가용성(Availability)
시스템이 다운되지 않고 정상 운영되는 시간의 비율
정의
시간을 기준으로 한 가용성
From: 위키백과
\[\text{가용성} = { \text{Uptime} \over \text{Uptime} + \text{Downtime} }\]가용성(可用性, Availability)이란 서버와 네트워크, 프로그램 등의 정보 시스템이 정상적으로 사용 가능한 정도를 말한다. 가동률과 비슷한 의미이다. 가용성을 수식으로 표현할 경우, 가용성(Availability)이란 정상적인 사용 시간(Uptime)을 전체 사용 시간(Uptime+Downtime)으로 나눈 값을 말한다. 이 값이 높을수록 "가용성이 높다"고 표현한다. 가용성이 높은 것을 고가용성(HA, High Availability)이라고 한다.
\(\text{Availability} = { E[\text{Uptime}] \over E[\text{Uptime}] + E[\text{Downtime}] }\)
From: 사이트 신뢰성 엔지니어링
이 방식에 대해 "사이트 신뢰성 엔지니어링"에서는 조금 더 섬세하게 정의한다.2
\[\text{가용성} = { \text{Uptime} \over \text{Uptime} + \text{(unplanned) Downtime} }\]From: 트랜잭션 처리의 원리
다음은 "트랜잭션 처리의 원리"에서 인용한 것이다.
\[\text{가용성} = { \text{평균가동시간} \over \text{평균가동시간} + \text{평균복구시간} }\]TP 시스템에 필요한 중요한 요구사항은 시스템이 항상 가동상태를 유지해야 한다는 것이다. 이것은 가용성이 매우 높은 시스템이어야 한다는 뜻이다. 그런 시스템을 흔히 '\(24 \times 365\)'라고도 하는데, 매일 24시간 연간 365일, 즉 연중 무휴로 가동하는 시스템이라는 의미이다. 가용성(availability)이 높은 시스템이란 정확하게 가동되면서 기대하는 결과가 나오는 시스템이다. 가용성은 두 가지 요인에 의해서 감소한다. 한 요인은 시스템에 장애가 발생하는 비율이다. 장애라는 말은 시스템이 잘못 응답하거나 응답을 하지 않음을 의미한다. 시스템의 다른 조건이 같을 때 장애가 자주 발생한다면 그 시스템은 가용성이 낮은 시스템이다. 또 하나의 요인은 복구시간이다. 시스템의 다른 조건이 같을 때 장애가 발생한 후에 시스템을 복구하는 데 걸리는 시간이 길수록 시스템의 가용성은 낮아진다. 이런 개념은 평균가동시간(mean time between failure, MTBF)와 평균복구시간(mean time to repair, MTTR)으로 표현된다. 평균가동시간은 장애가 발생하기 전에 시스템이 가동되는 평균시간이다. 평균가동시간은 시스템 신뢰성의 척도다. 평균복구시간은 장애가 발생한 후에 시스템을 수리하거나 복구하는 데 걸리는 시간이다. 이들 두 척도를 이용하여 가용성을 \({ MTBF \over MTBF + MTTR }\)로 정의할 수 있다. 그러므로 가용성은 신뢰성이 증가할수록, 복구시간이 감소할수록 향상된다.
– 트랜잭션 처리의 원리. 7 시스템 복구. 239쪽.3
From: 가상 면접 사례로 배우는 대규모 시스템 설계 기초
고가용성(high availability)은 시스템이 오랜 시간 동안 지속적으로 중단 없이 운영될 수 있는 능력을 지칭하는 용어다. 고가용성을 표현하는 값은 퍼센트(percent)로 표현하는데, 100%는 시스템이 단 한 번도 중단된 적이 없었음을 의미한다. 대부분의 서비스는 99%에서 100% 사이의 값을 갖는다.
SLA(Service Level Agreement)는 서비스 사업자(service provider)가 보편적으로 사용하는 용어로, 서비스 사업자와 고객 사이에 맺어진 합의를 의미한다. 이 합의에는 서비스 사업자가 제공하는 서비스의 가용시간(uptime)이 공식적으로 기술되어 있다. 아마존, 구글, 그리고 마이크로소프트 같은 사업자는 99% 이상의 SLA를 제공한다. 가용시간은 관습적으로 숫자 9를 사용해 표시한다. 9가 많으면 많을수록 좋다고 보면 된다.
– 가상 면접 사례로 배우는 대규모 시스템 설계 기초. 2장 개략적인 규모 추정. 36쪽.
책에서 소개하고 있는 각 서비스 사업자들의 SLA 링크는 다음과 같다.
요청 성공률을 기초로 한 가용성
"사이트 신뢰성 엔지니어링"에서는 시간 기준의 가용성의 대안으로 요청 성공률에 기초한 가용성을 정의한다.
그러나 구글에서는 시간 기준의 가용성 지표는 그다지 의미가 없다. 그 이유는 우리는 전 세계에 분산된 서비스를 운영하기 때문이다. 구글이 채택하고 있는 장애 분리(fault isolation) 방식 덕분에 우리는 특정 서비스의 트래픽 중 일부를 주어진 시간 동안 세계의 어느 한 지역에 제공하고 있는 셈이다(다시 말하면, 우리는 전체 시간 중 최소 일부는 '정상 동작 중인' 상태다). 그래서 우리는 업타임과 관련된 지표들 대신 요청 성공률(request success rate)에 기초한 가용성을 정의한다. [식 3-2]는 특정한 운영 시간 대비 성공률에 기반한 지표들을 계산하는 수식이다.
\[\text{가용성} = { \text{성공한 요청 수} \over \text{전체 요청 수} }\]예를 들어 하루에 250만 개의 요청을 처리하는 시스템의 경우 하루에 발생하는 에러가 250개 이내라면 일일 가용성 목표치 99.99%를 달성할 수 있다.2
가용성 향상
목표 수준 설정
구글에서는 다음을 기준으로 삼아 목표 가용성 수준(target level of availability)을 결정한다고 한다.4
- 사용자는 어느 정도 수준의 서비스를 기대하는가?
- 이 서비스가 수익과 직접적으로 연관이 있는가(구글의 수익 혹은 고객의 수익?)
- 유료 서비스인가 아니면 무료 서비스인가?
- 시장에 경쟁자가 있다면 그 경쟁자는 어느 정도 수준의 가용성을 제공하는가?
- 이 서비스는 개인 사용자를 위한 서비스인가 기업 사용자를 위한 서비스인가?
높은 가용성을 얻으려면
일반적으로 높은 가용성을 얻으려면 다음 사항들에 대해 고려해 두어야 한다.
- 환경 - 물리적 환경인 전원, 통신회선, 항온항습기 등의 장애를 방지한다.
- 시스템 관리 - 시스템 관리자 및 벤더의 유지보수 오류에 기인하는 장애를 방지한다.
- 하드웨어 - 어떤 컴포넌트가 장애일 경우에 다른 컴포넌트로 즉시 자동적으로 대체할 수 있도록 이중화하여 설치한다.
- 소프트웨어 - 소프트웨어의 신뢰성을 향상시키고, 장애 발생시 소프트웨어가 자동적으로 신속하게 복구될 수 있도록 한다.5
에러 예산
에러 예산은 기본적으로 모든 것에 대해 신뢰성 목표를 100% 설정하는 것은 잘못된 목표 설정이라는 관찰 결과에서 유래한 것이다(물론 페이스메이커와 자동차의 ABS 브레이크는 신뢰성 100%라는 목표가 유효한 몇 안 되는 예외다).
(중략)
사업부나 제품 담당 부서는 시스템의 목표 가용성을 반드시 설정해야 한다. 일단 목표가 설정되면 에러 예산은 1에서 목표 가용성을 뺀 값이다. 즉, 서비스의 목표 가용성이 99.99%라면 불가용한 상태인 경우는 0.01%에 해당한다. 이렇게 필연적으로 발생할 수밖에 없는 0.01%의 불가용성이 서비스의 에러 예산(error budget)이다. SRE팀은 이 에러 예산을 초과하지 않는 범위 내에서 얼마든지 자유롭게 예산을 활용할 수 있다.6
에러 예산의 활용
- 개발팀이 새로운 기능을 빠르게 출시하기 위해 감수해야 할 위험을 처리하는 데 에러 예산을 투입한다.
- 사용 예: 새로운 기능의 단계적 출시, 일부 사용자를 대상으로 한 실험 기능 출시 같은 전략의 사용.
에러 예산을 도입하면 개발팀과 SRE의 동기(incentives)에서 발생하는 구조적 충돌 역시 해소할 수 있다. 에러 예산이 도입되면 SRE들은 더 이상 '무정지 시스템' 같은 목표를 세우지 않는다. 그 대신 SRE팀과 제품 개발팀이 기능의 출시 속도를 극대화하기 위해 에러 예산을 활용하는 것에 집중하게 된다. 이런 변화는 모든 것을 바꿀 수 있다. 시스템이 정지하더라도 더 이상 상황을 장애 상황으로만 여기지 않고 혁신의 과정에서 어쩔 수 없이 발생하는 예측 가능한 상황이 되며, 이런 상황이 발생하면 개발팀과 SRE팀은 정신적 혼란에 빠지지 않고 올바르게 대응할 수 있게 된다.6
가용성 테이블
- 다음 표는 99% ~ 99.999%의 가용성을 기준으로 서비스 불가 시간을 계산해 본 것이다.
- 계산은 울프람알파로 했다.
| 가용성 | year | month | week | day | hour |
|---|---|---|---|---|---|
| 99% | 3.65 day | 7.3 hour | 1.68 hour | 14.4 min | 36 sec |
| 99.9% | 8.76 hour | 43.8 min | 10.08 min | 1.44 min | 3.6 sec |
| 99.99% | 52.56 min | 4.38 min | 60.48 sec | 8.64 sec | 0.36 sec |
| 99.999% | 5.256 min | 26.28 sec | 6.048 sec | 0.864 sec | 0.036 sec |
시스템 작업의 가용성
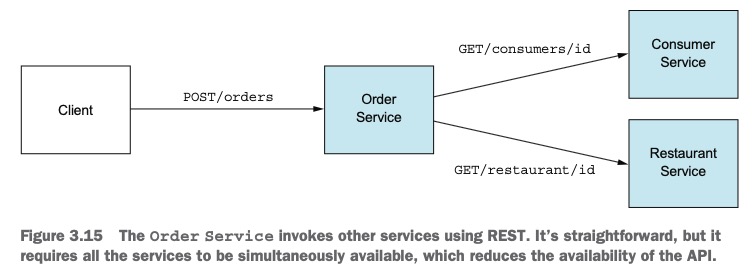
세 서비스 모두 HTTP를 사용하기 때문에 주문 생성 요청이 정상 처리되려면 세 서비스 모두 가동 중이어야 합니다. 어느 한 서비스라도 내려가면 주문 생성은 불가능합니다. 수학적으로 표현하면 시스템 작업의 가용성은 그 작업이 호출한 서비스의 가용성을 모두 곱한 값과 같습니다. 가령 주문 서비스와 이 서비스가 호출한 두 서비스의 가용성이 \(99.5%\)라면, 전체 가용성은 \(99.5^3% = 98.5%\)로 더 낮습니다. 더 많은 서비스가 요청 처리에 개입할수록 가용성은 더 낮아지겠죠.7
참고문헌
- 웹
- 도서
- [RIC] 마이크로서비스 패턴 / 크리스 리처드슨 저/이일웅 역 / 길벗 / 초판발행 2020년 01월 30일
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초 / 알렉스 쉬 저/이병준 역 / 인사이트(insight) / 2021년 07월 28일 / 원서 : System Design Interview
- 마이크로서비스 구축과 운영 / 수잔 파울러 저/서영일 역 / 에이콘출판사 / 발행 2019년 05월 31일 / 원서 : Production-Ready Microservices: Building Standardized Systems Across an Engineering Organization
- 사이트 신뢰성 엔지니어링 / 벳시 베이어, 크리스 존스, 제니퍼 펫오프, 니얼 리처드 머피 저/장현희 역 / 제이펍 / 초판 1쇄 2018년 01월 18일 / 원서 : Site Reliability Engineering: How Google Runs Production Systems
- 트랜잭션 처리의 원리 / 필립 A. 번스타인, 에릭 뉴코머 공저 / 한창래 역 / KICC(한국정보통신) / 1판 1쇄 2011년 12월 19일