데이터 중심 애플리케이션 설계.03.저장소와 검색
03.Storage and Retrieval
개요
- 이 문서는 [[Designing-Data-Intensive-Applications]]책의 3장을 공부하며 메모한 것입니다.
- 이 문서는 메모일 뿐이니 자세한 내용은 교재를 참고해야 합니다.
이번 장에서는
- 관계형 DB와 NoSQL DB에 사용되는 저장소 엔진에 대해 공부한다.
- 로그 구조(log-structured) 계열 저장소 엔진과 (B-tree 같은) 페이지 지향(page-oriented) 계열 저장소 엔진을 검토한다.
데이터베이스를 강력하게 만드는 데이터 구조
많은 데이터베이스는 내부적으로 추가 전용(append-only) 데이터 파일인 로그(log)를 사용한다.
- 로그 : 연속된 추가 전용 레코드(an append-only sequence of records)
데이터베이스에서 특정 키의 값을 효율적으로 찾기 위해서는 색인(index)이 필요하다.
- 색인을 잘 선택하면 읽기 질의 속도가 향상된다.
- 그러나 색인은 쓰기 속도를 떨어뜨린다.
- 데이터를 쓸 때마다 색인도 갱신해야 하기 때문.
- 이 문제 때문에 DB는 일반적으로 모든 것을 색인하지는 않는다.
해시 색인
가장 간단한 색인 전략
- 색인으로 key-value 저장소를 쓴다.
- key 값에 value로 데이터 파일의 바이트 오프셋을 넣어둔다.
- 해시 맵을 전부 메모리에 유지하면 읽기/쓰기를 고성능으로 할 수 있다.
파일에 계속 추가만 한다면 디스크 공간이 부족해진다. 어떻게 해결하는가?
특정 크기의 segment로 로그를 나누는 방식을 사용하자.
- 특정 크기에 도달하면 세그먼트 파일을 닫고 새로운 세그먼트 파일에 쓴다.
- 세그먼트 파일에 대해 compaction을 하는 방법도 있다.
- compaction : 로그에서 중복된 키를 버리고 각 키의 최신 개인 값만 유지하는 것.
- compaction을 하면 세그먼트가 작아지므로, 여러 세그먼트를 병합할 수 있다.
- 세그먼트는 append-only 이기 때문에,
- 병합할 세그먼트는 새로운 파일로 만들도록 한다.
- compaction 작업을 할 때에도 새로운 파일로 만들도록 한다.
- compaction 도중에는 이전 세그먼트 파일을 사용해 읽기/쓰기 요청을 처리한다.
- 병합/compaction이 끝난 이후에 이전 세그먼트를 삭제.
- 조회할 때에는 다음과 같이 한다.
- 세그먼트 해시 맵에 찾으려 하는 key가 있는지 확인한다.
- 세그먼트 해시 맵에 key 가 없으면, 다음 세그먼트 해시 맵에서 key를 찾는다.
append-only 세그먼트의 장점
- 세그먼트 파일이 append-only이면 동시성/고장 복구가 간단해진다.
- 값을 업데이트하는 동안 DB가 죽어도, 이전 값과 새로운 값(쓰다가 죽은 값)이 남아 있기 때문.
- 세그먼트 병합으로 시간이 지남에 따라 조각화되는 데이터 파일 문제를 피할 수 있음.
- append-only가 아니라 update도 되고 delete도 된다면, 세그먼트를 오래 썼을 때 듬성듬성 구멍이 생길 수 있음.
실제 구현
- 파일 형식
- 바이트 문자열 길이를 인코딩하고, raw string을 쓰는 쪽이 빠르고 심플하다.
- 레코드 삭제
- delete 할 때, 해당 데이터에 tombstone을 추가한다.
- 세그먼트를 병합할 때, tombstone이 있는 데이터는 무시하면 된다.
- 고장(Crash) 복구
- DB를 재시작하면 인메모리 해시 맵이 손실된다.
- 전체 세그먼트 파일을 다 읽어서, 인메모리 세그먼트 해시 맵을 다시 만들어야 한다.
- 세그먼트 해시 맵의 스냅샷을 디스크에 저장해 두면 세그먼트별 복구 속도를 높일 수 있다.
- 일부만 씌어진 레코드(Partially written records)
- 레코드를 기록하다 DB가 죽었다면?
- 체크섬을 포함하여 로그의 손상된 부분을 찾아내 무시할 수 있다.
- 동시성 제어
- 하나의 읽기 쓰레드만 사용한다.
- 데이터 파일 세그먼트는 append-only 이고 immutable 이므로, 여러 쓰레드로 동시에 읽기를 할 수 있다.
해시 색인의 문제점
- 키가 너무 많으면 곤란.
- range query에 비효율적이다.
SS 테이블과 LSM 트리
Sorted String Table
- 세그먼트 파일의 형식에서, key 값을 정렬한 것.
- 이미 정렬된 상태이므로, 메모리에 모든 키의 색인을 유지할 필요가 없음.
- 메모리에는 일부 키의 오프셋만 알려주는 색인만 있으면 된다.
정렬된 구조를 유지하기
- red-black tree나 AVL 트리 같은 트리 데이터 구조를 사용한다.
- 쓰기 요청이 들어오면 인메모리 균형 트리(balanced tree) 데이터 구조에 추가한다. 이 인메모리 트리는 memtable이라고도 부른다.
- memtable이 너무 커지면 SS 테이블 파일로 디스크에 기록한다.
- memtable은 이미 정렬되어 있으므로, SS 테이블을 파일로 기록은 효율적이다.
- 새로 만든 SS 테이블 파일은 DB의 최신 세그먼트가 된다.
- SS 테이블을 기록하는 동안 들어온 쓰기 요청은 새로운 멤테이블 인스턴스에 기록한다.
- memtable이 너무 커지면 SS 테이블 파일로 디스크에 기록한다.
- 읽기 요청이 들어오면 먼저 memtable에서 키를 찾는다.
- 그 다음, 디스크 상의 가장 최신 세그먼트에서 찾는다.
- 그 다음, 디스크 상의 두 번째 오래된 세그먼트에서 찾는다.
- 그 다음, 디스크 상의 세 번째 오래된 세그먼트에서 찾는다.
- 그 다음, 디스크 상의 n 번째 오래된 세그먼트에서 찾는다…
- 세그먼트 병합과 컴팩션은 백그라운드에서 수행한다.
- 디스크로 기록되지 않은 memtable 손실 방지를 위해 분리된 로그를 디스크에 유지한다.
SS 테이블에서 LSM 트리 만들기
- LSM 트리
- 로그 구조화 병합 트리 Log-Structured Merge-Tree.
- 정렬된 파일 병합과 컴팩션 원리를 기반으로 하는 저장소 엔진을 LSM 저장소 엔진이라 부른다.
- LSM 트리의 기본 개념: 백그라운드에서 연쇄적으로 SS 테이블을 지속적으로 병합.
B 트리
LSM 같은 로그 구조화 색인이 보편화되고는 있으나 가장 일반적인 색인 유형은 아님.
- 가장 널리 사용되는 색인 구조는 B-tree.
- 거의 대부분의 RDB에서 표준 색인 구현으로 B 트리를 사용.
- 많은 비관계형 DB에서도 B 트리를 사용.
- B 트리는 정렬된 key-value 쌍을 유지하는 방식.
- key 검색과 범위 검색에 효율적.
- 그러나 LSM 과는 설계 철학이 다르다.
B 트리
- 고정 크기 블록 배열
- 각 페이지는 주소나 위치를 이용해 식별 가능.
- 하나의 페이지가 다른 페이지를 참조할 수 있음.
- B 트리의 루트 역할로 한 페이지가 지정된다.
- 루트부터 검색 시작.
B 트리는 이미지로 보면 한 눈에 이해간다.
- 검색
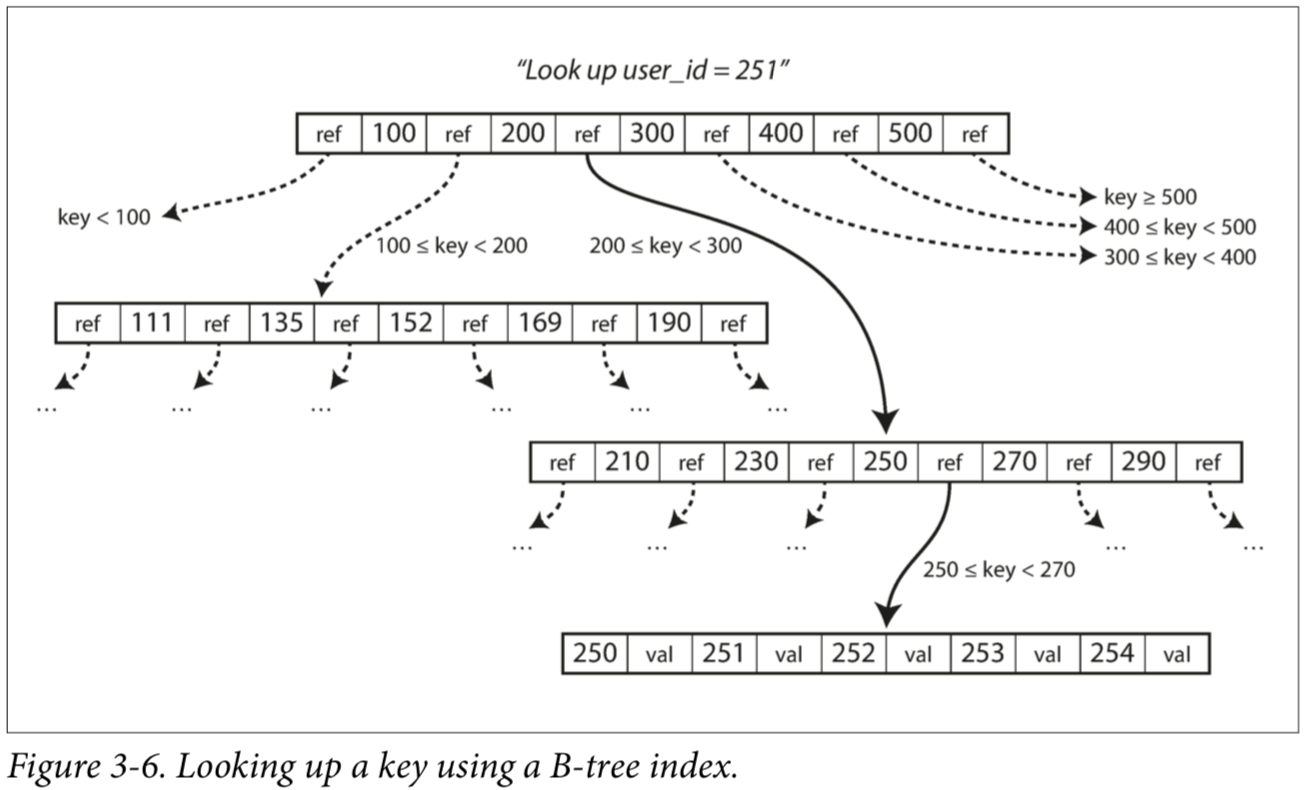
- 쓰기
B 트리에 존재하는 키 값 갱신
- 키를 포함하고 있는 리프 페이지를 검색한다.
- 페이지의 값을 바꾼다.
- 페이지를 디스크에 기록한다.
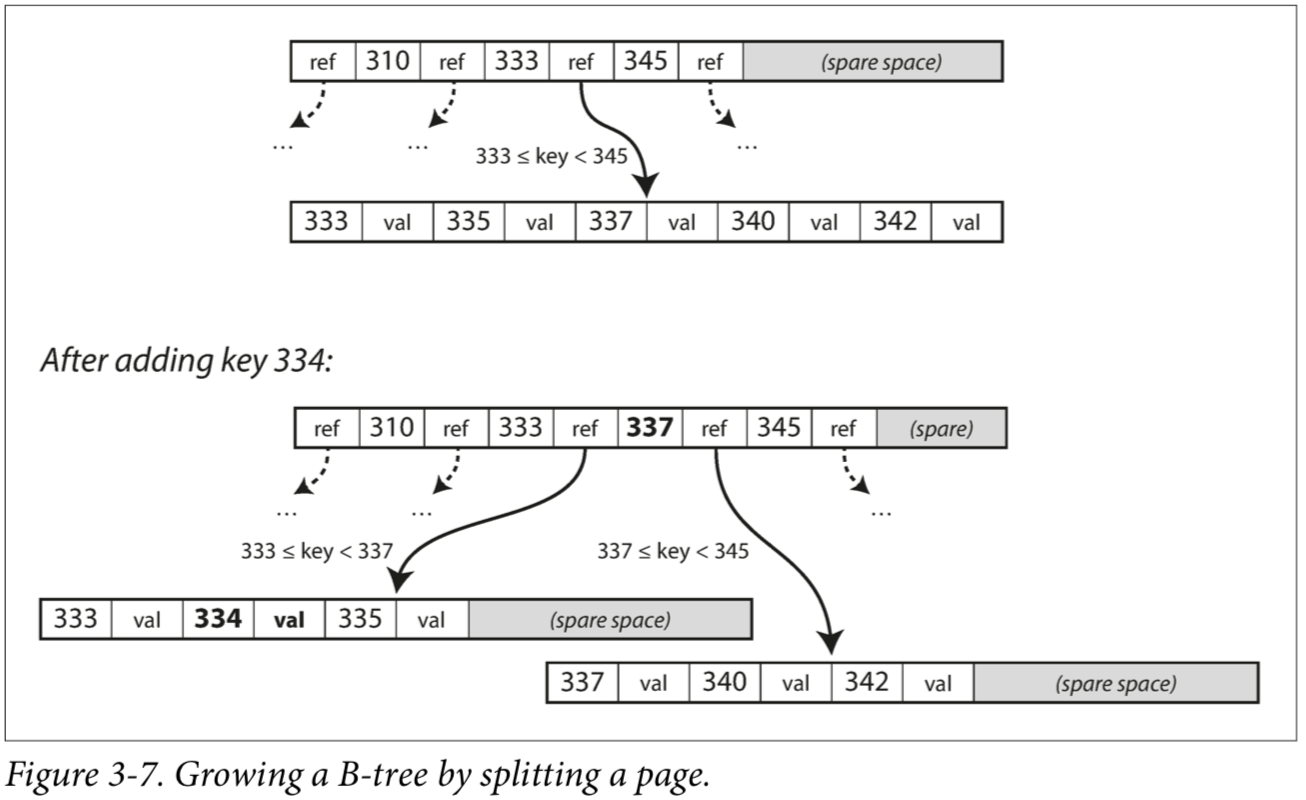
B 트리에 새로운 키를 추가하기
- 새로운 키를 포함하는 범위의 페이지를 찾는다.
- 해당 범위의 페이지에 키와 값을 추가한다.
- 페이지에 공간이 부족하다면, 페이지를 절반으로 쪼개고, 상위 페이지의 링크를 갱신한다.
- 위의 알고리즘은 트리가 계속 균형을 유지하는 것을 보장한다.
n개의 키를 가진 B 트리는 깊이가 항상O(log n)이다.
기타 색인 구조
- 보조 색인
- 색인의 각 값에 일치하는 로우 식별자 목록을 만드는 방법.
- 로우 식별자를 추가해 각 키를 고유하게 만드는 방법.
- 색인 안에 색인된 로우를 저장
- 클러스터드 색인(clustered index)
- MySQL InnoDB의 경우, 테이블의 기본키가 언제나 클러스터드 색인.
- MS의 SQL Server에서는 테이블당 하나의 클러스터드 색인을 지정 가능.
- 색인 안에 테이블의 칼럼 일부를 저장
- 커버링 색인(covering index), 포괄열이 있는 색인(index with included column)이라 부름.
- 어떤 질의는 색인만으로 응답이 가능("색인이 질의를 cover 했다(the index is said to cover the query)")
- 다중 칼럼 색인(multi column index)
- 지금까지 설명한 색인은 하나의 키 값에 대한 것들.
- 결합 색인(concatenated index)
- 하나의 키에 여러 필드를 결합하여 키를 만든다.
- 필드가 연결되는 순서는 색인 정의로 명시.
- 다차원 색인(Multi-dimensional indexes)
- 한 번에 여러 칼럼에 질의한다.
- 특히 지리 공간 데이터에서 중요하게 사용.
- R 트리 같은 공간 색인에 특화(specialized spatial index)된 알고리즘을 사용.
트랜잭션 처리나 분석?
- 온라인 트랜잭션 처리(OnLine Transaction Processing, OLTP)
- 온라인 분석 처리(OnLine Analytic Processing, OLAP)
| 특성 | 트랜잭션 처리 시스템(OLTP) | 분석 시스템(OLAP) |
|---|---|---|
| 주요 읽기 패턴 | 질의당 적은 수의 레코드, 키 기준으로 가져옴 | 많은 레코드에 대한 집계 |
| 주요 쓰기 패턴 | 임의 접근, 사용자 입력을 낮은 지연 시간으로 기록 | 대규모 불러오기, 이벤트 스트림 |
| 주요 사용처 | 웹 애플리케이션을 통한 최종 사용자 | 의사결정 지원을 위한 내부 분석가 |
| 데이터 표현 | 데이터의 최신 상태 | 시간이 지나며 일어난 이벤트 이력 |
| 데이터셋 크기 | 기가바이트에서 테라바이트 | 테라바이트에서 페타바이트 |
| 사업 운영에 중요 | ||
| 높은 가용성, 낮은 지연 시간의 트랜잭션 처리 기대 | ||
| 병목 | 디스크 탐색 | 디스크 대역폭 |
데이터 웨어하우징
- data warehouse
- OLTP 작업/운영에 영향을 주지 않고, 분석가들이 마음껏 질의할 수 있는 개별 DB.
- OLTP DB의 읽기 전용 복사본.
- 분석 방법에 따라 최적화.
분석용 스키마
- 별 모양 스키마(star schema)
- 눈꽃송이 모양 스키마(snowflake schema)
칼럼 지향 저장소
칼럼 지향 저장소의 기본 개념
- 모든 값을 하나의 로우에 저장하지 않는 대신
- 각 칼럼별로 모든 값을 함께 저장한다. (date 칼럼은 순서를 지켜 모든 row의 모든 date만 저장하는 식)
- 각 칼럼을 개별 파일에 저장하면 질의에 사용되는 칼럼만 읽고 구분 분석하면 된다.
Links
- [[Designing-Data-Intensive-Applications]]