fan in, fan out
요약
fan in, fan out은 디지털 논리회로에서 논리 게이트에 연결될 수 있는 입력과 출력의 최대값을 의미한다.
- fan in: 게이트에 연결될 수 있는 최대입력수.
- fan out: 게이트의 출력에 연결될 수 있는 입력게이트의 최대 수.
fan out은 소프트웨어 아키텍처에서도 비유적으로 사용되는 표현이기도 하다.
다음은 rabbitmq.com의 AMQP 0-9-1 Model Explained에 수록된 이미지이다.
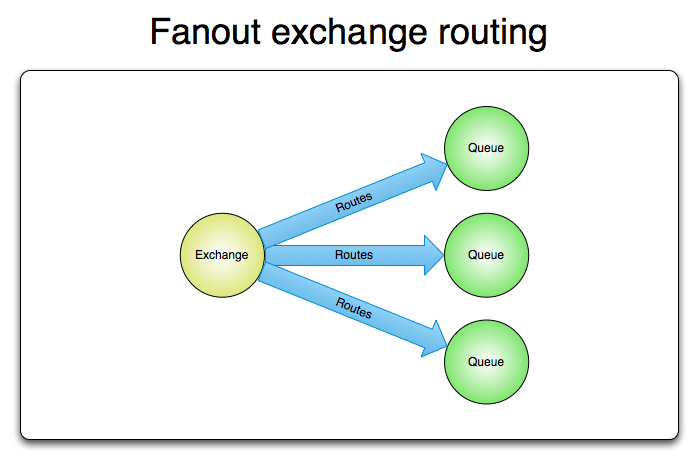
인용
From: 디지털논리회로
팬아웃(fan-out)이란 정상동작에 영향을 주지 않고 게이트 출력부에 연결할 수 있는 표준부하의 수이다. 여기서 표준부하란 대개 동일 IC군에서 다른 게이트 평가 정상적으로 동작하기 위해 게이트 입력에 필요한 전류량으로 표시된다. 즉, 팬아웃은 그 게이트의 출력에 연결될 수 있는 입력게이트의 최대수를 나타낸다. 또한 팬-아웃에 대응하여 팬-인(fan-in)을 표시하기도 한다. 논리계열의 팬-인은 논리게이트가 가질 수 있는 최대입력수를 표시한다. 1
From: ko.wikipedia.org
팬 아웃(영어: fan out)은 논리 회로에서 하나의 논리 게이트의 출력이 얼마나 많은 논리 게이트의 입력으로 사용되는지에 대해 서술할 때에 쓰인다.
팬 아웃이 크다는 말은 하나의 출력이 많은 논리게이트의 입력으로 사용된다는 뜻이다. 팬 아웃이 너무 크면 무리가 많이 가거나 신호가 제대로 전달되지 않을 수 있기 때문에 중간에 버퍼나 NOT 게이트 두 개를 연결하여 해결하기도 한다. 2
From: AMQP 0-9-1 Model Explained
역주: 원문은 RabbitMQ의 프로토콜 중 하나인 AMQP 0-9-1의 네 가지 exchange type을 설명하며, Fanout exchange type은 그 중의 하나이다. 이 문서에서는 Direct exchange type과 Fanout exchange type을 번역해 소개한다. 둘을 비교해가며 읽는 것이 Fanout을 더 잘 이해하는 데에 도움이 될 것 같기 때문이다.
Direct Exchange
A direct exchange delivers messages to queues based on the message routing key. A direct exchange is ideal for the unicast routing of messages (although they can be used for multicast routing as well). Here is how it works:
- A queue binds to the exchange with a routing key K
- When a new message with routing key R arrives at the direct exchange, the exchange routes it to the queue if K = R
Direct exchanges are often used to distribute tasks between multiple workers (instances of the same application) in a round robin manner. When doing so, it is important to understand that, in AMQP 0-9-1, messages are load balanced between consumers and not between queues.
A direct exchange can be represented graphically as follows:

Direct exchange(직접 교환기)
- Direct exchange는 메시지 라우팅 키를 토대로 여러 큐에 메시지를 전달합니다.
- Direct exchange는 유니캐스트 라우팅을 할 때 이상적입니다(멀티캐스트에도 사용할 수 있습니다).
작동 방식은 다음과 같습니다.
- 각 큐는 라우팅 K를 통해 직접 교환기에 바인딩됩니다.
- 라우팅 키가 R인 새로운 메시지가 직접 교환기에 도착하면 교환기는 그 메시지를 K = R인 큐로 전달합니다.
직접 교환기는 여러 개의 worker(같은 애플리케이션의 여러 인스턴스들)에 라운드 로빈 방식으로 task를 배포할 때 자주 사용됩니다. 이런 방식으로 작동하게 설정한 AMQP 0-9-1에서 메시지는 큐가 아니라 컨슈머들 사이에서 로드 밸런싱된다는 것을 이해하는 것이 중요합니다.
Fanout Exchange
A fanout exchange routes messages to all of the queues that are bound to it and the routing key is ignored. If N queues are bound to a fanout exchange, when a new message is published to that exchange a copy of the message is delivered to all N queues. Fanout exchanges are ideal for the broadcast routing of messages.
Because a fanout exchange delivers a copy of a message to every queue bound to it, its use cases are quite similar:
- Massively multi-player online (MMO) games can use it for leaderboard updates or other global events
- Sport news sites can use fanout exchanges for distributing score updates to mobile clients in near real-time
- Distributed systems can broadcast various state and configuration updates
- Group chats can distribute messages between participants using a fanout exchange (although AMQP does not have a built-in concept of presence, so XMPP may be a better choice)
A fanout exchange can be represented graphically as follows:

팬아웃 교환기는 바인딩된 모든 큐에 메시지를 라우팅합니다. 라우팅 키는 무시합니다. 만약 N개의 큐가 팬아웃 교환기에 바인딩되었을 때, 새로운 메시지가 교환기에 발행되었다면 해당 메시지의 복사본이 N개의 큐 모두에게 전달됩니다. 팬아웃 교환기는 메시지를 브로드캐스트 라우팅할 때 이상적입니다.
왜냐하면 팬아웃 교환기는 메시지의 복사본을 교환기에 바인딩된 모든 큐에 전달하기 때문이며, 사용 사례들도 매우 유사합니다.
- MMO 게임에서 리더보드 업데이트 또는 다양한 글로벌 이벤트에 사용할 수 있습니다.
- 스포츠 뉴스 사이트에서는 팬아웃 교환기를 사용해서 스포츠 경기 득점 업데이트를 거의 실시간으로 수많은 모바일 클라이언트에 전달할 수 있습니다.
- 분산 시스템에서는 다양한 상태와 설정 업데이트를 브로드캐스트할 수 있습니다.
- 그룹 채팅에서 팬아웃 교환기를 사용해 대화 참가자들 사이에 메시지를 배포할 수 있습니다.(AMQP에는 이에 대한 빌트인 컨셉이 없으므로 XMPP가 더 나은 선택일 수 있습니다.)
From: Go Concurrency Patterns: Pipelines and cancellation
Fan-out, fan-in
Multiple functions can read from the same channel until that channel is closed; this is called fan-out. This provides a way to distribute work amongst a group of workers to parallelize CPU use and I/O.
A function can read from multiple inputs and proceed until all are closed by multiplexing the input channels onto a single channel that’s closed when all the inputs are closed. This is called fan-in.
We can change our pipeline to run two instances of
sq, each reading from the same input channel. We introduce a new function, merge, to fan in the results:func main() { in := gen(2, 3) // Distribute the sq work across two goroutines that both read from in. c1 := sq(in) c2 := sq(in) // Consume the merged output from c1 and c2. for n := range merge(c1, c2) { fmt.Println(n) // 4 then 9, or 9 then 4 } }The
mergefunction converts a list of channels to a single channel by starting a goroutine for each inbound channel that copies the values to the sole outbound channel. Once all theoutputgoroutines have been started,mergestarts one more goroutine to close the outbound channel after all sends on that channel are done.Sends on a closed channel panic, so it’s important to ensure all sends are done before calling close. The
sync.WaitGrouptype provides a simple way to arrange this synchronization:func merge(cs ...<-chan int) <-chan int { var wg sync.WaitGroup out := make(chan int) // Start an output goroutine for each input channel in cs. output // copies values from c to out until c is closed, then calls wg.Done. output := func(c <-chan int) { for n := range c { out <- n } wg.Done() } wg.Add(len(cs)) for _, c := range cs { go output(c) } // Start a goroutine to close out once all the output goroutines are // done. This must start after the wg.Add call. go func() { wg.Wait() close(out) }() return out }
From: 데이터 중심 애플리케이션 설계
이를 조금 더 구체적으로 설명하기 위해 트위터(Twitter)를 예로 살펴보자(2012년 11월에 공개된 데이터를 토대로). 트위터의 주요 두 가지 동작은 다음과 같다.
- 트윗(tweet) 작성
- 사용자는 팔로워에게 새로운 메시지를 게시할 수 있다(평균 초당 4.6k 요청. 피크일 때 초당 12k 요청 이상).
- 홈 타임라인(timeline)
- 사용자는 팔로우한 사람이 작성한 트윗을 볼 수 있다(초당 300k 요청).
단순히 초당 12,000건의 쓰기(피크일 때의 트윗 작성 속도) 처리는 상당히 쉽다. 하지만 트위터의 확장성 문제는 주로 트윗 양이 아닌 팬 아웃(fan-out) 때문이다. 개별 사용자는 많은 사람을 팔로우하는 많은 사람이 개별 사용자를 팔로우한다. 이 두 가지 동작을 구현하는 방법은 크게 두 가지다.
(중략)
2. 각 수신 사용자용 트윗 우편함처럼 개별 사용자의 홈 타임라인 캐시를 유지한다.(그림 1-3 참고). 사용자가 트윗을 작성하면 해당 사용자를 팔로우하는 사람을 모두 찾고 팔로워 각자의 홈 타임라인 캐시에 새로운 트윗을 삽입한다. 그러면 홈 타임라인의 읽기 요청은 요청 결과를 미리 계산했기 때문에 비용이 저렴하다.
트위터의 첫 번째 버전은 접근 방식 1을 사용했는데, 시스템이 홈 타임라인 질의의 부하를 유지하기 위해 고군분투해야 했고, 그 결과 접근 방식 2로 전환했다. 게시된 트윗의 평균 속도가 홈 타임라인 읽기 속도보다 100배 정도 낮기 때문에 접근 방식 2가 더 잘 동작한다. 그래서 이 경우에는 쓰기 시점에 더 많은 일을 하고, 읽기 시점에 적은 일을 하는 것이 바람직하다.
하지만 접근 방식 2의 불리한 점은 이제 트윗 작성이 많은 부가 작업을 필요로 한다는 점이다. 평균적으로 트윗이 약 75명의 팔로워에게 전달되므로 초당 4.6k 트윗은 홈 타임라인 캐시에 초당 345k건의 쓰기가 된다. 그러나 평균값은 사용자마다 팔로워 수가 매우 다르다는 사실을 가린다. 즉 일부 사용자는 팔로워가 3천만 명이 넘는다. 이것은 단일 트윗이 홈 타임라인에 3천만 건 이상의 쓰기 요청이 될지도 모른다는 의미다! 적시에 트윗을 전송하는 작업이 (트위터는 5초 이내에 팔로워에 게 트윗을 전송하려고 노력한다) 중요한 도전 과제다.
트위터 사례에서 사용자당 팔로워의 분포(해당 사용자의 트윗 빈도에 따라 편중될 수도 있음)는 팬 아웃 부하를 결정하기 때문에 확장성을 논의할 때 핵심 부하 매개변수가 된다. 애플리케이션마다 특성은 매우 다르지만 부하에 대한 추론에 비슷한 원리를 적용할 수 있다.
트위터 일화의 최종 전개는 다음과 같다. 접근 방식 2가 견고하게 구현돼 트위터는 두 접근 방식의 혼합형(hybrid)으로 바꾸고 있다. 대부분 사용자의 트윗은 계속해서 사람들이 작성할 때 홈 타임라인에 펼쳐지지만 팔로워 수가 매우 많은 소수 사용자(예를 들어 유명인)는 팬 아웃에서 제외된다. 사용자가 팔로우한 유명인의 트윗은 별도로 가져와 접근 방식 1처럼 읽는 시점에 사용자의 홈 타임 라인에 합친다. 이 혼합형 접근 방식은 좋은 성능으로 지속적인 전송이 가능하다. 조금 더 기술적인 근거를 다룬 후에 12장에서 트위터 사례를 다시 설명한다. 3

참고문헌
- AMQP 0-9-1 Model Explained (rabbitmq.com)
- Fan out (wikipedia), 팬 아웃 (wikipedia)
- Go Concurrency Patterns: Pipelines and cancellation
- 데이터 중심 애플리케이션 설계 / 마틴 클레프만 저/정재부, 김영준, 이도경 역 / 위키북스 / 초판발행 2018년 04월 12일
- 디지털논리회로 / 김형근, 손진곤 공저 / 한국방송통신대학교출판문화원 / 3개정판 4쇄 발행 2021년 01월 25일