)은 모두 '실행 가능한 명세'로서의 접근 방식으로 제안되었습니다.
Before we consider the problems with executing them, we want to comment that the way in which the ideal world formal specifications were derived — directly from the users’ informal requirements — was critical. Formal specifications can be derived in various other ways (some of which risk the introduction of accidental complexity), and can be of various different kinds.
우리는 이러한 명세를 실행하는 경우의 문제점을 고려하기 전에, 사용자의 비형식적인 요구 사항으로부터 직접 이상적인 형식적 명세를 도출하는 방식이 중요하다는 점을 언급하고 싶습니다.
형식적 명세의 도출은 여러 가지 다른 방식으로도 가능하며(그 중 몇 가지는 우발적인 복잡성을 도입할 위험이 있습니다), 명세 자체도 다양한 종류가 가능합니다.
Traditionally formal specification has been categorized into two main camps:
통념상 형식적 명세는 크게 두 가지 주요 유형으로 분류됩니다.
Property-based approaches focus (in a declarative manner) on what is required rather than how the requirements should be achieved. These approaches include the algebraic (equational axiomatic semantics) approaches such as Larch and OBJ.
Model-based (or State-based) approaches construct a potential model for the system (often a stateful model) and specify how that model must behave. These approaches (which include Z and VDM) can hence be used to specify how a stateful, imperative language solution must behave to satisfy the requirements. (We discussed the weaknesses of stateful imperative languages in section 5).
속성 기반 접근 방식은 요구 사항을 어떻게 달성해야 하는가보다는 무엇이 요구되는지에 (선언적 방식으로) 초점을 맞춥니다. 이 접근 방식은 (Larch와 OBJ와 같은) 대수적(방정식 공리적 의미론) 접근 방식을 포함합니다.
모델 기반 (또는 상태 기반) 접근 방식은 시스템에 대한 잠재적 모델(대체로 상태 저장 모델)을 구성하고 그 모델이 어떻게 동작해야 하는지를 명시합니다. 따라서 이런 접근 방식(Z, VDM 포함)은 '상태기반 명령형 언어 솔루션'이 요구 사항을 충족시키기 위해 '어떻게 동작해야 하는지를 명시'하는 데 사용할 수 있습니다. (5장에서 상태 기반 명령형 언어의 약점을 논의했습니다.)
The first problem that we want to discuss in this section is the more theoretical one. Arguments (which focus more on the model-based approaches) have been put forward against the concept of executable specifications [HJ89]. The main objection is that requiring a specification language to be executable can directly restrict its expressiveness (for example when specifying requirements for a variable x it may be desirable to assert something like
¬∃y|f(y,x)which clearly has no direct operational interpretation).
이 섹션에서 논의하고자 하는 첫 번째 문제는 좀 더 이론적인 문제입니다. 실행 가능한 명세의 개념에 대한 (모델 기반 접근 방식에 중점을 둔) 반론이 제기된 바 있습니다.
반론의 주요 논거는 명세 언어가 '실행 가능해야 한다'는 조건이 그 언어의 표현력을 직접적으로 제한할 수 있다는 것입니다(예를 들어 변수 x에 대한 요구 사항을 명시할 때, \(\lnot \exists y \vert f(y,x)\) 와 같이 분명히 직접적인 연산적 해석이 없는 것을 단언하는 것이 바람직할 수 있습니다).
In response to this objection, we would say firstly that in our experience a requirement for this kind of expressivity does not seem to be common in many problem domains. Secondly it would seem sensible that where such specifications do occur they should be maintained in their natural form but supplemented with a separate operational component. Indeed in this situation it would not seem too unreasonable to consider the required operational component to be accidental in nature (of course the reality is that in cases like this the boundary between what is accidental and essential, what is reasonable to hope for in an “ideal” world, becomes less clear). Some specification languages address this issue by having an executable subset.
이 반론에 대한 답변은 다음과 같습니다.
- 첫째, 우리의 경험상 이런 종류의 표현력에 대한 요구는 많은 문제 영역에서 흔하지 않습니다.
- 둘째, 이런 명세가 필요한 경우에는, 가능한 한 자연스러운 형태로 유지하면서도 별도의 실행 가능한 컴포넌트로 보완하는 것이 합리적일 것입니다.
실제로 이러한 상황에서는 필요한 연산 구성 요소를 우발적인 것으로 간주하는 것이 그렇게 불합리해 보이지는 않습니다(물론 이런 경우에는 우발적인 것과 본질적인 것의 경계가, 즉 , "이상적인" 세상에서 바랄 수 있는 것과 현실적인 것 사이의 경계가 불분명해집니다).
몇몇 명세 언어는 실행 가능한 하위 집합을 통해 이 문제를 해결합니다.
Finally, it is the property-based approaches that seem to have the greatest similarity to what we have in mind when we talk about executable specifications in the ideal world. It certainly is possible to execute algebraic specifications — deriving an operational semantics by choosing a direction for each of the equational axioms.10
마지막으로, 우리가 이상적인 세계를 배경으로 논의했던 '실행 가능한 명세'와 가장 유사해 보이는 것은 '속성기반 접근방식'입니다. 각 방정식 공리에 대한 해석의 '방향을 선택'하여 연산적 의미를 유도함으로써 '대수적 명세'를 실행할 수 있습니다.10
In summary, the first problem is that consideration of specification languages highlights the (theoretically) fuzzy boundary between what is essential and what is accidental — specifically it challenges the validity of our definition of essential (which we identified closely with requirements from the users) by observing that it is possible to specify things which are not directly executable.
For the reasons given above (and in section 6) we think that — from the practical point of view — our definition is still viable, import and justified.
요약하자면, 첫 번째 문제는 명세 언어에 대한 고려가 본질적인 것과 우발적인 것 사이의 경계가 (이론적으로) 모호하다는 점을 부각시킨다는 것입니다. 특히, 이것은 사용자의 요구사항과 밀접하게 연결된 '본질적인 것'이라는 정의의 유효성에 의문을 제기합니다. 왜냐하면, 직접 실행할 수 없는 것들을 명시하는 것이 가능하다는 것을 우리는 알게 되었기 때문입니다.
위에서 밝힌 이유들(그리고 6장의 내용)에 따라, 우리는 실용적인 관점에서 우리의 정의가 여전히 타당하며, 중요하고, 정당하다고 생각합니다.
The second problem is of a more practical nature — namely that even when specifications are directly executable, this can be impractical for efficiency reasons. Our response to this is that whilst it is undoubtedly true, we believe that it is very important (for understanding and hence for avoiding complexity) not to lose the distinction we have defined between what is accidental and essential. As a result, this means that we will require some accidental components as we shall see in section 7.2.3.
두 번째 문제는 보다 실용적인 성격의 문제로, 명세를 직접 실행하는 것이 가능한 경우에도 '효율'의 측면에서 적합하지 않을 수 있다는 것입니다. 이에 대한 우리의 답변은 같습니다. (사람의 이해를 돕고 복잡성을 피하기 위해) 우발적인 것과 본질적인 것을 구분해 정의한 것을 잃지 않는 것이 매우 중요하다고 생각한다는 것입니다.
즉, 이것은 우리가 필요로 하는 어떤 우발적인 컴포넌트가 필요하다는 것입니다. 이에 대해서는 7.2.3 절에서 살펴보도록 하겠습니다.
7.2.2 Ease of Expression
표현의 용이성
There is one final practical problem that we want to consider — even though we believe it is fairly rare in most application domains. In section 7.1.1 we argued that immutable, derived data would correspond to accidental state and could be omitted (because the logic of the system could always be used to derive the data on-demand).
대부분의 애플리케이션 영역에서는 매우 드물 것 같긴 하지만, 마지막으로 고려해봐야 할 실질적인 문제가 하나 있습니다.
7.1.1 절에서 우리는 '불변성을 갖는 파생 데이터'는 우발적 상태에 해당하므로 생략할 수 있다고 주장했습니다. (시스템의 논리를 사용하여 요청에 따라 언제든지 해당 데이터를 파생시킬 수 있기 때문)
Whilst this is true, there are occasionally situations where the ideal world approach (of having no accidental state, and using on-demand derivation) does not give rise to the most natural modelling of the problem.
이것은 사실이긴 합니다. 그러나 이상적인 세계의 접근 방식(우발적인 상태가 존재하지 않고, 요청에 따라 파생시키는 방식)이 문제를 가장 자연스럽게 모델링하지 못하는 경우가 가끔 있습니다.
One possible situation of this kind is for derived data which is dependent upon both a whole series of user inputs over time, and its own previous values. In such cases it can be advantageous11 to maintain the accidental state even in the ideal world.
그런 상황이 발생할 수 있는 한 가지 경우는, 시간이 지남에 따라 이어지는 사용자의 입력과 그 자체의 이전 값에 모두 의존하는 파생 데이터입니다. 이런 경우에는 이상적인 세계에서도 우발적인 상태를 유지하는 것이 유리11할 수 있습니다.
An example of this would be the derived data representing the position state of a computer-controlled opponent in an interactive game — it is at all times derivable by a function of both all prior user movements and the initial starting positions,12 but this is not the way it is most naturally expressed.
예를 들어 인터랙티브 게임에서 컴퓨터가 제어하는 상대방의 위치 상태를 나타내는 파생 데이터가 있다고 합시다. 이러한 파생 데이터는 이전의 모든 사용자의 움직임과 초기 시작 위치의 함수를 통해서12 언제든지 파생시킬 수 있지만, 이런 것은 가장 자연스러운 표현 방식은 아닙니다.
7.2.3 Required Accidental Complexity
필수적인 우발적 복잡성
We have seen two possible reasons why in practice — even with optimal language and infrastructure — we may require complexity which strictly is accidental. These reasons are:
실제 상황에서는 최적화된 언어와 인프라스트럭처가 구비되어 있더라도, 엄밀히 말해 '우발적인 복잡성'을 필요로 하는 두 가지 이유가 있을 수 있습니다. 그 이유는 다음과 같습니다.
Performance making use of accidental state and control can be required for efficiency — as we saw in the second problem of section 7.2.1.
Ease of Expression making use of accidental state can be the most natural way to express logic in some cases — as we saw in section 7.2.2.
성능 - 7.2.1 절의 두 번째 문제에서 살펴본 것처럼, 효율을 위해 우발적인 상태와 제어 기법을 동원해서 성능을 끌어내는 것이 필요할 수 있습니다.
표현의 용이성 - 7.2.2 절에서 살펴본 것처럼 우발적 상태를 활용하는 표현의 용이성은 경우에 따라 논리를 표현하는 가장 자연스러운 방법이 될 수 있습니다.
Of the two, we believe that performance will be the most common.
It is of course vital to be aware that as soon as we re-introduce this accidental complexity, we are again becoming exposed to the dangers discussed in sections 4.1 and 4.2. Specifically we can see that if we add in accidental state which has to be managed explicitly by the logic of the system, then we become at risk of the possibility of the system entering an inconsistent state (or “bad state”) due to errors in that explicit logic. This is a very serious concern, and is one that we address in our recommendations below.
이 두가지 중에서는 '성능'이 가장 일반적인 경우라고 생각합니다.
물론, 우발적인 복잡성을 다시 도입하게 되면, 4.1절과 4.2절에서 논의한 '위험'에 다시 노출된다는 점을 염두에 두는 것이 중요합니다.
특히 시스템 논리에 의해 명시적으로 관리되어야 하는 우발적인 상태를 추가하면, 명시적 논리의 오류로 인해 시스템이 일관되지 않은 상태(나쁜 상태)로 빠지게 되는 위험에 노출된다는 것을 알 수 있습니다.
이는 매우 심각한 문제이며, 아래 권장 사항에서 다루도록 하겠습니다.
7.3 Recommendations
We believe that — despite the existence of required accidental complexity — it is possible to retain most of the simplicity of the ideal world (section 7.1) in the real one. We now look at how this might be achievable.
우리는 우발적인 복잡성이 존재하더라도 이상적인 세계의 단순성(7.1절)을 실제 세계에서도 대부분 유지할 수 있다고 믿습니다. 이제 이것이 어떻게 가능할지 살펴보겠습니다.
Our recommendations for dealing with complexity (as exemplified by both state and control) can be summed up as:
- Avoid
- Separate
(상태와 제어를 통해 살펴본 바와 같이) 복잡성을 처리하기 위한 권장 사항은 다음과 같습니다.
- 복잡성 피하기
- 복잡성 분리하기
Specifically the overriding aim must be to avoid state and control where they are not absolutely and truly essential.
특히 가장 중요한 목표는, 절대적으로 본질적인 경우가 아니고 진짜로 필요한 곳이 아닌 곳에서는 '상태'와 '제어'를 피하는 것입니다.
The recommendation of avoidance is however tempered by the acknowledgement that there will sometimes be complexity that either is truly essential (section 7.1.1) or, whilst not truly essential, is useful from a practical point of view (section 7.2.3). Such complexity must be separated out from the rest of the system — and this gives us our second recommendation.
그러나 이렇게 회피하는 것을 '권장'하는 것은, 때때로 복잡성이 정말로 본질적이거나(7.1.1절) 진짜로 본질적이지는 않지만 실제적인 관점에서 유용한 경우(7.2.3절)가 있음을 인정하고 있기 때문입니다. 이러한 복잡성은 시스템의 나머지 부분으로부터 '분리'되어야 합니다. 따라서 우리는 두 번째 권장사항을 제시합니다.
There is nothing particularly profound in these recommendations, but they are worth stating because they are emphatically not the way most software is developed today. It is the fact that current established practice does not use these as central overriding principles for software development that leads directly to the complexity that we see everywhere, and as already argued, it is that complexity which leads to the software crisis13.
이 권장 사항들은 대단히 심오한 것들은 아닙니다. 그러나 현재 대부분의 소프트웨어 개발이 이런 방식으로 이루어지지 않기 때문에, 이런 권장 사항을 명확히 언급하는 것이 중요합니다.
현재의 관행은 이런 원칙들을 소프트웨어 개발의 가장 중요한 원칙으로 사용하고 있지 않습니다. 따라서 어디에서나 흔하게 '복잡성'이 나타나게 되고, 이미 논의한 바와 같이 이러한 복잡성이 소프트웨어의 위기로 이어지게 되는 것입니다.13
In addition to not being profound, the principles behind these recommendations are not really new. In fact, in a classic 1979 paper Kowalski(co-inventor of Prolog) argued in exactly this direction [Kow79]. The title of his paper was the equation:
“Algorithm = Logic + Control”
…and this separation that he advocated is close to the heart of what we’re recommending.
이러한 권장 사항들은 심오한 것이 아니라는 점 외에도, 이 권장 사항들의 근본적인 원칙들은 사실 그닥 새로운 것은 아닙니다. Kowalski(Prolog의 공동 발명자)는 1979년 논문에서 정확히 이와 같은 방향의 주장을 한 바 있습니다. 그의 논문 제목은 바로 이 방정식이었습니다.
"알고리즘 = 논리 + 제어"
…그리고 그가 주장한 이러한 '분리'는 우리가 권장하는 것의 핵심에 가깝습니다.
7.3.1 Required Accidental Complexity
필수적인 우발적 복잡성
In section 7.2.3 we noted two possible reasons for requiring accidental complexity (even in the presence of optimal language and infrastructure). We now consider the most appropriate way of handling each.
7.2.3 절에서 (최적의 언어와 인프라가 존재하는 상황에서도) 우발적 복잡성을 필요로 하는 두 가지 이유를 살펴보았습니다. 이제 각각을 처리하는 가장 적절한 방법을 고려해 보겠습니다.
Performance
성능
We have seen that there are many serious risks which arise from accidental complexity — particularly when introduced in an undisciplined manner. To mitigate these risks we take two defensive measures.
우리는 우발적인 복잡성으로 인해 발생하는 많은 심각한 위험들을 보았습니다. 이런 것들은 특히 훈련되지 않은 방식으로 도입될 때 더 위험해집니다. 이러한 위험을 완화하기 위해 두 가지 방어적인 조치를 취할 수 있습니다.
The first is with regard to the risks of explicit management of accidental state (which we have argued is actually the majority of state). The recommendation here is that we completely avoid explicit management of the accidental state — instead we should restrict ourselves to simply declaring what accidental state should be used, and leave it to a completely separate infrastructure (on which our system will eventually run) to maintain. This is reasonable because the infrastructure can make use of the (separate) system logic which specifies how accidental data must be derived.
첫 번째는 우발적인 상태를 명시적으로 관리하는 것의 위험과 관련된 것입니다(우리는 실제로 이런 종류의 상태가 '상태'의 대부분이라고 주장했습니다). 여기에서는 우발적인 상태를 명시적으로 관리하는 대신, 어떤 종류의 우발적인 상태를 사용해야 하는지 선언하고, 유지 관리는 완전히 별도의 인프라(시스템이 최종적으로 실행될 인프라)에 맡기는 것을 권장합니다. 인프라는 우발적인 데이터를 어떻게 도출해야 하는지 지정하는 (별도의) 시스템 로직을 사용할 수 있기 있으므로, 이런 방식은 합리적입니다.
By doing this we eliminate any risk of state inconsistency (bugs in the infrastructure aside of course). Indeed, as we shall see (in section 7.3.2), from the point of view of the logic of the system, we can effectively forget that the accidental state even exists. More specific examples of this approach are given in the second half of this paper.
이렇게 하면 상태 불일치의 위험(물론 인프라의 버그는 제외)을 제거할 수 있습니다. 실제로 7.3.2절에서 살펴보게 되겠지만, 시스템 논리의 관점에서는 우발적인 상태가 존재한다는 사실도 효과적으로 잊을 수 있습니다. 이러한 접근 방식에 대한 보다 구체적인 예는 이 글의 후반부에 제시됩니다.
The other defensive action we take is “Separate”. We examine separation after first looking at the other possible reason for requiring accidental complexity.
그리고 또다른 방어 조치는 "분리"입니다. 우발적인 복잡성을 필요로 하는 또 다른 이유를 먼저 살펴본 후, '분리'에 대해서 살펴보겠습니다.
Ease of Expression
표현의 용이성
This problem (see section 7.2.2) fundamentally arises when derived (i.e. accidental) state offers the most natural way to express parts of the logic of the system.
이 문제(섹션 7.2.2 참고)는 근본적으로 파생된 상태(즉, 우발적인 상태)가 시스템의 논리의 일부를 표현하는 가장 자연스러운 방법을 제공할 때 발생합니다.
The difficulty then arises that this requirement (to use the accidental state in a fairly direct manner inside the system logic) clashes with the goal of separation that we have just discussed. This very separation is critical when it comes to avoiding complexity, so we do not want to sacrifice it for this (probably fairly rare) situation.
문제는 이러한 요구 사항(시스템 논리 내에서 상당히 직접적인 방식으로 우발적인 상태를 사용하는 것)이 방금 논의한 '분리'라는 목표와 충돌한다는 것입니다. '분리'는 복잡성을 피하는 데 있어 매우 중요하므로, 이런 드문 상황 때문에 분리를 포기하고 싶지는 않습니다.
Instead what we recommend is that, in cases where it really is the only natural thing to do, we should pretend that the accidental state is really essential state for the purposes of the separation discussed below. One straightforward way to do this is to make use of an external component which observes the derived data in question and creates the illusion of the user typing that same (derived, accidental) data back in as input data (we touch on this issue again in section 9.1.4).
따라서 우리가 권장하는 것은, 그것이 정말 자연스러운 유일한 방법이라면 아래에서 논의할 '분리'의 목적에 맞추어 우발적인 상태를 마치 본질적인 상태인 것처럼 다루는 것입니다.
이를 위한 간단한 방법 중 하나는 해당 파생 데이터를 관찰하고 사용자가 동일한(파생된, 우발적인) 데이터를 다시 입력 데이터로 입력하는 것처럼 보이도록 하는 외부 컴포넌트를 사용하는 것입니다(이 문제에 대해서는 9.1.4절에서 다시 다루겠습니다).
7.3.2 Separation and the relationship between the components
7.3.2 분리와 컴포넌트 간의 관계
In the above we deliberately glossed over exactly what we meant by our second recommendation: “Separate”. This is because it actually encompasses two things.
위에서는 두 번째 권장 사항인 '분리'의 정확한 의미를 의도적으로 생략했습니다. 이것은 사실 두 가지를 포괄하기 때문입니다.
The first thing that we’re doing is to advocate separating out all complexity of any kind from the pure logic of the system (which — having nothing to do with either state or control — we’re not really considering part of the complexity). This could be referred to as the logic / state split (although of course state is just one aspect of complexity — albeit the main one).
우리가 하는 첫 번째 일은 시스템의 순수한 논리에서 모든 복잡성을 분리하는 것을 주장하는 것입니다(이런 순수한 논리는 상태나 제어와는 관련이 없으므로, 우리는 이것을 복잡성의 일부로 보지 않습니다). 이것을 논리/상태 분할이라고 할 수 있습니다(물론 복잡성의 한 측면에 불과하긴 하지만 '상태'는 중요한 측면입니다).
The second is that we’re further dividing the complexity which we do retain into accidental and essential. This could be referred to as the accidental / essential split. These two splits can more clearly be seen by considering the Table 2. (N.B. We do not consider there to be any essential control).
두 번째는 우리가 보유하고 있는 복잡성을 우발적인 것과 본질적인 것으로 세분화하는 것입니다. 이것을 우발적/본질적 분할이라고 할 수 있습니다. 이 두 가지 분할은 Table 2를 통해 더욱 명확하게 알 수 있습니다.(참고: 우리는 본질적이어야 하는 종류의 제어는 고려하지 않습니다)
Complexity Type Recommendation Essential Logic Separate Essential Complexity State Separate Accidental Useful Complexity State / Control Separate Accidental Useless Complexity State / Control Avoid Table 2: Types of complexity within a system
| 복잡성 | 유형 | 권장 |
|---|---|---|
| 본질적 논리 | 분리 | |
| 본질적 복잡성 | 상태 | 분리 |
| 유용한 우발적 복잡성 | 상태 / 제어 | 분리 |
| 쓸모없는 우발적 복잡성 | 상태 / 제어 | 회피 |
Table 2: 시스템 내의 복잡성의 유형
The essential bits correspond to the requirements in the ideal world of section 7.1 — i.e. we are recommending that the formal requirements adopt the logic / state split.
'본질적' 부분들은 7.1절에서 언급한 이상적인 세계에서의 요구사항에 해당합니다. 즉, 우리는 형식적인 요구사항이 논리와 상태의 분할을 채택하도록 권장하고 있습니다.
The top three rows of the table correspond to components which we expect to exist in most practical systems (some systems may not actually require any essential state, but we include it here for generality). i.e. These are the three things which will need to be specified (in terms of a given underlying language and infrastructure) by the development team.
표의 위에 있는 세 줄은 대부분의 실제 시스템에 존재할 것으로 예상되는 컴포넌트에 해당합니다(일부 시스템은 실제로 본질적인 상태가 필요하지 않을 수도 있지만, 일반성을 위해 여기에 포함시켰습니다). 즉, 개발 팀에서 (주어진 기반 언어와 인프라에 대해) 지정해야 하는 세 가지 요소입니다.
“Separate” is basically advocating clean distinction between all three of these components. It is additionally advocating a split between the state and control components of the “Useful” Accidental Complexity — but this distinction is less important than the others.
"분리"는 기본적으로 이 세 가지 컴포넌트들 간의 명확한 구분을 강조합니다. 또한 "유용한" 우발적 복잡성의 상태 컴포넌트와 제어 컴포넌트 사이의 분리도 이야기하고 있지만, 이 구분은 다른 것보다는 상대적으로 덜 중요합니다.
One implication of this overall structure is that the system (essential + accidental but useful) should still function completely correctly if the “accidental but useful” bits are removed (leaving only the two essential components) — albeit possibly unacceptably slowly. As Kowalski (who — writing in a Prolog-context — was not really considering any essential state) says:
“The logic component determines the meaning …whereas the control component only affects its eciency”.
이러한 전체 구조의 한 가지 함축된 의미는 '우발적이지만 유용한' 부분을 제거한다 하더라도(즉, 두 가지 필수적인 컴포넌트만 남겨둠으로써) 시스템(본질적 + 우발적이지만 유용한)이 완전히 정확하게 작동해야 한다는 것입니다. (단, 이렇게 하면 시스템이 불편할 정도로 느리게 작동할 수도 있습니다.)
Prolog 기준으로 글을 썼기 때문에 본질적인 상태를 고려하지 않았던 Kowalski는 다음과 같이 말한 바 있습니다.
"논리 컴포넌트는 의미를 결정하는 반면… 제어 컴포넌트는 효율성에만 영향을 미칩니다."
A consequence of separation is that the separately specified components will each be of a very different nature, and as a result it may be ideal to use different languages for each. These languages would each be oriented (i.e. restricted) to their specific goal — there is no sense in having control specification primitives in a language for specifying state. This notion of restricting the power of the individual languages is an important one — the weaker the language, the more simple it is to reason about. This has something in common with the ideas behind “Domain Specific Languages” — one exception being that the domains in question are of a fairly abstract nature and combine to form a general-purpose platform.
분리의 결과로, 개별적으로 지정된 컴포넌트들은 각자 매우 다른 성격을 갖게 됩니다. 결과적으로 각 컴포넌트에 대해 다른 언어를 사용하는 것이 이상적일 수 있습니다. 이러한 언어는 각각 특정한 목표를 지향(즉, 제한)하게 될 것이며, 상태를 지정하기 위한 언어에 제어 명세 원시(primitive)가 있는 것은 의미가 없습니다. 개별 언어의 능력을 제한하는 이러한 개념은 중요합니다. 언어의 능력이 약할수록 추론이 더 간단해지기 때문입니다.
이는 "Domain Specific Languages"라는 아이디어의 배경과 몇 가지 공통점이 있습니다. 단, 여기에서는 문제 대상 도메인이 상당히 추상적이며, 이들이 결합해 일반적인 목적의 플랫폼을 형성하는 것이 예외적인 경우입니다.
The vital importance of separation comes simply from the fact that it is separation that allows us to “restrict the power” of each of the components independently. The restricted power of the respective languages with which each component is expressed facilitates reasoning about them individually. The very fact that the three are separated from each other facilitates reasoning about them as a whole (e.g. you do not have to think about accidental state at all when you are working on the essential logic of your system14).
분리의 중요성은 분리를 통해서만 각 컴포넌트의 능력을 독립적으로 "제한"할 수 있다는 사실에서 비롯됩니다. 각 컴포넌트를 표현하는 각 언어의 능력에 제한이 있으면, 각각에 대해 추론하기가 쉬워집니다.
이 세 가지가 서로 분리되어 있다는 사실 자체가, 전체적으로 컴포넌트들에 대한 추론을 쉽게 해줍니다(예: 시스템의 본질적인 논리에 대해 작업할 때는 우발적인 상태에 대해 생각할 필요가 전혀 없습니다14).
Figure 1 shows the same three expected components of a system in a different way (compare with Table 2). Each box in the diagram corresponds to some aspect of the system which will need to be specified by the development team. Specifically, it will be necessary to specify what the essential state can be, what must always be logically true, and finally what accidental use can be made of state and control (typically for performance reasons).
The differing nature of what is specified by each of the components leads naturally to certain relationships between them, to restrictions on the ways in which they can or cannot refer to each other. These restrictions are absolute, and because of this provide a huge aid to understanding the different components of the system independently.
Figure 1은 동일한 세 가지 시스템 컴포넌트를 다른 방식으로 보여줍니다(Table 2와 비교해볼 것). 이 다이어 그램의 각 상자들은 개발팀에서 지정해야 하는 시스템의 어떤 측면을 나타냅니다. 구체적으로는, 본질적인 상태가 무엇인지, 항상 논리적으로 참이어야 하는 것이 무엇인지, 마지막으로 상태와 제어에 대해 우발적으로 사용할 수 있는 것이 무엇인지(일반적으로 성능상의 이유로)를 지정해야 합니다.
각 컴포넌트에 의해 지정된 것의 특성이 다르면 자연스럽게 컴포넌트들 간의 특정한 관계, 즉 서로 참조할 수 있거나 참조할 수 없는 방식에 대한 제한이 생깁니다. 이러한 제한은 절대적이기 때문에 시스템의 각 컴포넌트를 독립적으로 이해하는 데 큰 도움이 됩니다.
Figure 1: Recommended Architecture (arrows show static references)
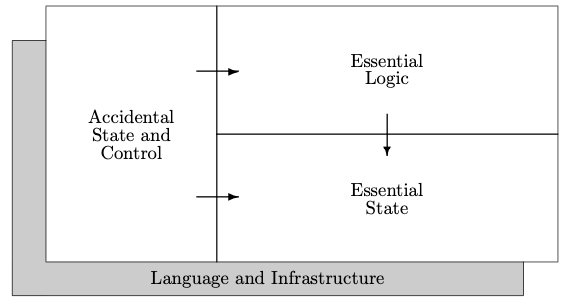
Essential State This can be seen as the foundation of the system. The specification of the required state is completely self-contained — it can make no reference to either of the other parts which must be specified. One implication of this is that changes to the essential state specification itself may require changes in both the other specifications, but changes in either of the other specifications may never require changes to the specification of essential state.
본질적인 상태
이것은 시스템의 기초라 할 수 있습니다. 본질적 상태의 명세는 완전히 독립적이며, 이 컴포넌트는 다른 컴포넌트들을 참조할 수 없습니다. 이것은 본질적 상태 명세의 변경이 다른 두 명세의 변경을 요구할 수 있지만, 다른 명세의 변경은 본질적 상태 명세의 변경을 요구하지 않는다는 것을 의미합니다.
Essential Logic This is in some ways the “heart” of the system — it expresses what is sometimes termed the “business” logic. This logic expresses — in terms of the state — what must be true. It does not say anything about how, when, or why the state might change dynamically — indeed it wouldn’t make sense for the logic to be able to change the state in any way.
Changes to the essential state specification may require changes to the logic specification, and changes to the logic specification may require changes to the specification for accidental state and control. The logic specification will make no reference to any part of the accidental specification. Changes in the accidental specification can hence never require any change to the essential logic.
본질적 논리
이것은 어떤 면에서 시스템의 "심장"이라 할 수 있으며, "비즈니스 로직"이라 부르는 것을 표현합니다. 이 논리는 상태의 관점에서 무엇이 참이어야 하는지를 표현합니다. 이 논리는 상태가 언제, 어떻게, 왜 동적으로 변경될 수 있는지에 대해서는 아무것도 말하지 않습니다. 실제로 논리가 어떤 방식으로든 '상태를 변경'하는 것은 의미가 없습니다.
본질적인 상태 명세를 변경하면 논리 명세 또한 변경해야 할 수 있으며, 논리 명세를 변경하려면 우발적인 상태와 제어에 대한 명세도 변경해야 할 수 있습니다. 논리 명세는 우발적인 명세의 어떤 부분도 참조하지 않습니다. 따라서 우발적인 명세의 변경은 본질적인 논리에 대한 어떤 변경도 요구하지 않습니다.
Accidental State and Control This (by virtue of its accidental nature) is conceptually the least important part of the system. Changes to it can never affect the other specifications (because neither of them make any reference to any part of it), but changes to either of the others may require changes here.
우발적인 상태와 제어
이것은 (우발적인 특성으로 인해) 개념상 시스템에서 가장 중요하지 않은 부분입니다. 이 부분을 변경해도 다른 명세에는 영향을 미치지 않지만(다른 명세는 이 부분을 참조하지 않기 때문), 다른 명세를 변경하면 이 부분도 변경해야 할 수 있습니다.
Together the goals of avoid and separate give us reason to hope that we may well be able to retain much of the simplicity of the ideal world in the real one.
회피와 분리라는 목표는 우리가 실제 세계에서도 이상적인 세계의 단순함을 유지할 수 있을 것이라는 희망을 가질 수 있도록 해줍니다.
7.4 Summary
This first part of the paper has done two main things. It has given arguments for the overriding danger of complexity, and it has given some hope that much of the complexity may be avoided or controlled.
이 논문의 첫 번째 부분에서는 두 가지 중요한 작업을 이야기했습니다. 복잡성의 가장 중요한 위험성에 대한 논거를 제시했으며, 복잡성의 상당 부분을 피하거나 제어할 수 있을 것이라는 희망을 제시했습니다.
The key difference between what we are advocating and existing approaches (as embodied by the various styles of programming language) is a high level separation into three components — each specified in a different language15. It is this separation which allows us to restrict the power of each individual component, and it is this use of restricted languages which is vital in making the overall system easier to comprehend (as we argued in section 4.4 — power corrupts).
우리가 제안하는 접근방식과 기존의 접근방식(다양한 프로그래밍 언어의 스타일로 구현됨15) 사이의 주요한 차이점은 세 가지 컴포넌트로의 고수준 분리라 할 수 있습니다.
이러한 분리를 통해 각각의 컴포넌트의 힘을 제한할 수 있으며, 이렇게 제한된 언어의 사용은 전체 시스템을 이해하기 쉽게 만드는 데 매우 중요합니다. (4.4절에서 주장한 바와 같이 절대 권력은 부패합니다.)
Doing this separation when building a system may not be easy, but we believe that for any large system it will be significantly less difficult than dealing with the complexity that arises otherwise.
시스템을 구축할 때 이러한 분리를 수행하는 것은 쉽지 않을 수 있습니다. 그러나 대규모 시스템의 경우 이런 분리가 없을 때 발생하게 될 복잡성을 다루는 것보다는, 분리를 하는 것이 훨씬 쉬울 것이라고 믿습니다.
It is hard to overstate the dangers of complexity. If it is not controlled it spreads. The only way to escape this risk is to place the goals of avoid and separate at the top of the design objectives for a system. It is not sucient simply to pay heed to these two objectives — it is crucial that they be the overriding consideration. This is because complexity breeds complexity and one or two early “compromises” can spell complexity disaster in the long run.
복잡성의 위험은 아무리 강조해도 지나치지 않습니다. 복잡성을 제어하지 않는다면 결국 퍼져나가게 됩니다. 이러한 위험에서 벗어날 수 있는 유일한 방법은 시스템의 설계 목표의 최상단에 회피와 분리라는 목표를 두는 것입니다. 이 두 가지 목표에 단순하게 주의를 기울이는 정도로는 충분하지 않습니다. 이 두 가지 목표를 최우선으로 고려하는 것이 중요합니다. 복잡성은 복잡성을 낳기 때문에, 초기의 한두 가지 "타협"은 장기적으로 복잡성의 재앙을 불러올 수 있습니다.
It is worth noting in particular the risks of “designing for performance”. The dangers of “premature optimisation” are as real as ever — there can be no comparison between the diculty of improving the performance of a slow system designed for simplicity and that of removing complexity from a complex system which was designed to be fast (and quite possibly isn’t even that because of myriad ineciencies hiding within its complexity).
In the second half of this paper we shall consider a possible approach based on these recommendations.
특히 '성능을 위한 설계'의 위험성에 주목할 필요가 있습니다. '조기 최적화'의 위험은 여전히 실존합니다. 단순성을 위해 설계한 느린 시스템의 성능을 개선하는 것과, 빠른 성능을 위해 설계한 복잡한 시스템에서 복잡성을 제거하는 것의 어려움은 비교할 수 없는 것입니다. (심지어 복잡성 속에 숨어있는 무수한 비효율 때문에 해당 시스템의 속도가 빠르지 않을 수도 있습니다.)
이 글의 후반부에서는 이러한 권고사항을 기반으로 한 접근 방식을 고려해 보겠습니다.
8 The Relation Model
관계형 모델
The relational model [Cod70] has — despite its origins — nothing intrinsically to do with databases. Rather it is an elegant approach to structuring data, a means for manipulating such data, and a mechanism for maintaining integrity and consistency of state. These features are applicable to state and data in any context.
관계형 모델은 그 기원과 달리, 본질적으로는 데이터베이스와 아무런 관련이 없습니다. 오히려 데이터를 구조화하는 우아한 접근 방식이자 데이터를 조작하는 수단이며, 상태의 무결성과 일관성을 유지하기 위한 메커니즘이라 할 수 있습니다. 이러한 기능은 모든 컨텍스트의 상태와 데이터에 적용할 수 있습니다.
In addition to these three broad areas [Cod79, section 2.1], [Dat04, p109], a fourth strength of the relational model is its insistence on a clear separation between the logical and physical layers of the system. This means that the concerns of designing a logical model (minimizing the complexity) are addressed separately from the concerns of designing an ecient physical storage model and mapping between that and the logical model16. This principle is called data independence and is a crucial part of the relational model [Cod70, section 1.1].
이 세가지의 광범위한 영역 외에도 관계형 모델의 네 번째 강점은 논리적 계층과 물리적 계층을 명확하게 분리한다는 점입니다. 즉, (복잡성을 최소화하는) 논리적 모델을 설계하는 문제와 효율적인 물리적 스토리지 모델을 설계하고, 이런 물리적 모델과 논리적 모델의 매핑을 하는 문제는 별개로 다루어집니다.16 이 원칙을 데이터 독립성이라 하며 관계형 모델의 중요한 부분입니다.
We see the relational model as having the following four aspects:
Structure the use of relations as the means for representing all data
Manipulation a means to specify derived data
Integrity a means to specify certain inviolable restrictions on the data
Data Independence a clear separation is enforced between the logical data and its physical representation
관계형 모델에는 다음과 같은 네 가지 측면이 있습니다.
- 구조 모든 데이터를 표현하는 수단으로서의 관계의 사용.
- 조작 파생 데이터를 지정하는 수단.
- 무결성 데이터에 대한 특정한 불변 제약을 지정하는 수단.
- 데이터 독립성 논리적 데이터와 물리적 표현 사이에 명확한 분리가 강제됨.
We will look briefly at each of these aspects. [Dat04] provides a more thorough overview of the relational model.
As a final comment, it is widely recognised that SQL (of any version) — despite its widespread use — is not an accurate reflection of the relational model [Cod90, p371, Serious flaws in SQL], [Dat04, p xxiv] so the reader is warned against equating the two.
이러한 각각의 측면을 간략하게 살펴보도록 합시다. 관계형 모델에 대해서는 [Dat04]에서 더 자세한 내용을 확인할 수 있습니다.
마지막으로, (어떤 버전이건) SQL이 널리 사용되고 있음에도 불구하고 관계형 모델을 정확하게 반영하지 못한다는 것은 널리 알려져 있으므로, 여러분은 이 두 가지를 동일시하지 않도록 주의하기 바랍니다.
8.1 Structure
구조
8.1.1 Relations
관계
As mentioned above, relations provide the sole means for structuring data in the relational model. A relation is best seen as a homogeneous set of records, each record itself consisting of a heterogeneous set of uniquely named attributes (this is slightly different from the general mathematical definition of a relation as a set of tuples whose components are identified by position rather than name).
앞에서 언급했듯이, 관계는 관계형 모델에서 데이터를 구조화하는 유일한 수단을 제공합니다.
관계는 동질적인 레코드의 집합으로 보는 것이 가장 좋으며, 각 레코드 자체는 고유하게 명명된 속성들의 이질적인 집합으로 구성됩니다(이는 컴포넌트가 이름이 아닌 '위치'로 식별되는 '튜플 집합'이라는 관계의 일반적인 수학적 정의와는 약간 다릅니다).
Implications of this definition include the fact that — by virtue of being a set — a relation can contain no duplicates, and it has no ordering. Both of these restrictions are in contrast with the common usage of the word table which can obviously contain duplicate rows (and column names), and — by virtue of being a visual entity on a page — inevitably has both an ordering of its rows and of its columns.
이 정의의 함의는 다음과 같습니다. 관계 또한 집합이기 때문에 중복이 없으며, 순서 또한 없습니다.
이 두 가지 제약 사항은 '테이블'이라는 단어의 일반적인 의미와 대조적입니다. 테이블은 중복된 행(및 열의 이름)을 포함할 수 있고, 페이지의 시각적 엔티티이기 때문에 필연적으로 행과 열의 순서가 있습니다.
Relations can be of the following kinds:
Base Relations are those which are stored directly
Derived Relations (also known as Views) are those which are defined in terms of other relations (base or derived) — see section 8.2
관계는 다음과 같은 종류가 있습니다.
- 기본 관계 - 직접 저장되는 관계.
- 파생 관계 - (view 라고도 부름)는 다른 관계(기본 또는 파생)의 관점에서 정의되는 관계. 자세한 내용은 8.2절 참고.
Following Date [Dat04] it is useful to think of a relation as being a single (albeit compound) value, and to consider any mutable state not as a “mutable relation” but rather as a variable which at any time can contain a particular relation value. Date calls these variables relation variables or relvars, leading to the terms base relvar and derived relvar, and we shall use this terminology later. (Note however that our definition of relation is slightly different from his in that — following standard static typing practice — we do not consider the type to be part of the value).
Date17에 따르면, 관계는 단일(복합이긴 하지만) 값으로 생각하고, 변경 가능한 상태를 "변경 가능한 관계"가 아니라 언제든지 특정한 관계 값을 포함할 수 있는 변수로 여기는 것이 유용합니다.
Date는 이러한 변수를 관계 변수 또는 relvar라고 부르며, 기본(base) relvar 와 파생(derived) relvar라는 용어를 사용합니다. 우리도 이러한 용어를 이후에도 사용할 것입니다(단, 표준 정적 타이핑 관행에 따라 타입을 값의 일부로 간주하지 않기 때문에, 이 정의는 Date의 정의와 약간 다릅니다).
8.1.2 Structuring benefits of Relations — Access path independence
관계의 구조화 이점 - 접근 경로 독립성
The idea of structuring data using relations is appealing because no subjective, up-front decisions need to be made about the access paths that will later be used to query and process the data.
데이터를 관계를 사용하여 구조화하는 아이디어는 매력적인데, 그 이유는 데이터를 쿼리하고 처리하기 위해 이후에 사용할 접근 경로에 대해 미리 주관적인 결정을 내릴 필요가 없기 때문입니다.
To understand what is meant by access path, let us consider a simple example. Suppose we are trying to represent information about employees and the departments in which they work. A system in which choosing the structure for the data involves setting up “routes” between data instances(such as from a particular employee to a particular department) is access path dependent.
'접근 경로'가 무엇을 의미하는지 이해를 돕기 위해 간단한 예를 들어 보겠습니다. 직원들과 그들이 근무하는 부서에 대한 정보를 표현하려 한다고 생각해 봅시다. 데이터 구조를 결정하는 과정에서 데이터 인스턴스간의 '경로'(예: 특정 직원에서 특정 부서로의 연결)를 설정하는 시스템은 접근 경로에 의존적이라 할 수 있습니다.
The two main data structuring approaches which preceded the relational model (the network and hierarchical models) were both access path dependent in this way. For example, in the hierarchical model a subjective choice would be forced early on as to whether departments would form the top level (with each department “containing” its employees) or the other way round (with employees “containing” their departments). The choice made would impact all future use of the data. If the first alternative was selected, then users of the data would find it easy to retrieve all employees within a given department (following the access path), but they would find it harder to retrieve the department of a given employee (and would have to use some other technique corresponding to a search of all departments). If the second alternative was selected then the problem was simply reversed.
관계형 모델이 등장하기 전의 두 가지 주요 데이터 구조화 방식(네트워크 모델과 계층형 모델)은 모두 접근 경로에 의존적이었습니다. 예를 들어, 계층형 모델에서는 부서를 최상위 레벨로 둘지(각 부서가 직원을 '포함'하는 방식), 아니면 그 반대(직원이 부서를 '포함')로 둘 지에 대한 주관적인 선택을 초기에 결정해야만 합니다.
이런 선택은 이후의 모든 데이터 사용에 큰 영향을 미칩니다.
첫 번째 방법을 선택하면 데이터의 사용자는 엑세스 경로를 따라 특정 부서 내의 모든 직원을 쉽게 검색할 수 있습니다. 그러나 특정 직원이 소속된 부서를 검색하는 것은 더 어려워지게 됩니다. 이걸 위해서는 모든 부서를 검색하는 방법을 사용해야 합니다. 그리고 두 번째 방법을 선택하게 되면 문제는 단순히 반대 방향으로 뒤집힐 뿐입니다.
The network model alleviated the problem to some degree by allowing multiple access paths between data instances (so the choice could be made to provide both an access path from department to employee and an access path from employee to department). The problem of course is that it is impossible to predict in advance what all the future required access paths will be, and because of this there will always be a disparity between:
Primary retrieval requirements which were foreseen, and can be satisfied simply by following the provided access paths
Secondary retrieval requirements which were either unforeseen, or at least not specially supported, and hence can only be satisfied by some alternative mechanism such as search
네트워크 모델은 데이터 인스턴스 간에 여러 엑세스 경로를 허용하는 방식으로 이런 문제를 어느 정도 완화했습니다(즉, 부서에서 직원으로 가는 엑세스 경로와 직원에서 부서로 가는 엑세스 경로를 모두 제공할 수 있도록 선택할 수 있습니다). 물론 문제는 미래에 필요한 모든 엑세스 경로가 무엇인지 미리 예측하는 것이 불가능하다는 것이며, 이로 인해 항상 다음과 같은 두 가지 불균형이 발생하게 됩니다.
- 기본 검색 요구사항 - 미리 예측한 요구사항으로, 제공하는 접근 경로를 따라가기만 하면 요구사항을 충족시킬 수 있습니다.
- 부수적 검색 요구사항 - 예상하지 못한 요구사항이거나, 적어도 특별히 지원되지 않은 요구사항이므로, 검색과 같은 대체적인 메커니즘을 사용해야만 요구사항을 충족시킬 수 있습니다.
The ability of the relational model to avoid access paths completely was one of the primary reasons for its success over the network and hierarchical models.
관계형 모델이 네트워크 및 계층형 모델에 비해 성공할 수 있었던 주요한 이유 중 하나는 이런 '접근 경로'를 완전히 피할 수 있었기 때문입니다.
It is also interesting to consider briefly what is involved when taking an object-oriented (OOP) approach to our example. We can choose between the following options:
- Give Employee objects a reference to their Department
- Give Department objects a set (or array) of references to their Employees
- Both of the above
이 사례에 대해 객체지향(OOP) 접근 방식을 적용할 때 어떤 것들이 포함되는지 간단히 살펴보는 것도 흥미로운 것입니다. 다음의 옵션들 중에서 선택할 수 있습니다.
Employee객체에Department에 대한 참조를 추가합니다.Department객체에Employee에 대한 참조 집합(또는 배열)을 추가합니다.- 위의 두 가지 방법을 모두 적용합니다.
If we choose the third option, then we at best expose ourselves to extra work in maintaining the redundant references, and at worst expose ourselves to bugs. There are disturbing similarities between the data structuring approaches of OOP and XML on the one hand and the network and hierarchical models on the other. A final advantage of using relations for the structure — in contrast with approaches such as Chen’s ER-modelling [Che76] — is that no distinction is made between entities and relationships. (Using such a distinction can be problematic because whether something is an entity or a relationship can be a very subjective question).
세 번째 옵션을 선택하면 최소한 중복 참조를 유지관리하는 추가적인 작업에 시달리게 되고, 최악의 경우에는 버그에 노출될 수 있습니다.
한편으로는 OOP와 XML의 데이터 구조화 접근 방식과, 그리고 네트워크 모델과 계층형 모델의 접근 방식 사이에는 불안하게 느껴지는 유사점이 있습니다.18
구조화를 위해 관계를 사용하는 것의 마지막 장점은 - Chen의 ER 모델링과 같은 접근 방식과는 대조적으로 - 엔티티와 관계 사이에 구분을 두지 않는다는 것입니다. (이런 구분을 사용하는 것은 문제가 될 수 있습니다. 무엇이 엔티티이고 무엇이 관계인지는 매우 주관적인 문제가 될 수 있기 때문입니다).
8.2 Manipulation
조작
Codd introduced two different mechanisms for expressing the manipulation aspects of the relational model — the relational calculus and the relational algebra. They are formally equivalent (in that expressions in each can be converted into equivalent expressions in the other), and we shall only consider the algebra.
Codd는 관계형 모델의 조작 측면을 표현하기 위해 관계 해석(relational calculus)과 관계 대수(relational algebra)라는 두 가지 메커니즘을 도입했습니다. 이 두 가지 메커니즘은 (각각의 표현식을 다른 표현식으로 변환할 수 있어) 형식적으로 동등하며, 여기에서는 관계 대수만 살펴보도록 하겠습니다.
The relational algebra (which is now normally considered in a slightly different form from the one used originally by Codd) consists of the following eight operations:
Restrict is a unary operation which allows the selection of a subset of the records in a relation according to some desired criteria
Project is a unary operation which creates a new relation corresponding to the old relation with various attributes removed from the records
Product is a binary operation corresponding to the cartesian product of mathematics
Union is a binary operation which creates a relation consisting of all records in either argument relation
Intersection is a binary operation which creates a relation consisting of all records in both argument relations
Difference is a binary operation which creates a relation consisting of all records in the first but not the second argument relation
Join is a binary operation which constructs all possible records that result from matching identical attributes of the records of the argument relations
Divide is a ternary operation which returns all records of the first argument which occur in the second argument associated with each record of the third argument
관계 대수(현재는 Codd가 처음에 사용한 것과는 좀 다른 형태를 사용합니다)는 다음의 여덟 가지 연산으로 구성됩니다.
- Restrict는 단항 연산으로, 원하는 기준에 따라 관계의 레코드의 부분 집합을 선택할 수 있습니다.
- Project는 단항 연산으로, 레코드에서 여러 속성을 제거하여 이전 관계에 해당하는 새로운 관계를 생성합니다.
- Product는 수학의 데카르트 곱에 해당하는 이항 연산입니다.
- Union은 이항 연산으로, 두 인수 관계의 모든 레코드로 구성된 관계를 생성합니다.
- Intersection은 이항 연산으로, 두 인수 관계의 모든 공통되는 레코드로 구성된 관계를 생성합니다.
- Difference는 이항 연산으로, 첫 번째 인수 관계의 모든 레코드 중 두 번째 인수 관계에는 없는 레코드로 구성된 관계를 생성합니다.
- Join은 이항 연산으로, 인수 관계의 레코드의 동일한 속성을 일치시켜서 생성할 수 있는 모든 레코드를 구성합니다.
- Divide는 삼항 연산으로, 세 번째 인수의 각 레코드와 연관된 두 번째 인수에서 발생하는 첫 번째 인수의 모든 레코드를 반환합니다.
One significant benefit of this manipulation language (aside from its simplicity) is that it has the property of closure — that all operands and results are of the same kind (relations) — hence the operations can be nested in arbitrary ways (indeed this property is inherent in any single-sorted algebra).
이 조작 언어의 중요한 장점 중 하나는 (단순성 외에도) 모든 피연산자와 결과가 같은 종류(관계)라는 폐쇄성을 갖고 있으므로, 연산을 임의의 방식으로 중첩할 수 있다는 것입니다(실제로 이런 속성은 모든 단일 종류의 대수에도 포함되어 있는 것입니다).
8.3 Integrity
무결성
Integrity in the relational model is maintained simply by specifying — in a purely declarative way — a set of constraints which must hold at all times.
Any infrastructure implementing the relational model must ensure that these constraints always hold — specifically attempts to modify the state which would result in violation of the constraints must be either rejected outright or restricted to operate within the bounds of the constraints.
관계형 모델의 무결성은 항상 유지되어야 하는 제약 조건 집합을 순전히 선언적인 방식으로 지정하는 것만으로 유지 가능합니다.
관계형 모델을 구현하는 모든 인프라는 이러한 제약 조건이 항상 유지되도록 해야 하며, 특히 제약 조건 위반으로 이어질 수 있는 '상태 수정 시도'는 완전히 거부되거나 제약 조건 범위 내에서만 작동하도록 제한해야 합니다.
The most common types of constraint are those identifying candidate or primary keys and foreign keys. Constraints may in fact be arbitrarily complex, involve multiple relations, and be constructed from either the relational calculus or the relational algebra. Finally, many commercially available DBMSs provide imperative mechanisms such as triggers for maintaining integrity — such mechanisms suffer from control-flow concerns (see section 4.2) and are not considered to be part of the relational model.
가장 일반적인 제약 조건 유형은 후보 키 또는 기본 키와 외래 키를 식별하는 제약 조건입니다. 사실 제약 조건은 임의로 복잡하게 구성할 수 있으며, 여러 관계를 포함하고 관계 대수 또는 관계 해석으로 구성될 수 있습니다. 마지막으로, 많은 상용 DBMS는 무결성을 유지하기 위한 트리거와 같은 명령형 메커니즘을 제공합니다. 이러한 메커니즘은 제어 흐름 문제(4.2절 참조)가 있으며 관계형 모델의 일부로 간주되지 않습니다.
8.4 Data Independence
데이터 독립성
Data independence is the principle of separating the logical model from the physical storage representation, and was one of the original motivations for the relational model.
It is interesting to note that the data independence principle is in fact a very close parallel to the accidental / essential split recommended above (section 7.3.2). This is one of several reasons that motivate the adoption of the relational model in Functional Relational Programming (see section 9 below).
데이터 독립성은 논리적 모델과 물리적 저장소 표현을 분리하는 원칙으로, 관계형 모델 본래의 동기 중 하나였습니다.
데이터 독립성 원칙은 사실 앞에서 권장한 우발적/본질적 분할(7.3.2절)과 매우 유사하다는 점이 흥미롭습니다. 이는 함수형 관계형 프로그래밍에서 관계형 모델을 채택하게 된 여러 가지 이유 중 하나입니다(아래 9장 참조).
8.5 Extensions
확장
The relational algebra — whilst flexible — is a restrictive language in computational terms (it is not Turing-complete) and is normally augmented in various ways when used in practice. Common extensions include:
General computation capabilities for example simple arithmetical operations, possibly along with user-defined computations.
Aggregate operators such as
MAX,MIN,COUNT,SUM, etc.Grouping and Summarization capabilities to allow for easy application of aggregate operations to relations
Renaming capabilities the ability to generate derived relations by changing attribute names
관계 대수는 유연하긴 하지만 계산의 측면에서는 제한이 있는 언어이며(튜링 완전하지 않음), 실제로 사용할 때는 일반적으로 다양한 방식으로 확장이 됩니다. 일반적인 확장은 다음과 같습니다.
- 일반 연산 가능 - 예를 들어 간단한 산술 연산 같은 사용자 정의 연산과 함께 사용 가능.
- 집계 연산자 -
MAX,MIN,COUNT,SUM등. - 그룹화 및 요약 기능 - 집계 연산을 관계에 쉽게 적용할 수 있도록 함.
- 이름 변경 기능 - 속성 이름을 변경하여 파생된 관계를 생성할 수 있음.
9 Functional Relational Programming
함수형 관계형 프로그래밍
The approach of functional relational programming (FRP19) derives its name from the fact that the essential components of the system (the logic and the essential state) are based upon functional programming and the relational model (see Figure 2).
함수형 관계형 프로그래밍(FRP19)은 접근 방식이 시스템의 본질적인 컴포넌트(논리와 본질적인 상태)가 함수형 프로그래밍과 관계형 모델을 기반으로 한다는 점에서 유래된 이름을 갖고 있습니다(Figure 2 참고).
Figure 2: The components of an FRP system (infrastructure not shown, arrows show dynamic data flow)
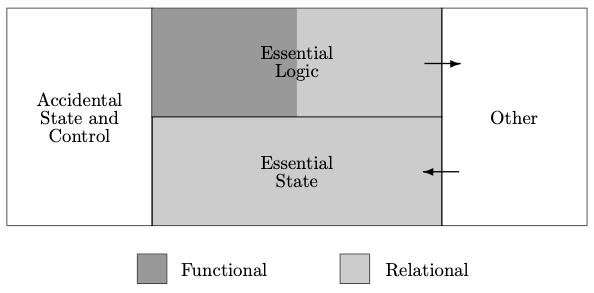
Figure 2: FRP 시스템의 컴포넌트들(인프라는 표시하지 않음, 화살표는 동적 데이터 흐름을 보여줌)
FRP is currently a purely hypothetical20 approach to system architecture that has not in any way been proven in practice. It is however based firmly on principles from other areas (the relational model, functional and logic programming) which have been widely proven.
In FRP all essential state takes the form of relations, and the essential logic is expressed using relational algebra extended with (pure) user-defined21 functions.
The primary, overriding goal behind the FRP architecture (and indeed this whole paper) is of course elimination of complexity.
FRP는 현재 시스템 아키텍처에 대한 순전히 가상의 접근 방식으로,20 실제로는 어떤 방식으로도 입증된 적은 없습니다. 하지만 널리 입증된 다른 분야(관계형 모델, 함수형, 논리 프로그래밍)의 원칙에 확고하게 기반을 두고 있습니다.
FRP에서 모든 본질적인 상태는 관계의 형태를 취하며, 본질적인 논리는 (순수한) 사용자 정의21 함수로 확장된 관계 대수를 사용하여 표현됩니다.
FRP 아키텍처(그리고 이 논문 전체)의 가장 중요한 목표는 물론 복잡성을 제거하는 것입니다.
9.1 Architecture
아키텍처
We describe the architecture of an FRP system by first looking at what must be specified for each of the components when constructing a system in this manner. Then we look at what infrastructure needs to be available in order to be able to construct systems in this fashion.
먼저 이러한 방식으로 시스템을 구축할 때 각 컴포넌트에 대해 지정해야 하는 사항을 살펴보는 방식으로 FRP 시스템의 아키텍처를 설명하겠습니다. 그런 다음 이러한 방식으로 시스템을 구축하기 위해 어떤 인프라를 사용할 수 있어야 하는지 살펴봅니다.
In accordance with the first half of this paper, FRP recommends that the system be constructed from separate specifications for each of the following components:
Essential State A Relational definition of the stateful components of the system
Essential Logic Derived-relation definitions, integrity constraints and (pure) functions
Accidental State and Control A declarative specification of a set of performance optimizations for the system
Other A specification of the required interfaces to the outside world (user and system interfaces)
이 논문의 전반부에서 이야기했던 것들에 따라, FRP는 시스템을 다음과 같은 각 컴포넌트에 대한 별도의 명세로 구성하도록 권장합니다.
- 본질적 상태 - 시스템의 상태를 나타내는 관계 정의
- 본질적 논리 - 파생된 관계 정의, 무결성 제약 조건 및 (순수) 함수
- 우발적 상태 및 제어 - 시스템의 성능 최적화를 위한 선언적 명세
- 기타 - 외부 세계(사용자 및 시스템 인터페이스)와의 인터페이스 명세
Speaking somewhat loosely, the first two components can be seen as corresponding to “State” and “Behaviour” respectively, whilst the third concentrates on “Performance”. In contrast with the object-oriented approach, FRP emphasises a clear separation of state and behaviour.22
약간 느슨하게 말하자면, 첫 번째 두 컴포넌트는 각각 "상태"와 "동작"에 해당한다고 볼 수 있으며, 세 번째는 "성능"에 집중합니다. 객체 지향 접근 방식과는 달리 FRP는 상태와 동작을 명확하게 분리하는 것을 강조합니다.22
9.1.1 Essential State ("State")
본질적 상태("상태")
This component consists solely of a specification of the essential state for the system in terms of base relvars23 (in FRP all state is stored solely in terms of relations — there are no exceptions to this). Specifically it is the names and types of the base relvars that are specified here, not their actual contents. The contents of the relvars (i.e. the relations themselves) will of course be crucial when the system is used, but here we are discussing only the static structure of the system.
In accordance with section 7.1.1, FRP strongly encourages that data be treated as essential state only24 when it has been input directly by a user.25
이 컴포넌트는 base relvar23의 관점에서 시스템의 본질적 상태에 대한 명세로만 구성됩니다(FRP에서 모든 상태는 관계의 형태로만 저장되며, 예외는 없습니다).
특히 여기에서 명시되는 것은 실제 내용이 아니라 base relvar의 이름과 유형입니다. relvar의 내용(즉, 관계 자체)은 시스템이 사용될 때 물론 중요할 것입니다. 하지만 여기서는 시스템의 정적 구조에 대해서만 논의하고 있습니다.
7.1.1절에 따라 FRP는 사용자가 직접 입력한 경우에만 해당 데이터를 본질적 상태로만24 취급할 것을 강력하게 권장합니다. 25
9.1.2 Essential Logic ("Behaviour")
본질적 논리("동작")
The essential logic comprises both functional and algebraic (relational) parts. The main (in the sense that it provides the overall structure for the component) part is the relational one, and consists of derived-relvar names and definitions. These definitions consist of applications of the relational algebra operators to other relvars (both derived relvars and the base relvars which make up the essential state).
본질적인 논리는 함수적 부분과 (관계) 대수적 부분으로 구성됩니다. (컴포넌트의 전체 구조를 제공하는) 주요 부분은 관계형 부분이며, 파생된 relvar 이름과 정의로 구성됩니다. 이러한 정의는 다른 relvar(파생된 relvar 및 본질적 상태를 구성하는 base relvar)에 관계 대수 연산자를 적용한 것으로 구성됩니다.
In addition to the relational algebra, the definitions can make use of an arbitrary set of pure user-defined functions which make up the functional part of the essential logic.
관계 대수 외에도, 정의는 본질적 논리의 함수적 부분을 구성하는 임의의 순수 사용자 정의 함수 집합을 사용할 수 있습니다.
Finally (in accordance with the standard relational model) the logic specifies a set of integrity constraints — boolean expressions which must hold at all times. (These can include everything from simple foreign key constraints to complicated multiple-relvar requirements making use of user-defined functions). Any attempt to modify the essential state (see section 9.1.4) will always be subject to these integrity constraints.
마지막으로 (표준 관계형 모델에 따라) 논리는 항상 유지되어야 하는 boolean 표현식인 무결성 제약 조건 집합을 지정합니다. (여기에는 간단한 외래 키 제약 조건부터 사용자 정의 함수를 사용하는 복잡한 multiple-relvar 요구 사항까지 모든 것이 포함될 수 있습니다.)
본질적 상태를 수정하려는 모든 시도(9.1.4절 참고)는 항상 이러한 무결성 제약 조건의 적용을 받습니다.
Much of the standard theory of relational database design can obviously be used as a guide for the relational parts of these two essential components. For example, normalization of the relvars will allow consistent updates (see section 9.1.4) to the state to be more easily expressed. Note that — assuming no integrity constraints have been accidentally omitted — normalization does not in any way help to preserve the integrity of our relvars — that is after all what the constraints do, and if the constraints are not violated (and the infrastructure must always ensure this) then the relvars have integrity by definition. What is true is that more normalized designs do impose implicit restrictions, and this can reduce the number of (explicit) integrity constraints that must be specified.
관계형 데이터베이스 설계에 대한 표준 이론의 대부분은, 이 두 가지 본질적 컴포넌트의 관계형 부분에 대한 가이드로 사용될 수 있습니다. 예를 들어, relvar들을 정규화하면 상태에 대한 일관된 업데이트(9.1.4절 참고)를 보다 쉽게 표현할 수 있습니다.
무결성 제약 조건을 실수로 누락하지 않았다고 가정할 때, 정규화는 어떤 식으로든 relvar의 무결성을 보존하는 데 도움이 되지 않습니다. 이것은 원래 제약 조건이 하는 일이기 때문에 제약 조건을 위반하지 않는다면(그리고 인프라가 항상 이를 보장한다면) relvar는 정의상 무결성을 갖습니다. 사실 정규화된 설계는 암시적 제한을 부과하기 때문에, 지정해야 하는 (명시적) 무결성 제약 조건의 수를 줄일 수 있습니다.
Having raised the issue of design, it is vital to note that absolutely NO consideration is paid to performance issues of any kind here.
Concepts such as “denormalization for performance” make absolutely no sense in this context because they contain the implicit assumption that the physical storage used will closely mirror the relational structure which is being specified here.
This is absolutely not the case (it is only the accidental state and control component — see below — which is concerned with eciency of storage structures).
설계상의 문제를 제기한 이상, 여기에서는 어떤 종류의 성능 문제도 고려하지 않는다는 사실을 꼭 기억해야 합니다.
"성능을 위한 비정규화" 같은 개념은 여기에서 전혀 의미가 없습니다. 왜냐하면 이러한 개념에는 여기에서 명시하는 관계형 구조와 물리적 저장소가 밀접하게 일치한다는 암묵적 가정이 포함되어 있기 때문입니다.
그것은 우리가 현재 취급하는 대상이 아닙니다(저장 구조의 효율성에 대한 고려는 오직 우연한 상태와 제어 컴포넌트에만 해당됩니다. 아래 참고).
9.1.3 Accidental State and Control ("Performance")
우발적 상태와 제어("성능")
This component fundamentally consists of a series of isolated (in the sense that they cannot refer to each other in any way) performance “hints”. These hints — which should be declarative in nature — are intended to provide guidance to the infrastructure responsible for running the FRP system.
이 컴포넌트는 기본적으로 (서로를 어떤 방식으로든 참조할 수 없는 고립의 의미에서) 분리된 성능 "힌트"들의 시리즈로 구성됩니다. 이러한 "힌트"는 선언적이어야 하며, FRP 시스템 실행을 담당하는 인프라에 지침을 제공하는 것이 목적입니다.
On the state side, this component is concerned with both accidental state itself and accidental aspects of state. Firstly, it provides a means to specify what state (of the accidental variety) should exist. Secondly it provides (if desired) a means to specify what physical storage mechanisms should be used for storing state (of both kinds) — i.e. the accidental aspects of storage. This second aspect is the flexible mapping providing physical / logical data independence as required by the relational model (section 8).
상태의 관점에서, 이 컴포넌트는 우발적 상태 자체와 우발적 상태의 측면 모두에 관련이 있습니다.
- 첫째, 어떤 (우발적)상태가 존재해야 하는지 지정하는 수단을 제공합니다.
- 둘째, (두 가지 종류의) 상태를 저장하기 위해 어떤 물리적 저장 메커니즘을 사용해야 하는지, 즉 저장의 우발적 측면을 지정하는 수단을 제공합니다.
이 두번째 측면은 관계형 모델에서 요구하는 대로 물리적/논리적 데이터 독립성을 제공하는 유연한 매핑입니다(8절 참고).
An example of the first kind of state-related hint might be a simple directive that a particular derived-relvar should actually be stored (rather than continually recalculated), so that it is always quickly available.
첫 번째 상태 관련 힌트의 예로는, 특정 파생 relvar를 계속 다시 계산하지 않고, 실제로 저장해서 항상 빠르게 사용할 수 있게 해야 한다는 간단한 지시문이 있을 수 있습니다.
An example of the second kind of state-related hint might be that an infrequently used subset of the attributes of a particular relvar (either derived or base) should be stored separately for performance reasons. The use of indices or other custom storage strategies would also be examples of this second kind of state-related hint. The exact types of hint available here will depend entirely on what is provided by the underlying infrastructure.
두 번째 상태 관련 힌트의 예로는, 특정 relvar(파생 또는 기본)의 속성 중 자주 사용되지 않는 부분을 성능상의 이유로 별도로 저장해야 한다고 알려주는 것이 있을 수 있습니다. 인덱스나 커스텀 저장 전략을 사용하는 것도 두 번째 유형의 힌트의 예라 할 수 있습니다.
여기에서 사용 가능한 힌트의 정확한 유형은 기반이 되는 인프라가 제공하는 것에 따라 달라집니다.
On the control side, recommendations for parallel evaluation of derived-relvars might be given. Also, declarative hints could be given about whether the derived relvars should be computed eagerly (as soon as the essential state changes), lazily (when the infrastructure is forced to provide them), or some combination of different policies for different relvars.
제어 측면에서는 파생된 relvar의 병렬 평가에 대한 추천을 할 수도 있습니다. 또한 파생된 relvar를 즉시(eagerly) 계산해야 하는지(본질적 상태가 변경되자마자), 게으르게(lazily) 계산해야 하는지(인프라가 제공해야만 하는 경우), 또는 relvar마다 다른 정책의 조합을 사용해야 하는지에 대한 선언적 힌트를 제공할 수 있습니다.
All hints are incapable of referring to each other, but do refer to the relevant (essential, base and derived) relvars by name.
모든 힌트는 서로를 참조할 수는 없지만, 이름을 통해 (본질적, 기본, 파생) 관련된 relvar을 참조할 수 있습니다.
9.1.4 Other (Interfacing)
기타 (인터페이싱)
The primary consideration not addressed by the above is that of interfacing with the outside world.
Specifically, all input must be converted into relational assignments (which replace the old relvar values in the essential state with new ones), and all output (and side-effects) must be driven from changes to the values of relvars (primarily derived relvars).
앞에서 다루지 않은 주요 고려 사항은 외부와의 인터페이싱에 대한 것입니다.
구체적으로, 모든 입력은 관계형 할당으로 변환되어야 합니다(본질적 상태의 relvar 값을 새로운 값으로 대체합니다), 그리고 모든 출력(및 부작용)은 relvar 값의 변경으로부터 발생해야 합니다(주로 파생된 relvar).
The exact nature of this task is likely to be highly application-dependent, but we can say that there will probably be a requirement for a series of feeder (or input) and observer (or output) components. These may well be defined, at least partially, in a traditional, imperative way if custom interfacing is required. There will be cases when it is necessary for a given interfacing component to act in both capacities (if for example a message must be observed and sent to another system, then a response received, recorded and fed back in).
The expectation is that all of these components will be of a minimal nature — performing only the necessary translations to and from relations.
이 작업의 정확한 성격은 애플리케이션에 따라 크게 달라질 수 있지만, 피더(또는 입력)와 옵저버(또는 출력) 컴포넌트에 대한 요구 사항들이 있을 것으로 예상할 수 있습니다. 커스텀 인터페이스가 필요한 경우라면, 이러한 컴포넌트들은 부분적으로라도 전통적인 명령형 방식으로 정의될 수도 있습니다.
특정 인터페이스 컴포넌트가 두 가지 역할을 모두 수행해야 하는 경우도 있습니다(예를 들어 메시지를 관찰하고 다른 시스템에 보내야 하는 경우, 응답을 받아 기록하고 피드백을 제공해야 하는 경우).
이런 모든 컴포넌트들은 각각의 관계 사이에 필요한 번역만 수행할 것으로 예상됩니다.
Feeders
피더
Feeders are components which convert input into relational assignments — i.e. cause changes to the essential state. In order to be able to cause these state changes, feeders will need to specify them in some form of state manipulation language provided by the infrastructure. At a minimum, this language can consist of just a relational assignment command which assigns to a relvar a whole new relation value in its entirety:
피더는 입력을 관계형 할당으로 변환하는, 즉 본질적 상태를 변경하는 컴포넌트입니다. 이러한 상태 변경을 일으키려면 인프라에서 제공하는 상태 조작 언어의 형태로 피더를 지정해야 합니다. 최소한 이 언어는 relvar에 전체적으로 새로운 관계 값을 할당하는 관계형 할당 명령어로 구성될 수 있습니다.
relvar := newRelationValue
The infrastructure which eventually runs the FRP system will ensure that the command respects the integrity constraints26 — either by rejecting non-conformant commands, or possibly in some cases by modifying them to ensure conformance.
결국 FRP 시스템을 실행하는 인프라는 비준수 명령을 거부하거나, 일치하도록 수정함으로써 명령이 무결성 제약 조건을26 준수하도록 보장합니다.
Observers
옵저버
Observers are components which generate output in response to changes which they observe in the values of the (derived) relvars. At a minimum, observers will only need to specify the name of the relvar which they wish to observe. The infrastructure which runs the system will ensure that the observer is invoked (with the new relation value) whenever it changes. In this way observers act both as what are sometimes called live-queries and also as triggers.
옵저버는 (파생된) relvar 값의 변화를 관찰하고 이에 반응해 출력을 생성하는 컴포넌트입니다. 옵저버는 관찰하고자 하는 relvar의 이름만 지정하면 충분합니다 시스템을 운영하는 인프라는 relvar 값이 변경될 때마다 옵저버가 (새로운 관계 값과 함께) 호출되도록 보장할 것입니다. 이런 방식으로 옵저버는 라이브 쿼리라고 불리는 역할과 트리거 역할을 동시에 수행합니다.
Despite this the intention is not for observers to be used as a substitute for true integrity constraints. Specifically, hybrid feeders / observers should not act as triggers which directly update the essential state (this would by definition be creating derived and hence accidental state). The only (occasional) exceptions to this should be of the ease of expression kind discussed in sections 7.2.2 and 7.3.1.
그럼에도 불구하고, 옵저버를 진정한 무결성 제약 조건의 대체 수단으로 사용하려는 의도는 아닙니다. 특히, 하이브리드 피더/옵저버는 본질적 상태를 직접 업데이트하는 트리거 역할을 수행해서는 안 됩니다(정의상 파생 상태를 생성하므로 우발적 상태를 만들게 됩니다). 이에 대한 유일한 예외는 드물게 발생하며, 7.2.2절과 7.3.1절에서 논의된 바와 같이 표현의 용이성에 관련된 경우들이 그러합니다.
Summary
요약
The most complicated scenario when interfacing the core relational system with the outside world is likely to come when the interfacing requires highly structured input or output (this is most likely to occur when interfacing with other systems rather than with people).
In this situation, the feeders or observers are forced to convert between structured data and flat relations.27
핵심 관계형 시스템과 외부 세계를 연결할 때의 가장 복잡한 시나리오는, 고도로 구조화된 입력 또는 출력이 필요할 때 발생할 가능성이 높습니다(이는 사람이 아닌 다른 시스템과 인터페이싱할 때 가장 자주 발생할 것입니다).
이런 상황에서는 피더 또는 옵저버가 구조화된 데이터와 플랫 관계(flat relations) 사이를 변환해야 합니다.27
9.1.5 Infrastructure
인프라
In several places above we have referred to the “infrastructure which runs the FRP system”. The FRP system is the specification — comprising of the four components above, the infrastructure is what is needed to execute this specification (by interpretation, compilation or some mixture).
앞에서 여러 차례 "FRP 시스템을 실행하는 인프라"를 언급했습니다. FRP 시스템은 앞에서 이야기한 네 가지 컴포넌트로 이루어진 명세입니다. 인프라는 이 명세를 실행하기 위해 필요한 것입니다(인터프리터, 컴파일 또는 이 둘의 혼합).
The different components of an FRP system lead to different requirements on the infrastructure which is going to support them.
FRP 시스템의 다양한 컴포넌트들은 인프라에 대한 다양한 요구 사항을 제시합니다.
Infrastructure for Essential State
본질적 상태를 위한 인프라
- some means of storing and retrieving data in the form of relations assigned to named relvars
- a state manipulation language which allows the stored relvars to be updated (within the bounds of the integrity constraints)
- optionally (depending on the exact range of FRP systems which the infrastructure is intended to support) secondary (e.g. disk-based) storage in addition to the primary (in memory) storage
- a base set of generally useful types (typically integer, boolean, string, date etc)
- 이름이 붙은 relvar에 할당된 관계 형태의 데이터를 저장하고 검색하는 수단.
- 저장된 relvar를 업데이트할 수 있는 상태 조작 언어(무결성 제약 조건의 범위 내에서).
- 선택적으로(인프라가 지원하는 FRP 시스템의 정확한 범위에 따라) 주 저장소(인메모리) 외에 보조 저장소(예: 디스크 기반).
- 일반적으로 유용한 타입의 기본 세트(보통 정수, 불리언, 문자열, 날짜 등)
Infrastructure for Essential Logic
본질적 논리를 위한 인프라
- a means to evaluate relational expressions
- a base set of generally useful functions (for things such as basic arithmetic etc)
- a language to allow specification (and evaluation) of the user-defined functions in the FRP system. (It does not have to be a functional language, but the infrastructure must only allow it to be used in a functional way)
- optionally a means of type inference (this will also require a mechanism for declaring the types of the user-defined functions in the FRP system)
- a means to express and enforce integrity constraints
- 관계형 표현식을 평가하는 수단.
- 일반적으로 유용한 함수의 기본 세트(기본 산술 등과 같은 기능을 위한).
- FRP 시스템에서 사용자 정의 함수를 지정(및 평가)할 수 있는 언어(함수형 언어가 아니어도 되지만, 인프라는 함수형 방식으로만 사용할 수 있도록 해야 함).
- 선택적으로 타입 추론 수단(이는 FRP 시스템에서 사용자 정의 함수의 타입을 선언하는 메커니즘도 필요로 함).
- 무결성 제약 조건을 표현하고 강제하는 수단.
Infrastructure for Accidental State and Control
우발적 상태와 제어를 위한 인프라
- a means to specify which derived relvars should actually be stored, along with the ability to store such relvars and ensure that the stored values are accurately up-to-date at all times
- a flexible means to specify physical storage mechanisms to be used by a relvar. This is a vital part of the infrastructure — without it the infrastructure must store relvars in a way which closely mirrors their logical (essential) definitions, and that inevitably leads to accidental (performance) concerns corrupting the essential parts of the system. Specifically, procedures such as normalization or “de-normalization” at the logical (essential) level should have no intrinsic performance implications because of the presence of this mechanism.
- 실제로 저장해야 하는 파생 relvar를 지정하는 수단, 그리고 이런 relvar를 저장하고 저장된 값이 항상 정확하게 최신 상태인지 보장하는 수단.
- relvar에서 사용할 물리적 저장 메커니즘을 유연하게 지정하는 수단. 이것은 인프라의 중요한 부분입니다. 이 기능이 없으면 인프라는 논리적(본질적) 정의와 밀접하게 유사한 방식으로 relvar를 저장해야 합니다. 이는 결국 시스템의 본질적인 부분을 손상시키게 되는 우발적(성능) 문제로 이어질 수 있습니다. 구체적으로는, 이 메커니즘의 존재로 인해 논리적(본질적) 수준에서의 정규화 또는 "비정규화"와 같은 절차가 내재적인 성능에 영향을 미치지 않아야 합니다.
Infrastructure for Feeders and Observers
피더와 옵저버를 위한 인프라
The minimum requirement on the infrastructure (specifically on the state manipulation language) from feeders is for it to be able to process relational assignment commands (containing complete new relation values) and reject them if necessary. Practical extensions that could be useful include the ability to accept commands which specify new relvar values in terms of their previous values — typically in the form of INSERT / UPDATE / DELETE commands.
피더의 인프라(특히 상태 조작 언어)에 대한 최소 요구 사항은 (완전히 새로운 관계 값을 포함하는) '관계 할당 명령을 처리'하고 '필요한 경우에는 거부할 수 있어야 한다'는 것입니다. 유용한 실용적인 확장 기능으로는 이전 값에 따라 새로운 relvar 값을 지정하는 명령을 수용할 수 있는 기능이 있습니다(일반적으로 INSERT /UPDATE / DELETE 명령 형태).
The minimum requirement on the infrastructure from observers is for it to be able to supply the new value of a relvar whenever it changes. Practical extensions that could be useful are the ability to provide deltas, throttling and coalescing capabilities (if the observers are viewed as live query-handlers, then these extensions represent potential query meta-data).
옵저버가 인프라에 요구하는 최소한의 요구사항은 relvar의 새로운 값이 변경될 때마다 해당 값을 제공할 수 있어야 한다는 것입니다. 유용한 실용적 확장 기능으로는 델타, 쓰로틀링 및 통합 기능이 있습니다(옵저버를 라이브 쿼리 핸들러로 간주하는 경우, 이러한 확장 기능은 잠재적인 쿼리 메타 데이터를 나타냅니다).
Another possible extension is the ability to observe general relational expressions rather than just relvars from the essential logic (this is not a significant extension as it is basically equivalent to a short-term addition to the essential logic’s set of derived relvars — the only difference being that the expression in question would be anonymous).
Finally, the ability to access arbitrary historical relvar values would obviously be a useful extension in some scenarios.
또 다른 가능한 확장은 본질적 논리에서 나온 relvar가 아닌 일반적인 관계 표현식을 관찰하는 기능입니다(이는 기본적으로는 본질적 논리의 파생 relvar 집합에 잠시 추가하는 것과 똑같기 때문에 대단한 확장은 아닙니다. 해당 표현식이 익명이라는 점만 다릅니다).
마지막으로, 임의의 과거 relvar 값에 엑세스할 수 있는 기능은 몇 가지 시나리오에서 분명히 유용한 확장 기능이 될 것입니다.
Summary
요약
If a system is to be based upon the FRP architecture it will be necessary either to obtain an FRP infrastructure from a third party, or to develop one with existing tools and techniques.
만약 FRP 아키텍처를 기반으로 한 시스템을 구축하려면, FRP 인프라를 서드 파티로부터 얻거나 기존의 도구와 기술을 사용하여 개발해야 합니다.
Currently of course no real FRP infrastructures exist and so at present the choice is clear. However, even in the presence of third party infrastructures there may in fact be compelling reasons for large systems to adopt the custom route. Firstly, the effort involved in doing so need not be huge28, and secondly the custom approach leads to the ability to tailor the hints available (for use in the accidental state and control component) to the exact requirements of the application domain.
Finally, it is of course perfectly possible to develop an FRP infrastructure in any general purpose language — be it object-oriented, functional or logic.
물론 현재 실존하는 FRP 인프라는 존재하지 않으므로 선택은 명확합니다. 그러나 서드 파티 인프라가 존재하는 경우에도 대규모 시스템이 커스텁 경로를 채택해야 하는 강력한 이유가 실제로 있을 수 있습니다.
첫째, 커스텀 접근 방식을 사용하면 많은 노력이 필요하지 않습니다.28 둘째, 커스텀 접근 방식은 애플리케이션 도메인의 정확한 요구 사항에 따라 (우발적인 상태와 제어 컴포넌트에 사용될 수 있는) 힌트를 맞춤 설정하는 능력을 제공합니다.
마지막으로, 객체지향, 함수형, 논리 등 모든 범용 프로그래밍 언어로 FRP 인프라를 개발하는 것도 완벽하게 가능합니다.
9.2 Benefits of this approach
이러한 접근 방식의 장점
FRP follows the guidelines of avoid and separate as recommended in section 7 and hence gains all the benefits which derive from that. We now examine how FRP helps to avoid complexity from the common causes.
FRP는 7장에서 권장하는 회피와 분리 지침을 따르므로, 이로부터 유도되는 모든 이점을 얻을 수 있습니다. 이제 FRP가 어떻게 공통 원인으로부터 발생하는 복잡성을 회피하는 데 도움이 되는지 살펴보겠습니다.
9.2.1 Benefits for State
상태 측면의 이점
The architecture is explicitly designed to avoid useless accidental state, and to avoid even the possibility of an FRP system ever getting into a “bad state”.
이 아키텍처는 불필요한 우발적 상태를 회피하고, FRP 시스템이 "나쁜 상태"에 빠지는 가능성까지도 방지하도록 명시적으로 설계되었습니다.
Specifically derived state is not normally stored (is not treated as essential state). In normal circumstances29 hybrid feeders/observers never feed back in the exact same data which they observed — they only ever feed in some externally generated input or response. So long as this principle is observed errors in the logic of the system can never cause it to get into a “bad state” — the only thing required to fix such errors30 is to correct the logic, there is no need to perform an exhaustive search through and correction of the essential state. This also means that (aside from errors in the infrastructure) the system can never require “restarting” / “rebooting” etc.
특별히 파생된 상태는 일반적으로 저장되지 않습니다(본질적 상태로 취급되지 않습니다). 정상적인 상황에서29 하이브리드 피더/옵저버는 관찰한 데이터와 정확히 같은 데이터를 다시 피드백하지 않으며, 오직 외부에서 생성된 입력 또는 응답을 피드백합니다.
이러한 원칙이 지켜지는 한, 시스템 논리의 에러로 인해 시스템이 "나쁜 상태"에 빠지는 일은 결코 발생하지 않습니다. 이러한 에러를30 해결하는 데 필요한 것은 논리를 수정하는 것뿐이므로, 에러를 고치기 위해 본질적 상태를 꼼꼼히 검색하고 수정할 필요가 없습니다.
이는 또한 (인프라에서의 에러를 제외하고) 시스템이 "재시작" / "재부팅" 등을 필요로 하지 않는다는 것을 의미합니다.
When it comes to separation, the architecture clearly exhibits both the logic / state split and the accidental / essential split recommended in section 7. An example of what this means is that you do not have to think about any accidental state when concentrating on the logic of your system. In fact, you do not really have to think about the essential state as being state either — from the point of view of the logic, the essential state is seen as constant.
분리와 관련해서는, 이 아키텍처는 7장에서 권장하는 논리/상태 분리와 우발적/본질적 분리를 명확하게 보여줍니다. 이것이 무슨 의미인지 예를 들어 설명하면, 시스템의 논리에 집중할 때는 어떤 우발적 상태에 대해서도 생각할 필요가 없다는 것입니다. 사실, '본질적 상태'를 상태로 생각할 필요도 없습니다. 논리적인 관점에서 본질적 상태는 상수로 간주됩니다.
Furthermore, the functional component (of the logic) has no access to any state at all (even the essential state) — it is totally referentially transparent, can only access what is supplied in the function arguments, and hence offers hugely better prospects for testing (as mentioned earlier in section 4.1.1).
또한 함수 컴포넌트(로직의 일부)는 어떤 상태에도 접근할 수 없습니다(본질적 상태도 포함). 이는 완전한 참조 투명성을 보장하며, 함수의 인수로 제공된 것만 접근할 수 있으므로 테스트에 대해서도 더 나은 가능성을 제공합니다(4.1.1절에서 언급한 바와 같음).
Additionally, there are major advantages gained from adopting a relational representation of data — specifically, there is no introduction of subjective bias into the data, no concern with data access paths. This is in contrast with approaches such as OOP or XML (as we saw in section 8.1.2).
그리고, 데이터의 관계형 표현을 채택함으로써 큰 장점들을 얻을 수 있습니다. 특히 데이터에 주관적인 편견이 개입되지 않고 데이터 접근 경로에 대한 고려가 필요하지 않게 됩니다. 이는 8.1.2절에서 살펴본 바와 같이, OOP나 XML 같은 접근 방식과는 대조적입니다.
Finally, integrity constraints provide big benefits for maintaining consistency of state in a declarative manner:
The fact that we can impose the integrity constraints of our system in a purely declarative manner (without requiring triggers or worse, methods / procedures) is one of the key benefits of the FRP approach. It means that the addition of new constraints increases the complexity of the system only linearly because the constraints do not — indeed cannot — interact in any way at all. (Constraints can make use of user-defined functions — but they have no way of referring to other constraints). This is in stark contrast with more imperative approaches such as object oriented programming where interaction between methods causes the complexity to grow at a far greater rate.
마지막으로, 무결성 제약 조건은 상태의 일관성을 선언적인 방식으로 유지하는 데 큰 장점을 제공합니다.
시스템의 무결성 제약을 트리거나 메소드/절차 없이 '순전히 선언적인 방법으로' 부여할 수 있다는 사실은 FRP 접근 방법의 핵심 장점 중 하나입니다. 즉, 새로운 제약 조건을 추가해도 제약 조건들이 전혀 상호작용하지 않기 때문에 시스템의 복잡성이 선형적으로만 증가한다는 것을 의미합니다(제약 조건은 사용자 정의 함수를 사용할 수 있지만, 다른 제약 조건을 참조할 수 있는 방법은 없습니다).
이는 메소드 간의 상호 작용으로 인해 복잡성이 훨씬 더 빠른 속도로 증가하는 객체지향 프로그래밍과 같은 명령형 접근 방식과는 완전히 대조된다고 할 수 있습니다.
Furthermore, the declarative nature of the integrity constraints opens the door to the possibility of a suitably sophisticated infrastructure making use of them for performance reasons (to give a trivial example, there is no need to compute the relational intersection of two relvars at all if it can be established that their integrity constraints are mutually exclusive — because then the result is guaranteed to be empty). This type of optimisation is just not possible if the integrity is maintained in an imperative way.
또한, 무결성 제약 조건의 선언적 특성은 적절히 복잡한 인프라가 성능을 달성하기 위해 활용할 가능성을 열어줍니다(간단한 예를 들어보자면, 두 relvar의 무결성 제약 조건이 서로 배타적임을 알고 있다면 두 relvar의 관계적 교집합을 계산할 필요가 없습니다. 결과가 항상 공집합일 것이기 때문입니다).
이런 종류의 최적화는 무결성이 명령형 방식으로 유지하는 경우에는 불가능합니다.
9.2.2 Benefits for Control
제어 측면의 이점
Control is avoided completely in the relational component which constitutes the top level of the essential logic. In FRP this logic consists simply of a set of equations (equating derived relvars with the relations calculated by their expressions) which have no intrinsic ordering or control flow at all.
본질적 논리의 최상위 레벨을 구성하는 관계형 컴포넌트에서는 제어가 완전히 제거됩니다. FRP에서 이 논리는 단순히 일련의 (파생된 relvar들이 표현식에 의해 계산된 관계와 동일함을 나타내는) 방정식들로만 구성되며, 이 방정식들은 내재된 순서나 제어 흐름이 전혀 없습니다.
FRP also avoids any explicit parallelism in the essential components but provides for the possibility of separated accidental control should that be required.
FRP는 또한 본질적인 컴포넌트에서 병렬 처리를 명시적으로 하지 않지만, 필요한 경우에는 별도의 우발적 제어 가능성을 제공합니다.
An infrastructure which supports FRP may well make use of implicit parallelism to improve its performance — but this shouldn’t be the concern of anyone other than the implementor of the infrastructure — certainly it is not the concern of someone developing an FRP system.
FRP를 지원하는 인프라는 성능을 개선하기 위해 암묵적으로 병렬 처리를 사용할 수 있습니다. 하지만 이는 인프라 구현자 이외의 사람들, 특히 FRP 시스템을 개발하는 사람이 고려해야 할 문제가 아닙니다.
A final advantage (which isn’t particularly related to control) is that the uniform nature of the representation of data as relations makes it much easier to create distributed implementations of an FRP infrastructure should that be required (e.g. there are no pointers or other access paths to maintain).
(제어와는 특히 관련이 없는) 마지막 장점은 데이터를 관계로 표현하는 일관된 특성으로 인해 필요한 경우 FRP 인프라의 분산 구현을 훨씬 쉽게 만들 수 있다는 것입니다(예를 들자면, 포인터나 다른 접근 경로를 유지하고 관리할 필요가 없습니다).
9.2.3 Benefits for Code Volume
코드의 양 측면의 이점
FRP addresses this in two ways. The first is that a sharp focus on true essentials and avoiding useless accidental complexity inevitably leads to less code.
The second way is that the FRP approach reduces the harm that large volumes of code cause through its use of separation (see section 4.3).
FRP는 두 가지 방식으로 이 문제를 해결합니다. 첫 번째는 정말로 본질적인 것에만 집중하고 쓸모없는 우발적 복잡성을 피하는 것을 통해, 필연적으로 코드의 양이 줄어들게 됩니다.
두 번째는 FRP 접근 방식이 분리를 사용함으로써 코드의 양이 많을 때 발생하는 피해를 줄인다는 것입니다(4.3절 참조).
9.2.4 Benefits for Data Abstraction
데이터 추상화 측면의 이점
Data Abstraction is something which we have only mentioned in passing (in section 4.4) so far. By data abstraction we basically mean the creation of compound data types and the use of the corresponding compound values (whose internal contents are hidden).
데이터 추상화는 지금까지는 간단히 언급만 했습니다(4.4절 참조). 데이터 추상화란 기본적으로 복합 데이터 타입을 생성하고, (내부 내용이 숨겨진) 해당 복합 값을 사용하는 것을 의미합니다.
We believe that in many cases, un-needed data abstraction actually represents another common (and serious) cause of complexity. This is for two reasons:
많은 경우, 불필요한 데이터 추상화가 실제로는 복잡성의 또 다른 일반적(그리고 심각한) 원인이라고 믿습니다.
그 이유는 두 가지입니다.
Subjectivity Firstly the grouping of data items together into larger compound data abstractions is an inherently subjective business (Ungar and Smith discuss this problem in the context of Self in [SU96]). Groupings which make sense for one purpose will inevitably differ from those most natural for other uses, yet the presence of pre-existing data abstractions all too easily leads to inappropriate reuse.
주관성
첫째, 데이터 항목을 더 큰 복합 데이터 추상화로 묶는 것은 본질적으로 '주관적인' 작업입니다(Ungar와 Smith는 Self의 문맥에서 이 문제에 대해 논의합니다). 한 가지 용도에 적합한 그룹화는 다른 용도에 가장 자연스러운 그룹화와 필연적으로 다를 수 밖에 없습니다. 그러나 기존의 추상화된 데이터는 너무 쉽게 부적절한 재사용으로 이어지게 됩니다.
Data Hiding Secondly, large and heavily structured data abstractions can seriously erode the benefits of referential transparency (section 5.2.1) in exactly the manner of the extreme example discussed in section 5.2.3. This problem occurs both because data abstractions will often cause un-needed, irrelevant data to be supplied to a function, and because the data which does get used (and hence influences the result of a function) is hidden at the function call site. This hidden and excessive data leads to problems for testing as well as informal reasoning in ways very similar to state (see section 4.1).
데이터 숨기기
둘째, 크기가 크고 고도로 구조화된 데이터 추상화는 5.2.3절에서 논의한 극단적인 예와 정확히 같은 방식으로 참조 투명성의 이점을 심각하게 훼손할 수 있습니다(5.2.1절 참조). 이 문제는 데이터 추상화로 인해 '함수에 불필요하고 관련 없는 데이터가 제공되는 경우'와, 실제로 '사용된 데이터(따라서 함수의 결과에 영향을 미치는)가 함수 호출 사이트에서 숨겨지는 경우'에 모두 발생합니다.
이렇게 숨겨지고 과도한 데이터는 상태(4.1절 참조)와 매우 유사한 방식으로 테스팅과 비형식적 추론에 문제를 일으킵니다.
One of the primary strengths of the relational model (inherited by FRP) is that it involves only minimal commitment to any subjective groupings (basically just the structure chosen for the base relations), and this commitment has only minimal impact on the rest of the system. Derived relvars offer a straightforward way for different (application-specific) groupings to be used alongside the base groupings. The benefits in terms of subjectivity are closely related to the benefits of access path independence (section 8.1.2).
관계형 모델의 주요한 강점 중 하나는 (FRP가 계승한) 주관적 그룹화 (기본 관계에 대해 선택한 구조)에 대한 최소한의 헌신적인 작업만 필요하며, 이러한 작업은 시스템의 나머지 부분에 최소한의 영향만 미친다는 점입니다.
파생된 relvars는 기본 그룹화와 함께 다른 (애플리케이션별) 그룹화를 사용하는 간단한 방법을 제공합니다.
주관성 측면의 이점은 접근 경로 독립성(8.1.2절 참조)의 이점과 밀접한 관련이 있습니다.
FRP also offers benefits in the area of data hiding, simply by discouraging it. Specifically, FRP offers no support for nested relations or for creating product types (as we shall see in section 9.3).
FRP는 데이터를 숨기는 영역에서도 이점을 제공합니다. 특히 FRP는 중첩 관계나 제품 유형을 생성하는 데 대한 지원을 제공하지 않습니다(9.3절에서 살펴볼 것입니다).
9.2.5 Other Benefits
그 외의 장점들
The previous sections considered the benefits offered by FRP for minimizing complexity.
이전 절에서는 FRP가 복잡성을 최소화하는 데 제공하는 이점을 고려했습니다.
Other potential benefits include performance (as mentioned briefly under section 9.2.1) and the possibility that development teams themselves could be organised around the different components — for example one team could focus on the accidental aspects of the system, one on the essential aspects, one on the interfacing, and another on providing the infrastructure.
다른 종류의 잠재적인 장점들로는 성능(9.2.1절에서 간단히 언급했음)과, 개발팀을 여러 컴포넌트 중심으로 구성할 수 있는 가능성을 들 수 있습니다(예: 각 팀이 각각 시스템의 우발적 측면, 본질적인 측면, 인터페이스, 인프라 제공에 집중할 수 있음).
9.3 Types
타입
A final comment is that — in addition to a fairly typical set of standard types — FRP provides a limited ability to define new user types for use in the essential state and essential logic components.
마지막으로 한 마디 더 하자면, FRP는 상당히 일반적인 표준 타입 집합 외에도, 본질적 상태와 본질적 논리 컴포넌트에서 사용할 수 있는 새로운 사용자 타입을 정의할 수 있는 기능이 제한되어 있습니다.
Specifically it permits the creation of disjoint union types (sometimes known as “enumeration” types) but does not permit the creation of new product types (types with multiple subsidiary components). This is because (as mentioned above) we have a strong desire to avoid any unnecessary data abstraction.
구체적으로는 분리된 합집합 타입(때로는 "열거" 타입이라고도 함)을 생성할 수 있지만, 새로운 제품 타입(여러 하위 구성 요소를 가진 유형)을 생성할 수는 없습니다.
Finally, it probably makes sense for infrastructures to provide type inference for the essential logic. Interesting work in this area has been carried out in the Machiavelli system [OB88].
마지막으로, 인프라가 필수 논리에 대한 타입 추론을 제공하는 것이 합리적일 것입니다. 이 분야에서 흥미로운 작업이 Machiavelli 시스템에서 수행된 바 있습니다.
10 Example of an FRP system
FRP 시스템의 예
We now examine a simple example FRP system. The system is designed to support an estate agency (real estate) business. It will keep track of properties which are being sold, offers which are made on the properties, decisions made on the offers by the owners, and commission fees earnt by the individual agency employees from their successful sales. The example should serve to highlight the declarative nature of the components of an FRP system.
이제 간단한 FRP 시스템의 예를 살펴보겠습니다. 이 시스템은 부동산 중개 사업을 지원하기 위해 설계되었습니다. 이 시스템은 판매중인 부동산, 해당 부동산에 대한 거래 제안, 부동산 소유자가 내린 제안에 대한 결정, 거래 성사를 통해 중개사 직원이 받은 거래 수수료를 추적 관리합니다.
이 예는 FRP 시스템 컴포넌트의 선언적 성격을 강조하는 데 도움이 될 것입니다.
To keep things simple, this system operates under some restrictions:
- Sales only — no rentals / lettings
- People only have one home, and the owners reside at the property they are selling
- Rooms are perfectly rectangular
- Offer acceptance is binding (ie an accepted offer constitutes a sale)
The example will use syntax from a hypothetical FRP infrastructure (which supports not only the relational algebra but also some of the common extensions from section 8.5) — typewriter font is used for this.
이 시스템은 다음과 같은 제한 사항 하에서 동작합니다.
- 판매 전용 - 대여/임대 금지
- 사람들은 집 한 채만 가지고 있으며, 집주인은 판매하는 부동산에 거주합니다.
- 방은 완벽한 직사각형입니다.
- 거래 제안 수락은 구속력이 있습니다(즉, 수락된 거래 제안은 판매로 간주합니다).
이 예제는 가상의 FRP 인프라(관계 대수뿐만 아니라 8.5절의 일부 공통 확장 기능도 지원하는)의 문법을 사용합니다. 이 문법을 표시하기 위해 타자기 폰트를 사용합니다.
10.1 User-defined Types
사용자 정의 타입
The example system makes use of a small number of custom types (see section 9.3), some of which are just aliases for types provided by the infrastructure:
예제 시스템에서는 몇 가지 커스텀 타입(9.3절 참고)을 사용합니다. 이 중 일부는 인프라에서 제공하는 타입의 별칭일 뿐입니다.
def alias address : string def alias agent : string def alias name : string def alias price : double def enum roomType : KITCHEN | BATHROOM | LIVING_ROOM def enum priceBand : LOW | MED | HIGH | PREMIUM def enum areaCode : CITY | SUBURBAN | RURAL def enum speedBand : VERY_FAST | FAST | MEDIUM | SLOW | VERY_SLOW
10.2 Essential State
본질적 상태
The essential state (see section 9.1.1) consists of the definitions of the types of the base relvars (the types of the attributes are shown in italics).
본질적 상태(9.1.1절 참고)는 기본 relvar의 타입 정의로 구성됩니다(속성의 타입은 이탤릭체로 표시됩니다).
def relvar Property :: {address:address price:price photo:filename agent:agent dateRegistered:date}
def relvar Offer :: {address:address offerPrice:price offerDate:date bidderName:name bidderAddress:address}
def relvar Decision :: {address:address offerDate:date bidderName:name bidderAddress:address decisionDate:date accepted:bool }
def relvar Room :: {address:address roomName:string width:double breadth:double type:roomType}
def relvar Floor :: {address:address roomName:string floor:int }
def relvar Commission :: {priceBand:priceBand areaCode:areaCode saleSpeed:speedBand commission:double}
The example makes use of six base relations, most of which are self explanatory.
이 예제에서는 6개의 기본 관계를 사용합니다. 이 중 대부분은 자기설명적이어서 설명이 필요 없습니다.
The Property relation stores all properties sold or for-sale. As will be seen in section 10.3.3, properties are uniquely identified by their address. The price is the desired sale price, the agent is the agency employee responsible for selling the Property, and the dateRegistered is the date that the Property was registred for sale with the agency.
Property 관계는 판매되었거나 판매중인 모든 부동산이 저장됩니다.
10.3.3절에서 설명했던 것처럼, 부동산은 주소를 통해 고유하게 식별됩니다.
price는 판매 희망 가격이고, agent는 부동산을 판매하는 데 책임이 있는 직원 중개인이며, dateRegistered는 부동산이 판매 등록된 날짜입니다.
The Offer relation records the history of all offers ever made. The address represents the Property on which the Offer is being made (by the bidderName who lives at bidderAddress). The offerDate attribute records the date when the offer was made, and the offerPrice records the price offered. Offers are uniquely identified by an (address, offerDate, bidderName, bidderAddress) combination.
Offer 관계는 지금까지 이루어진 모든 거래의 이력을 기록합니다.
address는 주로 거래가 이루어진 부동산을 나타냅니다(거래 제안자는 bidderName이고, bidderAddress에 거주합니다).
offerDate 속성은 거래 제안이 이루어진 날짜를 기록하고, offerPrice는 제안된 가격을 기록합니다.
Offer는 (address, offerDate, bidderName, bidderAddress) 조합으로 고유하게 식별됩니다.
The Decision relation records the decisions made by the owner on the Offers that have been made. The Offer in question is identified by the (address, offerDate, bidderName, bidderAddress) attributes, and the date and outcome of the decision are recorded by (decisionDate and accepted).
Decision 관계는 완료된 Offer에 대한 집주인의 결정을 기록합니다.
해당 Offer는 (address, offerDate, bidderName, bidderAddress) 속성으로 식별되며, 결정의 날짜와 결과는 (decisionDate, accepted)로 기록됩니다.
The Room relation records information (width, breadth, type) about the rooms that exist at each Property. The Property is of course represented by the address. One point worthy of note (because it’s slightly artificial) is that an assumption is made that every Room in each Property has a unique (within the scope of that Property) roomName. This is necessary because many properties may have more than one room of a given type (and size).
Room 관계는 각 부동산에 존재하는 방에 대한 정보(width, breadth, type)를 기록합니다.
Property(부동산)는 address로 표현됩니다.
한 가지 주목할 점은 (좀 인위적이기 때문) 각 Property의 모든 Room에는 고유한 roomName이 있다는 가정을 한다는 것입니다.
이는 많은 부동산이 특정 타입(그리고 사이즈)의 방이 하나 이상 있을 수 있기 때문에 필요합니다.
The Floor relation records which floor each Room (roomName, address) is on.
Floor 관계는 각 Room (roomName, address)이 어느 층에 있는지를 기록합니다.
Finally, the Commission relation stores commission fees that can be earned by the agency employees. The commission fees are assigned on the basis of sale prices divided into different priceBands, Property addresses categorized into areaCodes and ratings of the saleSpeed. (The decision has been made to represent commission rates as a base relation — rather than as a function — so that the commission fees can be queried and easily adjusted).
마지막으로, Commission 관계에는 중개 직원이 받을 수 있는 수수료가 저장됩니다.
commission은 여러 가격대로 나누어진 판매 가격, areaCode로 분류된 Property 주소, 판매 속도에 따른 saleSpeed의 등급에 따라 할당됩니다.
(수수료율을 함수가 아닌 기본 관계로 표현하고, 쿼리하고 쉽게 조정할 수 있도록 하기 위해 이런 결정을 내렸습니다).
10.3 Essential Logic
본질적 논리
This is the heart of the system (see section 9.1.2) and corresponds to the “business logic”.
이것은 시스템의 핵심이며(9.1.2절 참조), "비즈니스 로직"에 해당합니다.
10.3.1 Functions
함수
We do not give the actual function definitions here, we just describe their operation informally. In reality we would supply the function definitions in terms of some language provided by the infrastructure.
priceBandForPriceConverts a price into apriceBand(which will be used in the commission calculations)
areaCodeForAddressConverts an address into anareaCode
datesToSpeedBandConverts a pair of dates into aspeedBand(reflecting the speed of sale after taking into account the time of year)
여기에서는 실제 함수 정의를 제공하지 않고, 비형식적으로 작동 방식을 설명하도록 하겠습니다. 실제로는 인프라에서 제공하는 언어로 함수 정의를 제공할 것입니다.
priceBandForPrice가격을priceBand로 변환합니다(수수료 계산에 사용됩니다).areaCodeForAddress주소를areaCode로 변환합니다.datesToSpeedBand두 날짜를speedBand로 변환합니다(연도의 시간을 고려한 판매 속도를 반영합니다).
10.3.2 Derived Relations
파생 관계
There are thirteen derived relations in the system. These can be very loosely classified as internal or external according to whether their main purpose is simply to facilitate the definition of other derived relations (and constraints) or to provide information to the users. We consider the definition and purpose of each in turn.
As an aid to understanding, the types of the derived relations are shown in comments (delimited by
/*and*/). In reality these types would be derived (or checked) by an infrastructure-provided type inference mechanism.
이 시스템에는 13개의 파생 관계가 있습니다. 이들은 주로 다른 파생 관계(및 제약 조건)의 정의를 용이하게 하기 위한 것인지, 사용자에게 정보를 제공하기 위한 것인지에 따라 내부 또는 외부로 매우 느슨하게 분류될 수 있습니다.
각각의 정의와 목적을 살펴보겠습니다.
이해를 돕기 위해 파생 관계의 타입은 주석으로 표시됩니다(/*와 */로 구분됨).
실제로 이러한 타입은 인프라에서 제공하는 타입 추론 메커니즘에 의해 파생(또는 확인)됩니다.
Internal
내부
The ten internal derived relations exist mainly to help with the later definition of the three external ones.
10개의 내부 파생 관계는 주로 나중에 정의할 3개의 외부 파생 관계를 정의할 때 도움을 주기 위해 존재합니다.
/* RoomInfo :: {address:address roomName:string width:double breadth:double type:roomType roomSize:double} */ RoomInfo = extend(Room, (roomSize = width*breadth))
The
RoomInfoderived relation simply extends theRoombase relation with an extra attributeroomSizewhich gives the area of each room.
RoomInfo 파생 관계는 각 방의 면적을 나타내는 추가 속성 roomSize를 사용해서 Room 기본 관계를 확장합니다.
/* Acceptance :: {address:address offerDate:date bidderName:name bidderAddress:address decisionDate:date} */ Acceptance = project_away(restrict(Decision | accepted == true), accepted)
The
Acceptancederived relation simply selects the positive entries from theDecisionbase relation, and then strips away theacceptedattribute (theproject_awayoperation is the dual of theprojectoperation — it removes the listed attributes rather than keeping them).
Acceptance 파생 관계는 Decision 기본 관계에서 긍정적인(accepted == true) 결정을 선택한 다음 accepted 속성을 제거합니다(project_away 연산은 project 연산의 이중 연산입니다. 목록에 나열된 속성을 유지하는 대신 제거합니다).
/* Rejection :: {address:address offerDate:date bidderName:name bidderAddress:address decisionDate:date} */ Rejection = project_away(restrict(Decision | accepted == false), accepted)
The
Rejectionderived relation simply selects the negative decisions and removes theacceptedattribute.
Rejection 파생 관계는 부정적인(accepted == false) 결정을 선택하고 accepted 속성을 제거합니다.
/* PropertyInfo :: {address:address price:price photo:filename agent:agent dateRegistered:date priceBand:priceBand areaCode:areaCode numberOfRooms:int squareFeet:double} */ PropertyInfo = extend(Property, (priceBand = priceBandForPrice(price)), (areaCode = areaCodeForAddress(address)), (numberOfRooms = count(restrict(RoomInfo | address == address))), (squareFeet = sum(roomSize, restrict(RoomInfo | address == address))))
The
PropertyInfoderived relation extends thePropertybase relation with four new attributes. The first — calledpriceBand— indicates which of the estate agency’s price bands the property is in. The price band of the final sale price will affect the commission derived by the agent for selling the property. TheareaCodeattribute indicates the area code, which also affects the commission an agent may earn. ThenumberOfRoomsis calculated by counting the number of rooms (actually the number of entries in theRoomInfoderived relation at the corresponding address), and thesquareFeetis computed by summing up the relevantroomSizes.
PropertyInfo 파생 관계는 Property 기본 관계를 4개의 새로운 속성으로 확장합니다.
첫 번째인 priceBand는 부동산 회사의 가격대 중 어느 것에 속하는지를 나타냅니다.
최종 판매된 가격의 가격대는 부동산을 판매하는 대리인이 얻는 수수료에 영향을 미칩니다.
areaCode 속성은 중개인이 벌 수 있는 수수료에도 영향을 줄 수 있는 지역 코드를 나타냅니다.
numberOfRooms는 방의 수(실제로는 해당 주소의 RoomInfo 파생 관계의 항목 수)를 세어서 계산하고, squareFeet는 관련 roomSizes를 합산해서 계산합니다.
/* CurrentOffer :: {address:address offerPrice:price offerDate:date bidderName:name bidderAddress:address} */ CurrentOffer = summarize(Offer, project(Offer, address bidderName bidderAddress), quota(offerDate,1))
The purpose of the
CurrentOfferderived relation is to filter out old offers which have been superceded by newer ones (e.g. if the bidder has submitted a revised — higher or lower — offer, then we are no longer interested in older offers they may have made on the same property).
CurrentOffer 파생 관계의 목적은 새로운 것으로 대체된 오래된 제안을 필터링하는 것입니다(예를 들어 입찰자가 수정된(더 높거나 낮은) 제안을 제출했다면, 같은 부동산 매물에 대해 이전에 제출했던 제안에는 더 이상 관심이 없습니다).
The definition summarizes the
Offerbase relation, taking the most recent (ie the single greatestofferDate) offer made by each bidder on a property (ie per uniqueaddress,bidderName,bidderAddresscombination). Because bothbidderNameandbidderAddressare included, the system supports the (admittedly unusual) possibility of different people living in the same place (bidderAddress) submitting different offers on the same property (address).
이 정의는 부동산에 대한 각 입찰자의 가장 최근(즉, 가장 큰 offerDate) 제안을 가져옵니다(즉, 고유한 address, bidderName, bidderAddress 조합).
bidderName과 bidderAddress가 모두 포함되어 있기 때문에 시스템은 같은 주소(bidderAddress)에 사는 다른 사람들이 같은 부동산 주소(address)에 대해 다른 제안을 제출하는(드문 경우지만) 것을 지원합니다.
/* RawSales :: {address:address offerPrice:price decisionDate:date agent:agent dateRegistered:date} */ RawSales = project_away(join(Acceptance, join(CurrentOffer, project(Property, address agent dateRegistered))), offerDate bidderName bidderAddress)
For the purposes of this example, sales are seen as corresponding directly to accepted offers. As a result the definition of the
RawSalesrelation is in terms of theAcceptancerelation. These accepted offers are augmented (joined) with theCurrentOfferinformation (which includes the agreedofferPrice) and with information (agent,dateRegistered) from thePropertyrelation.
이 예제에서는 판매가 수락된 제안과 일대일 대응한다고 간주합니다.
따라서 RawSales 관계의 정의는 Acceptance 관계를 기반으로 합니다.
이 수락된 제안은 CurrentOffer 정보(합의된 offerPrice를 포함)와 Property 관계의 정보(agent, dateRegistered)와 결합됩니다.
/* SoldProperty :: {address:address} */ SoldProperty = project(RawSales, address)
The
SoldPropertyrelation simply contains theaddressof all Properties on which a sale has been agreed (ie the properties in theRawSalesrelation).
SoldProperty 관계는 판매가 합의된 모든 Property의 address(즉, RawSales 관계의 속성)를 단순히 포함합니다.
/* UnsoldProperty :: {address:address} */ UnsoldProperty = minus(project(Property, address), SoldProperty)
The
UnsoldPropertyis obviously just thePropertywhich is notSoldProperty(i.e. allPropertyaddresses minus theSoldPropertyaddresses).
UnsoldProperty는 분명히 SoldProperty가 아닌 Property입니다(즉, 모든 Property 주소에서 SoldProperty 주소를 제외한 것).
/* SalesInfo :: {address:address agent:agent areaCode:areaCode saleSpeed:speedBand priceBand:priceBand} */ SalesInfo = project(extend(RawSales, (areaCode = areaCodeForAddress(address)), (saleSpeed = datesToSpeedBand(dateRegistered, decisionDate)), (priceBand = priceBandForPrice(offerPrice))), address agent areaCode saleSpeed priceBand)
The
SalesInforelation is based on theRawSalesrelation, but extends it withareaCode,saleSpeedandpriceBandinformation by calling the three relevant functions.
SalesInfo 관계는 RawSales 관계를 기반으로 하지만, 세 가지 관련 함수를 호출하여 areaCode, saleSpeed 및 priceBand 정보를 추가합니다.
/* SalesCommissions :: {address:address agent:agent commission:double} */ SalesCommissions = project(join(SalesInfo, Commission), address agent commission)
The
SalesCommissionswhich are due to the agents are derived simply by joining together theSalesInfowith theCommissionbase relation. This gives the amount ofcommissiondue to eachagenton eachProperty(represented byaddress).
SalesCommissions는 SalesInfo와 Commission 기본 관계를 단순히 결합하여 agent에게 지급되는 수수료를 결정합니다.
이렇게 해서 각 Property(address로 표시)에 대해 각 agent에게 지급되는 commission 금액이 결정할 수 있게 됩니다.
External
외부
Having now defined all the internal derived relations, we are now in a position to define the external derived relations — these are the ones which will be of most direct interest to the users of the system.
모든 내부적인 파생 관계를 정의했으므로, 이제 시스템 사용자가 가장 직접적으로 관심을 가질 외부적인 파생 관계를 정의할 수 있게 됐습니다.
/* OpenOffers :: {address:address offerPrice:price offerDate:date bidderName:name bidderAddress:address} */ OpenOffers = join(CurrentOffer, minus(project_away(CurrentOffer, offerPrice), project_away(Decision, accepted decisionDate)))
The
OpenOffersrelation gives details of theCurrentOfferson which the owner has not yet made aDecision. This is calculated by joining theCurrentOfferinformation (which includesofferPrice) with thoseCurrentOffers(excluding the price information) that do not have correspondingDecisions.project_awayis used here because minus requires its arguments to be of the same type.
OpenOffers 관계는 소유자가 아직 Decision을 내리지 않은 CurrentOffers의 세부 정보를 제공합니다.
이는 CurrentOffer 정보(offerPrice를 포함)를 Decision이 없는 CurrentOffers(가격 정보를 제외)와 join하여 계산됩니다.
/* PropertyForWebSite :: {address:address price:price photo:filename numberOfRooms:int squareFeet:double} */ PropertyForWebSite = project( join(UnsoldProperty, PropertyInfo), address price photo numberOfRooms squareFeet )
The business wants to display the information from
PropertyInfoon their external website. However, they only want to show unsold property (this is achieved simply by ajoin), and they only want to show a subset of the attributes (this is achieved with aproject).
사업부서는 외부 웹사이트에서 PropertyInfo의 정보를 표시하길 원합니다.
그러나, 그들은 오직 판매되지 않은 Property만을 보여주길 원합니다(단순하게 join을 써서 할 수 있습니다), 그리고 그들은 속성의 하위 집합만을 보여주길 원합니다(project로 할 수 있습니다).
/* CommissionDue :: {agent:agent totalCommission:double} */ CommissionDue = project(summarize(SalesCommissions, project(SalesCommissions, agent), totalCommission = sum(commission)), agent totalCommission)
Finally, the total
commissiondue to eachagentis calculated by simply summing up thecommissionattribute of theSalesCommissionsrelation on a peragentbasis to give thetotalCommissionattribute.
마지막으로, 각 agent에게 지급되는 총 commission은 agent별로 SalesCommissions 관계의 commission 속성을 단순히 합산하여 totalCommission 속성을 얻는 것으로 계산됩니다.
10.3.3 Integrity
무결성
Integrity constraints are given in the form of relational algebra or relational calculus expressions. As already noted, our hypothetical FRP infrastructure provides common relational algebra extensions (see section 8.5). It also provides special syntax for candidate and foreign key constraints. (This syntax is effectively just a shorthand for the underlying algebra or calculus expression).
무결성 제약 조건은 관계 대수 또는 관계 해석 표현식으로 제공됩니다. 이미 언급했듯이, 가상의 FRP 인프라는 공통 관계 대수 확장을 제공합니다(8.5절 참조). 또한 후보 키 및 외래 키 제약 조건에 대한 특별한 구문을 제공합니다. (이 구문은 사실 기본 관계 대수 또는 관계 해석 표현식의 약어에 불과합니다.).
We consider the standard (key) constraints first:
먼저 표준(키) 제약 조건을 살펴보겠습니다:
candidate key Property = (address) candidate key Offer = (address, offerDate, bidderName, bidderAddress) candidate key Decision = (address, offerDate, bidderName, bidderAddress) candidate key Room = (address, roomName) candidate key Floor = (address, roomName) candidate key Commision = (priceBand, areaCode, saleSpeed) foreign key Offer (address) in Property foreign key Decision (address, offerDate, bidderName, bidderAddress) in Offer foreign key Room (address) in Property foreign key Floor (address) in Property
There are also some slightly more interesting, domain-specific constraints. The first insists that all properties must have at least one room:
좀 더 흥미로운 도메인별 특정 제약 조건도 있습니다. 첫 번째 제약 조건은 모든 부동산은 적어도 하나의 방을 가져야 한다고 요구합니다:
count(restrict(PropertyInfo | numberOfRooms < 1)) == 0
The next ensures that people cannot submit bids on their own property (owners are assumed to be residing at the property they are selling):
다음은 사람들이 자기 소유의 부동산에 입찰할 수 없도록 보장합니다(집주인은 자신이 판매하는 부동산에 거주하고 있다고 가정합니다):
count(restrict(Offer | bidderAddress == address)) == 0
This constraint prohibits the submission of any
Offerson a property (address) after a sale has happened (i.e. after anAcceptancehas occurred for theaddress):
이 제약 조건은 판매가 발생한 후(즉, address에 대한 거래 Acceptance가 발생한 후)에는 부동산(address)에 대한 어떤 Offer도 제출할 수 없게 합니다:
count(restrict(join(Offer, project(Acceptance, address decisionDate)) | offerDate > decisionDate)) == 0
The next constraint ensures that there are never more than 50 properties advertised on the website in the
PREMIUMprice band:
다음 제약 조건은 웹사이트에 광고된 부동산 중 PREMIUM 가격대의 부동산이 50개를 넘지 않도록 보장합니다:
count(restrict(extend(PropertyForWebSite, (priceBand = priceBandForPrice(price))) | priceBand == PREMIUM)) < 50
This is an interesting constraint because it depends (directly as it happens) on a user-defined function (
priceBandForPrice). One implication of this is that changes to function definitions (as well as changes to essential state) could — if unchecked — cause the system to violate its constraints. No FRP infrastructure can allow this.
이 제약 조건은 흥미로운데, 사용자 정의 함수인 priceBandForPrice에 직접적으로 의존하기 때문입니다.
이 함수의 한 가지 의미는 함수 정의의 변경(본질적인 상태의 변경과 마찬가지로)이 시스템이 제약 조건을 위반하도록 만들 수 있다는 것입니다.
FRP 인프라는 이런 것을 허용하면 안됩니다.
Fortunately there are two straightforward approaches to solving this. The first is that the infrastructure could treat function definitions as data (essential state) and apply the same kind of modification checks. The alternative is that it could refuse to run a system with a new function version which causes existing data to be considered invalid. In this latter case manual state changes would be required to restore integrity and to allow the system became operational again.
다행히도 이 문제를 해결하는 두 가지 간단한 방법이 있습니다.
- 첫 번째는 인프라가 함수 정의를 데이터(본질적인 상태)로 취급하고 동일한 종류의 수정 검사를 적용할 수 있다는 것입니다.
- 두 번째 방법은 기존 데이터를 잘못된 것으로 간주하는 새로운 함수의 버전으로는 시스템을 실행하지 않도록 거부하도록 하는 것입니다.
후자의 경우 시스템이 다시 운영될 수 있도록 하려면 무결성을 복원하고 수동으로 상태를 변경해야 합니다.
Finally, no single bidder can submit more than 10 offers (over time) on a single
Property. This constraint works by first computing the number of offers made by each bidder (bidderName,bidderAddress) on eachProperty(address), and ensuring that this is never more than 10:
마지막으로, 단일 입찰자는 하나의 부동산(Property)에 대해 10개를 초과하는 Offer를 제출할 수 없습니다.
이 제약 조건은 먼저 각 Property(address)에 대해 각 입찰자(bidderName, bidderAddress)가 제출한 Offer의 수를 계산하고, 이 수가 10개를 초과하지 않도록 보장함으로써 작동합니다:
count(restrict(summarize(Offer, project(Offer, address bidderName bidderAddress), numberOfOffers = count()) | numberOfOffers > 10)) == 0
Once the system is deployed, the FRP infrastructure will reject any state modification attempts which would violate any of these integrity constraints.
시스템이 배포되면, FRP 인프라는 이러한 무결성 제약 조건을 위반하는 모든 상태의 변경 시도를 거부합니다.
10.4 Accidental State and Control
우발적인 상태와 제어
The accidental state and control component of an FRP system consists solely of a set of declarations which represent performance hints for the infrastructure (see section 9.1.3). In this example the accidental state and control is a set of three hint declarations.
FRP 시스템의 우발적인 상태와 제어 컴포넌트는 인프라에 대한 성능 힌트를 나타내는 선언 집합으로만 구성됩니다(9.1.3절 참조).
이 예제에서 우발적인 상태와 제어는 세 가지 힌트 선언의 집합입니다.
declare store PropertyInfo
This declaration is simply a hint to the infrastructure to request that the
PropertyInfoderived relation is actually stored (ie cached) rather than continually recalculated.
이 선언은 단순히 PropertyInfo 파생 관계가 계속 다시 계산되는 것이 아니라 실제로 저장(캐시)되도록 인프라에 요청하는 힌트입니다.
declare store shared Room Floor
This hint instructs the infrastructure to denormalize the
RoomandFloorrelations into a single shared storage structure. (Note that because we are able to express this as part of the accidental state and control we have not been forced to compromise the essential parts of our system which still treatRoomandFloorseparately).
이 힌트는 인프라가 Room과 Floor 관계를 하나의 공유된 스토리지 구조로 비정규화하도록 지시합니다.
(이것을 우발적인 상태와 제어의 일부로 표현할 수 있기 때문에 여전히 Room과 Floor를 별도로 처리하는 시스템의 본질적인 부분은 손상되지 않았습니다).
declare store separate Property (photo)
This hint instructs the infrastructure to store the
photoattribute of thePropertyrelation separately from its other attributes (because it is not frequently used).These three hints have all focused on state (
PropertyInfois accidental state, and the other two declarations are concerned with accidental aspects of state). Larger systems would probably also include accidental control specifications for performance reasons.
이 힌트는 인프라에 Property 관계의 photo 속성을 다른 속성과 별도로 저장하도록 지시합니다(자주 사용되지 않기 때문).
이 세 가지 힌트는 모두 상태에 초점을 맞추고 있습니다.
( PropertyInfo는 우발적인 상태이고, 다른 두 선언은 상태의 우발적인 측면과 관련이 있습니다).
대형 시스템은 성능상의 이유로 우발적인 제어 사양도 포함할 수 있습니다.
10.5 Other
그 외
The feeders and observers for this system would be fairly simple — feeding user input into
Decisions,Offersetc., and directly observing and displaying the various derived relations as output (e.g.OpenOffers,PropertyForWebSiteandCommisionDue).Because of this it is reasonable to expect that the feeders and observers would require no custom coding at all, but could instead be specified in a completely declarative fashion.
One extension which might require a custom observer would be a requirement to connect
CommissionDueinto an external payroll system.
이 시스템의 피더와 옵저버는 매우 간단합니다.
사용자 입력을 Decisions, Offers 등에 입력하고, OpenOffers, PropertyForWebSite 및 CommisionDue와 같은 다양한 파생 관계를 직접 관찰하고 출력으로 표시하는 것입니다.
따라서 피더와 옵저버는 사용자 정의 코딩이 전혀 필요하지 않고, 완전히 선언적인 방식으로 지정할 수 있다고 예상하는 것이 합리적입니다.
커스텀 옵저버가 필요할만한 확장 한 가지가 있다면 CommissionDue를 외부 급여 체계에 연결해야 하는 요구 사항입니다.
11 Related Work
관련 작업
FRP draws some influence from the ideas of [DD00]. In contrast with this work however, FRP is aimed at general purpose, large-scale application programming. Additionally FRP focuses on a separate, functional, sub-language and has different ideas about the use of types. Finally the accidental component of FRP has a broader range than the physical / logical mapping of traditional DBMSs. There are also some similarities to Backus’ Applicative State Transition systems [Bac78], and to the Aldat project at McGill [Mer85] which investigated general purpose applications of relational algebra.
FRP는 [DD00]의 아이디어에서 영향을 받았습니다. 그러나 이 작업과는 달리 FRP는 일반 목적의 대규모 응용 프로그램 프로그래밍을 목표로 하고 있습니다. 또한 FRP는 별도의 함수형 하위 언어에 초점을 맞추고 있으며, 타입의 사용에 대해서도 다른 관점을 가지고 있습니다. 마지막으로 FRP의 우발적인 컴포넌트는 전통적인 DBMS의 물리적/논리적 매핑보다 더 넓은 범위를 다룹니다. 또한 Backus의 Applicative State Transition 시스템과 관계 대수의 일반적인 응용 분야를 연구한 McGill 대학의 Aldat 프로젝트에도 몇 가지 유사한 점이 있습니다.
12 Conclusions
결론
We have argued that complexity causes more problems in large software systems than anything else. We have also argued that it can be tamed — but only through a concerted effort to avoid it where possible, and to separate it where not. Specifically we have argued that a system can usefully be separated into three main parts: the essential state, the essential logic, and the accidental state and control.
우리는 대규모 소프트웨어 시스템에서 복잡성이 다른 것보다 더 많은 문제를 일으킨다고 주장했습니다. 또한 복잡성은 가능한 한 회피하고, 피할 수 없는 경우 분리하여 통제할 수 있다고 주장했습니다. 특히 우리는 시스템을 본질적인 상태, 본질적인 논리, 우발적인 상태와 제어라는 세 가지 주요 부분으로 유용하게 분리할 수 있다고 주장했습니다.
We believe that taking these principles and applying them to the top level of a system design — effectively using different specialised languages for the different components — can offer more in terms simplicity than can the unstructured adoption of any single general language (be it imperative, logic or functional). In making this argument we briefly surveyed each of the common programming paradigms, paying some attention to the weaknesses of object-orientation as a particular example of an imperative approach.
이러한 원칙을 시스템 설계의 최상위 레벨에 적용하여 다양한 컴포넌트에 대해 서로 다른 전문적인 언어를 효과적으로 사용하면 명령형, 논리형, 함수형 등의 서로 다른 일반적인 프로그래밍 언어를 단순히 채택하는 것보다 단순성의 측면에서 더 많은 것을 제공할 수 있다고 믿습니다.
이런 주장을 뒷받침하기 위해 우리는 각각의 일반적인 프로그래밍 패러다임을 간단히 살펴보았고, 명령형 접근 방식의 구체적인 사례인 객체 지향의 약점에 대해서도 알아보았습니다.
In cases (such as existing large systems) where this separation cannot be directly applied we believe the focus should be on avoiding state, avoiding explicit control where possible, and striving at all costs to get rid of code.
So, what is the way out of the tar pit? What is the silver bullet? …it may not be FRP, but we believe there can be no doubt that it is simplicity.
이러한 분리를 직접 적용할 수 없는 경우(기존의 대규모 시스템이라던가)에는 상태를 피하고, 가능한 한 명시적인 제어를 사용하지 않고, 코드를 제거하기 위해 최대한 노력하는 데 초점을 맞춰야 한다고 생각합니다.
그렇다면 타르 구덩이에서 벗어날 수 있는 방법은 무엇일까요? 은총알은 과연 무엇일까요? …FRP가 아닐 수도 있겠지만, 우리는 '단순성'이 그것이라는 데에는 의심의 여지가 없다고 믿습니다.
References
[Bac78] John W. Backus. Can programming be liberated from the von Neumann style? a functional style and its algebra of programs. Commun. ACM, 21(8):613–641, 1978.
[Bak93] Henry G. Baker. Equal rights for functional objects or, the more things change, the more they are the same. Journal of Object-Oriented Programming, 4(4):2–27, October 1993.
[Boo91] G. Booch. Object Oriented Design with Applications. Benjamin/Cummings, 1991.
[Bro86] Frederick P. Brooks, Jr. No silver bullet: Essence and accidents of software engineering. Information Processing 1986, Proceedings of the Tenth World Computing Conference, H.-J. Kugler, ed.: 1069– 76. Reprinted in IEEE Computer, 20(4):10-19, April 1987, and in Brooks, The Mythical Man-Month: Essays on Software Engineering, Anniversary Edition, Chapter 16, Addison-Wesley, 1995.
[Che76] P. P. Chen. “The Entity-Relationship Model”. ACM Trans. on Database Systems (TODS), 1:9–36, 1976.
[Cod70] E. F. Codd. A relational model of data for large shared data banks. Comm. ACM, 13(6):377–387, June 1970.
[Cod79] E. F. Codd. Extending the database relational model to capture more meaning. ACM Trans. on Database Sys., 4(4):397, December 1979.
[Cod90] E. F. Codd. The Relational Model for Database Management, Ver- sion 2. Addison-Wesley, 1990.
[Cor91] Fernando J. Corbat ́o. On building systems that will fail. Commun. ACM, 34(9):72–81, 1991.
[Dat04] C. J. Date. An Introduction to Database Systems. Addison Wesley, 8th edition, 2004.
[DD00] Hugh Darwen and C. J. Date. Foundation for Future Database Systems: The Third Manifesto. Addison-Wesley, 2nd edition, 2000.
[Dij71] Edsger W. Dijkstra. On the reliability of programs. circulated privately, 1971.
[Dij72] Edsger W. Dijkstra. The humble programmer. Commun. ACM, 15(10):859–866, 1972.
[Dij97] Dijkstra. The tide, not the waves. In Peter J. Denning and Robert M. Metcalfe, editors, Beyond Calculation: The Next Fifty Years of Computing, Copernicus, 1997. 1997.
[Eco04] Managing complexity. The Economist, 373(8403):89–91, 2004.
[EH97] Conal Elliott and Paul Hudak. Functional reactive animation. In Proceedings of the ACM SIGPLAN International Conference on Functional Programming (ICFP-97), volume 32,8 of ACM SIGPLAN Notices, pages 263–273, New York, June 9–11 1997. ACM Press.
[HJ89] I. Hayes and C. Jones. Specifications are not (necessarily) executable. IEE Software Engineering Journal, 4(6):330–338, November 1989.
[Hoa81] C. A. R. Hoare. The emperor’s old clothes. Commun. ACM, 24(2):75–83, 1981.
[Kow79] Robert A. Kowalski. Algorithm = logic + control. Commun. ACM, 22(7):424–436, 1979.
[Mer85] T. H. Merrett. Persistence and Aldat. In Data Types and Persistence (Appin), pages 173–188, 1985.
[NR69] P.NaurandB.Randell.Software engineering report of a conference sponsored by the NATO science committee Garmisch Germany 7th-11th October 1968, January 01 1969.
[OB88] A. Ohori and P. Buneman. Type inference in a database programming language. In Proceedings of the 1988 ACM Conference on LISP and Functional Programming, Snowbird, UT, pages 174–183, New York, NY, 1988. ACM.
[O’K90] Richard A. O’Keefe. The Craft of Prolog. The MIT Press, Cambridge, 1990.
[PJ+03] Simon Peyton Jones et al., editors. Haskell 98 Language and Libraries, the Revised Report. CUP, April 2003.
[SS94] Leon Sterling and Ehud Y. Shapiro. The Art of Prolog - Advanced Programming Techniques, 2nd Ed. MIT Press, 1994.
[SU96] Randall B. Smith and David Ungar. A simple and unifying approach to subjective objects. TAPOS, 2(3):161–178, 1996.
[vRH04] Peter van Roy and Seif Haridi. Concepts, Techniques, and Models of Computer Programming. MIT Press, 2004.
[Wad95] Philip Wadler. Monads for functional programming. In Advanced Functional Programming, pages 24–52, 1995.
[Won00] Limsoon Wong. Kleisli, a functional query system. J. Funct. Program, 10(1):19–56, 2000.
주석
-
원주: By “state” we mean mutable state specifically — i.e. excluding things like (immutable) single-assignment variables which are provided by logic programming languages for example
번역: "상태"란 특별히 변경 가능한 상태(mutable state)를 의미합니다. 예를 들어 논리 프로그래밍 언어에서 제공하는 (불변) 단일 할당 변수와 같은 것은 이 개념에서 제외됩니다. ↩ ↩2 -
원주: Indeed early versions of the Oz language (with implicit concurrency at the statement level) were somewhat of this kind [vRH04, p809]
번역: 실제로 Oz 프로그래밍 언어의 초기 버전이 바로 이런 종류의 언어였습니다.(명령문 수준에서 암시적인 동시성이 있었음) ↩ ↩2 -
원주: Particularly unnecessary data abstraction. We examine an argument that this is actually most data abstraction in section 9.2.4.
번역: 특히 불필요한 데이터 추상화. 9.2.4 절에서 이것이 실제로 대부분의 데이터 추상화에 해당한다는 주장을 살펴봅니다. ↩ ↩2 -
원주: this particular problem doesn’t really apply to object-oriented languages (such as CLOS) which are based upon generic functions — but they don’t have the same concept of encapsulation.
번역: 이 문제는 generic 함수를 기반으로 하는 OOP 언어(예: CLOS)에는 해당되지 않습니다. 캡슐화 개념이 다르기 때문입니다. ↩ ↩2 -
역주: fold와 map은 함수형 언어에서 흔히 사용하는 함수 유형이다. fold는 reduce라고도 부르며, 리스트의 원소를 하나씩 꺼내서 함수를 적용하고, 그 결과를 누적시킨 결과를 리턴한다. map은 리스트의 원소를 하나씩 꺼내서 함수를 적용하고, 그 결과 리스트를 리턴한다. ↩
-
원주: We are using the term here to cover everything apart from the pure core of Prolog — for example we include what are sometimes referred to as the meta-logical features
번역: 여기에서는 Prolog의 순수한 핵심 외의 '모든 것'을 표현하는 용어로 '논리 확장'을 사용하고 있습니다. '논리 확장'의 예로는 meta-logical 기능들이 있습니다. ↩ ↩2 -
원주: We include the word “relevant” here because in many cases there may be many possible acceptable solutions — and in such cases the requirements can be ambiguous in that regard, however that is not considered to be a “relevant” ambiguity, i.e. it does not correspond to an erroneous omission from the requirements.
번역: "관련된"이라는 단어를 포함시킨 이유는, 경우에 따라 여러 가지 선택 가능한 해결책이 있을 수 있으며, 그런 경우에는 요구사항이 모호할 수는 있어도 "관련된" 모호함으로 볼 수는 없기 때문입니다. 즉, 이러한 모호함은 요구사항에서의 잘못된 누락에 해당되지 않습니다. ↩ ↩2 -
원주: In the presence of irrelevant ambiguities this will mean that the infrastructure must choose one of the possibilities, or perhaps even provide all possible solutions
번역: 관련이 없는 모호함이 있는 경우라면, 인프라는 가능성 중 하나를 선택하거나 가능한 모든 솔루션을 제공해야 합니다. ↩ ↩2 -
원주: this assumption is generally known as the “synchrony hypothesis”
번역: 이 가정은 일반적으로 "동기화 가설"이라 알려져 있습니다. ↩ ↩2 -
원주: Care must be taken that the resulting reduction rules are confluent and terminating.
번역: 결과적으로 도출되는 축소 규칙이 '합류성(confluence)'과 '정지성(termination)'을 만족하도록 주의를 기울여야 합니다.
역주: '합류성'을 갖는 시스템은 동일한 결과를 산출해내는 가능한 구현이 여럿이어서, 여러 재작성이 가능하다. 이에 대해 추가로 위키백과의 Confluence (abstract rewriting)와 합류성도 참고할 것. '정지성'은 연산 과정이 결국엔 종료되는 성질을 말한다. ↩ ↩2 -
원주: because it can make the logic easier to express — as we shall see in section 7.3.2
번역: 왜냐하면 로직을 표현하기 더 쉽게 만들 수 있기 때문입니다. 이에 대해서는 7.3.2 절에서 살펴보도록 하겠습니다. ↩ ↩2 -
원주: We are implicitly considering time as an additional input.
번역: 여기에서는 암묵적으로 '시간'을 추가 입력으로 보고 있습니다. ↩ ↩2 -
원주: There is some limited similarity between our goal of “Separate” and the goal of separation of concerns as promoted by proponents of Aspect Oriented Programming — but as we shall see in section 7.3.2, exactly what is meant by separation is critical.
번역: 우리의 목표인 "분리"와 '관점지향 프로그래밍'에서 말하는 '관심사의 분리' 사이에는 다소 유사성이 있긴 하지만, '분리'가 어떤 것을 의미하는지를 정확하게 파악하는 것이 중요합니다. 이에 대해서는 7.3.2 절에서 살펴보도록 하겠습니다. ↩ ↩2 -
원주: indeed it should be perfectly possible for different users of the same essential system to employ different accidental components — each designed for their particular needs
번역: 실제로, 같은 본질적 시스템을 사용하는 서로 다른 사용자들이 자신의 특정한 요구에 맞게 설계된 다양한 우발적인 컴포넌트를 사용하는 것이 완벽하게 가능해야 합니다. ↩ ↩2 -
원주: or different subsets of the same language, provided it is possible to forcibly restrict each component to the relevant subset.
번역: 또는 동일한 언어의 다른 하위 집합으로, 각 컴포넌트를 관련된 하위 집합으로 강제로 제한할 수 있는 경우입니다. ↩ ↩2 -
원주: Unfortunately most contemporary DBMSs are somewhat limited in the degree of flexibility permitted by the physical/logical mapping. This has the unhappy result that physical performance concerns can invade the logical design even though avoiding exactly this was one of Codd’s most important original goals.
번역: 안타깝게도 대부분의 최신 DBMS는 물리적/논리적 매핑을 허용하는 유연성의 정도가 다소 제한되어 있습니다. 이런 문제를 정확히 회피하는 것이 Codd의 가장 중요한 본래의 목표 중 하나였는데도 불구하고, 물리적인 성능 문제가 논리적 설계를 침범할 수 있다는 불행한 결과를 초래합니다. ↩ ↩2 -
역주: C. J. Date. "An Introduction to Database Systems"의 저자. ↩
-
역주: 'OOP, XML의 데이터 구조화 접근 방식'은 네트워크 모델 그리고 계층형 모델의 접근 방식과 닮은 점이 있다. 이 넷은 모두 데이터를 구조화하고 관계를 설정하는 데 있어 명시적인 '접근 경로'를 필요로 한다. 이 절에서 저자는 '접근 경로'에 의존하게 되면 특정한 요구사항을 충족시키기 어려우며, 관계형 모델의 접근법이 더 유연하다는 주장을 하고 있다. ↩
-
원주: Not to be confused with functional reactive programming [EH97] which does in fact have some similarities to this approach, but has no intrinsic focus on relations or the relational model
번역: '함수형 반응형 프로그래밍'과 혼동하지 않아야 합니다. 접근 방식 측면에서 일부 유사성이 있긴 하지만 함수형 반응형 프로그래밍은 관계 또는 관계형 모델에 초점을 맞추지 않습니다. ↩ ↩2 -
원주: Aside from token experimental implementations of FRP infrastructures created by the authors.
번역: 이 논문의 저자들이 만든 FRP 인프라의 토큰 실험적 구현을 제외하면 말이죠. ↩ ↩2 -
원주: By user-defined we mean specific to this particular FRP system (as opposed to pre- provided by an underlying infrastructure).
번역: '사용자 정의'란 기본 인프라에서 미리 제공한 것이 아니라, 여기에서 언급하는 특정한 FRP 시스템과 관련된 것을 의미합니다. ↩ ↩2 -
원주: Equally, traditional OOP pays little attention to the accidental / essential split which was also discussed in section 7.3.2.
번역: 이와 마찬가지로, 전통적인 OOP는 7.3.2 절에서 논의한 우발적/본질적 분할에 대해서는 거의 관심을 기울이지 않습니다. ↩ ↩2 -
원주: see section 8.1.1 for a definition of this term.
번역: 이 용어의 정의는 8.1.1절을 참고할 것. ↩ ↩2 -
원주: aside from the ease of expression issue discussed in section 9.1.4.
번역: 9.1.4절에서 설명할 표현의 용이성 문제를 제외하면 말이죠. ↩ ↩2 -
원주: Other systems connected electronically are considered equivalent to users inputting data for these purposes.
번역: 전기적으로 연결된 다른 시스템은 이런 목적으로 데이터를 입력하는 것과 동등하게 간주합니다. ↩ ↩2 -
원주: In fact one implication of this is that it is in fact necessary for the assignment command to support multiple simultaneous assignment of several distinct relation values to several distinct relvars — this is to avoid temporary inconsistencies which could otherwise occur with integrity constraints that involved multiple relvars.
번역: 할당 명령이 여러 개의 서로 다른 관계 값을 여러 개의 relvar에 동시에 할당하는 것을 지원해야 한다는 것은, 여러 개의 관계와 관련된 무결성 제약 조건에서 발생할 수 있는 일시적인 불일치를 피하기 위한 것입니다. ↩ ↩2 -
원주: Some systems — for example the Kleisli system used in bio-informatics [Won00] — seek to avoid this conversion by providing support for more complex structures such as nested relations. We believe that the simplicity gained from having flat relations throughout the system is worth the effort sometimes involved at the system edges (section 9.2.4 describes some of the rationale behind this).
번역: 일부 시스템에서는(예: 생물 정보학에서 사용하는 Kleisli 시스템) 중첩 관계와 같은 더 복잡한 구조를 지원하는 방식으로 이런 변환을 피하려 합니다. 우리는 시스템 전체에 걸쳐 플랫 관계(flat relations)를 사용함으로써 얻을 수 있는 단순성이 때때로 시스템 경계에서 가치가 있다고 생각합니다. ↩ ↩2 -
원주: A prototype implementation of the essential state and essential logic infrastructure — the most significant parts — was developed in a mere 1500 lines of Scheme. In fact this prototype supported not only the relational algebra but also some temporal extensions. The effort involved in this is insignificant when compared to the hundreds of man-years often involved in large systems.
번역: 가장 중요한 부분인 본질적 상태와 본질적 논리 인프라의 프로토타입 구현은 단 1500줄의 Scheme 코드로 개발됐습니다. 이 프로토타입은 실제로 관계 대수 뿐만 아니라 일부 시간적 확장도 지원했습니다. 대규모 시스템을 만들 때 종종 수백 man/year 가 소요되는 것과 비교하면 이 작업에 필요했던 노력은 미미한 수준입니다. ↩ ↩2 -
원주: The exception might be in the kind of highly interactive scenario considered in sections 7.2.2 and 7.3.1
번역: 예외적으로 7.2.2, 7.3.1절에서 고려한 고도의 인터랙티브 시나리오가 있을 수 있습니다. ↩ ↩2 -
원주: We’re talking here solely about fixing the system itself — of course FRP can’t guarantee that errors in the logic won’t escape and affect the real world via observers!
번역: 물론 FRP는 논리상의 오류가 있을 때에는 옵저버를 통해 실제 세계에 영향을 미치지 않는다고 보장하지 않습니다! ↩ ↩2