IP
Internet Protocol
개요
IP 같은 네트워크 계층 프로토콜의 목적은 각 로컬 네트워크를 연결하여 더 큰 네트워크를 만드는 것이다.
IP는 [[/network/osi-model]]의 3 계층 프로토콜에 해당된다.
- 즉, IP는 TCP/IP 스택의 4계층인 TCP, UDP에 서비스를 제공한다.
- IP는 TCP, UDP가 포장한 데이터를 받아서 나름의 조작을 거친 다음 전송한다.
IP의 특징과 기능
- IP는 네트워크를 위한 주소지정 방법을 정의한다.
- IP는 데이터를 보내기는 하지만 데이터가 목적지에 도착하는 것은 보장하지 않는다.
- 데이터를 받았을 때, 데이터를 보낸 장비에게 잘 받았다는 응답을 하지 않음.
- 연결, 에러 검사, 전송 보장 같은 기능은 전송 계층(4계층; TCP, UDP)에서 담당한다.
- IP는 전송 계층 프로토콜(TCP, UDP)로부터 데이터를 받아 IP 데이터그램으로 캡슐화한다.
- IP는 비연결형 프로토콜이다.
- 연결을 수립한 다음 데이터를 보내는 것이 아니라 데이터그램을 만들면 곧바로 전송한다.
- IP는 데이터그램을 조각으로 단편화하여 전송한다.
- 전송받은 장비는 IP의 재조합 기능을 사용해 단편화된 데이터그램을 다시 합친다.
- 중간 장비(라우터)를 통해 데이터그램을 목적지로 보낸다.
- 이를 위해 인터넷 제어 메시지 프로토콜(ICMP, Internet Control Message Protocol), TCP/IP 게이트웨이/라우팅 프로토콜, 경계 경로 프로토콜(BGP, Border Gateway Protocol) 등을 사용한다.
역사
TCP/IP 완벽 가이드 15장에서 IP의 역사에 대해 다음과 같이 소개한다.
IP의 개발 과정에서 주목할만한 사실은 IP의 기능이 원래 TCP에 속해 있었다는 것이다. 공식 프로토콜로서 IP는 근대 인터넷의 전임자로 1970년대에 개발된 초창기 TCP가 4계층 TCP와 3계층 IP로 분리되면서 탄생했다. IP의 개발과정에서 획기적인 사건은 1981년 9월에 RFC 791 "인터넷 프로토콜" 문서가 발표된 것이었다. 그 전 해에 나왔던 RFC 760을 개선한 이 표준은 지난 20년간 널리 쓰였던 IP 버전의 핵심 기능과 특성을 정의했다.
IP Address
IP 주소는 인터네트워크에서의 네트워크 계층(3계층) 데이터 전달에 쓰인다.
- 각각의 네트워크 인터페이스는 하나의 IP 주소를 필요로 한다.
- 즉, 어떤 장비가 인터네트워크에 여러 인터페이스로 연결되어 있다면 그 장비는 여러 개의 IP 주소를 갖는다.
IP 주소 길이
- IPv4의 IP 주소는 32비트 이진수.
- \(2^{32} = 4,294,967,296\).
- IPv6의 IP 주소는 128비트 이진수.
- \(2^{128} = 340,282,366,920,938,463,463,374,607,431,768,211,456\).
- 참고: 2계층의 [[/network/mac-address]]{MAC 주소}는 48비트 이진수.
IPv4
32비트 이진수인 IPv4 주소를 점으로 구분된 십진 형식으로 변환하는 방법
이진수 주소로는 사람이 알아보기 어려우므로 IP 주소는 주로 .으로 구분된 4개의 십진수로 변환하여 사용하곤 한다.
방법은 쉽다. 8자리씩 쪼갠 다음 각자 십진수로 변환하고 .으로 이어주면 된다.
만약 어떤 IP 주소가 1010 1100 1101 1001 0001 1111 1010 1110 이라 하자. (편의를 위해 4 자리마다 스페이스를 넣었다.)
이를 8 자리씩 쪼개고 각자 십진수로 변환하면 다음과 같다.
\[\underbrace{ 1010 \ 1100 }_{172} \\ \underbrace{ 1101 \ 1001 }_{217} \\ \underbrace{ 0001 \ 1111 }_{31} \\ \underbrace{ 1010 \ 1110 }_{174} \\\]이제 각 십진수 사이에 .을 넣고 하나로 합치면 172.217.31.174가 된다.
- 이 표기법을 Dotted Decimal Notation이라 한다.
- IP 주소 부점 10진 표기법이라고도 한다.
- 보통 IP 주소라 하면 이 형식을 떠올린다.
참고: [[/network/mac-address]]{MAC 주소}의 경우
- [[/network/mac-address]]{Mac 주소}는 48비트.
- IP 주소와는 달리 십진수가 아니라 십육진수로 표현한다.
- 그리고
.이 아니라:나-로 이어붙인다.
- 그리고
Network ID와 Host ID
- 네트워크 ID: IPv4 주소 32비트 중 왼쪽 비트들
- 호스트 ID: IPv4 주소 32비트 중 오른쪽 비트들
그렇다면 네트워크 ID와 호스트 ID의 경계는 어디인가?
그때그때 다르다.
만약 127.0.0.1의 네트워크 ID가 왼쪽 8개 비트라고 하자.
따라서 다음과 같이 생각할 수 있다.
\[\underbrace{ 0111 \ 1111 }_{네트워크 ID \\ 127 } \ \underbrace{ 0000 \ 0000 \ 0000 \ 0000 \ 0000 \ 0001 }_{호스트 ID \\ 0.0.1 }\]그러므로 네트워크 주소는 다음과 같이 된다.
- \(\color{blue}{0111 \ 1111} \ 0000 \ 0000 \ 0000 \ 0000 \ 0000 \ 0000\).
127.0.0.0
호스트 주소는 다음과 같다.
- \(0000 \ 0000 \ \color{blue}{0000 \ 0000 \ 0000 \ 0000 \ 0000 \ 0001}\).
0.0.0.1
그런데 모든 네트워크 ID가 이렇게 8개 비트 단위로 깔끔하게 나뉘는 것은 아니다.
예를 들어 227.82.157.177의 왼쪽 20비트가 네트워크 ID라 생각해 보자.
157을 의미하는 1001 1101이 양쪽으로 찢어지게 된다.
따라서 네트워크 주소는 다음과 같이 된다.
- \(\color{blue}{1110 \ 0011 \ 0101 \ 0010} \ \color{red}{1001} \ 0000 \ 0000 \ 0000\).
227.82.144.0
그리고 호스트 주소는 다음과 같다.
- \(0000 \ 0000 \ 0000 \ 0000 \ 0000 \ \color{red}{1101} \ \color{blue}{1011 \ 0001}\).
0.0.13.177
주소 지정
그렇다면 네트워크 ID가 몇 비트인지 어떻게 아는가?
주소 지정에는 크게 세 가지 방법이 있으며, 현재 표준은 클래스 비사용 주소 지정이다.
- 클래스 단위 주소 지정(Classful)
- 서브넷 사용(Subnetted)
- 클래스 비사용 주소 지정(Classless)
클래스 단위 주소 지정과 서브넷 사용 관련 정보는 이 문서에서는 생략한다.
클래스 비사용 주소 지정 방법은 "클래스 비사용 도메인 간 라우팅(CIDR, Classless Inter-Domain Routing)"을 사용한다.
CIDR: 클래스 비사용 도메인 간 라우팅
- CIDR 표기법은 슬래시 표기법이라고도 부른다.
- IP 주소 뒤에
/숫자형식으로 네트워크 ID의 비트 수를 추가하는 방법이다.
- IP 주소 뒤에
- 네트워크 ID 크기를 지정하기 편리하여 다양한 규모의 네트워크를 만들 수 있다.
예를 들어
127.0.0.0/8은 왼쪽의 8 비트가 네트워크 ID, 나머지 24 비트가 호스트 ID.192.168.0.0/16은 왼쪽의 16 비트가 네트워크 ID, 나머지 16 비트가 호스트 ID.184.13.152.0/22는 왼쪽의 22 비트가 네트워크 ID, 나머지 10 비트가 호스트 ID.
TCP/IP 완벽 가이드 20장에서는 CIDR의 등장 배경에 대해 다음과 같이 설명한다.
CIDR이 필요했던 이유는 클래스 단위 주소지정 방법에서 주소 계층 구조가 오직 2단계에 불과했기 때문이다. 즉 인터넷 할당번호 관리기관(IANA, Internet Assigned Numbers Authority)은 모든 사람에게 네트워크 ID를 나눠 줬으며 그것을 받은 사람은 호스트 ID를 부여했다(또는 서브네팅을 했다).
(중략)
ISP는 자신이 받은 블록을 세분화하여 고객에게 할당할 수 있다. 이들 고객은 소형 ISP가 되기도 하며 그 소형 ISP는 다시 다른 고객에게 주소를 분배할 수 있다. 소형 ISP는 자신의 주소 블록을 서로 다른 크기의 조각으로 나누고 고객(일부는 더 작은 ISP, 일부는 최종 사용자)에게 분배한다. 이러한 분배 횟수는 원본 주소 블록에 얼마나 많은 주소가 있었는지에 의해서만 한도가 정해진다.
분배의 예를 들어 보자.
어느 ISP가 71.94.0.0/15와 같은 주소를 갖고 있다고 하자.
- \(\color{blue}{0100 \ 0111 \ 0101 \ 111}0 \ 0000 \ 0000 \ 0000 \ 0000\).
이 주소 하에서는 두 개의 서브 네트워크를 만들 수 있다.
- \(\color{blue}{0100 \ 0111 \ 0101 \ 111}\color{red}0 \ 0000 \ 0000 \ 0000 \ 0000\).
71.94.0.0/16
- \(\color{blue}{0100 \ 0111 \ 0101 \ 111}\color{red}1 \ 0000 \ 0000 \ 0000 \ 0000\).
71.95.0.0/16
15가 16이 되었다는 점에 주목하자.
똑같은 방법으로 계속 하위 조직에 주소를 분할해 나누어 줄 수 있다.
한편 '유닉스·리눅스 시스템 관리 핸드북'에서는 CIDR이 임시적인 해결책이었다는 것을 이야기한다.
주소를 직접 확장하는 서브넷팅과 마찬가지로 CIDRClassless Inter-Domain Routing은 명시적인 넷마스크에 의존해 주소의 네트워크와 호스트 경계를 정의한다. 하지만 서브넷팅과는 달리 CIDR에서는 네트워크 부분을 주소에 내재된 클래스가 의미하는 것보다 더 작게 만들 수 있다. 짧은 CIDR 마스크는 라우팅 목적으로 여러 개의 네트워크를 응집하는 효과를 낼 수 있다.
CIDR은 라우팅 정보를 단순화하며 라우팅 과정에 계층 구조를 부여한다. CIDR은 IPv6로 가는 과정에서 임시적인 해결책으로 만든 것임에도 20년 이상 인터넷 증가 문제를 다룰 수 있을 만큼 충분히 강력하다는 것이 입증됐다. 1
IPv4 주소공간
IPv4의 IP 주소 최소값은 0.0.0.0 이고, 최대값은 255.255.255.255이다.
- 이론적으로는 \(2^{32} = 4,294,967,296\)개의 주소가 존재할 수 있다.
- 주소 공간이 42억 개가 넘어가니 꽤 큰 편인데도, 예약된 주소 공간이 많아서 모든 주소를 사용할 수 없다.
- 예:
127로 시작하는 주소(\(2^{24} = 16,777,216\)개)는 loopback 주소로 예약되어 있음.
- 예:
다음은 RFC 3330(Special-Use IPv4 Addresses)을 참고하여 인용한 것이다.
| Address Block | Present Use | Reference |
|---|---|---|
| 0.0.0.0/8 | "This" Network | [RFC1700, page 4] |
| 10.0.0.0/8 | Private-Use Networks | [RFC1918] |
| 14.0.0.0/8 | Public-Data Networks | [RFC1700, page 181] |
| 24.0.0.0/8 | Cable Television Networks | – |
| 39.0.0.0/8 | Reserved but subject to allocation | [RFC1797] |
| 127.0.0.0/8 | Loopback | [RFC1700, page 5] |
| 128.0.0.0/16 | Reserved but subject to allocation | – |
| 169.254.0.0/16 | Link Local | – |
| 172.16.0.0/12 | Private-Use Networks | [RFC1918] |
| 191.255.0.0/16 | Reserved but subject to allocation | – |
| 192.0.0.0/24 | Reserved but subject to allocation | – |
| 192.0.2.0/24 | Test-Net | |
| 192.88.99.0/24 | 6to4 Relay Anycast | [RFC3068] |
| 192.168.0.0/16 | Private-Use Networks | [RFC1918] |
| 198.18.0.0/15 | Network Interconnect Device Benchmark Testing | [RFC2544] |
| 223.255.255.0/24 | Reserved but subject to allocation | – |
| 224.0.0.0/4 | Multicast | [RFC3171] |
| 240.0.0.0/4 | Reserved for Future Use | [RFC1700, page 4] |
IPv4 주소 클래스
- 역사적으로 IP 주소들은 가장 왼쪽 바이트의 값에 따라 클래스로 분류되었다.
- 클래스를 통해 어느 바이트가 네트워크 부분이고 어느 바이트가 호스트 부분인지 알 수 있다.
- 오늘날에는 클래스를 사용하지 않으며 mask를 통해 네트워크 부분과 호스트 부분을 구분한다.
- 하지만 분할이 명시적으로 지정되어 있지 않으면 전통적인 클래스를 사용한다.
클래스 A, B, C는 보통의 IP 주소들을 나타낸다. 클래스 D와 E는 멀티캐스팅과 연구용 주소들이다. 표 13.2는 각 클래스의 특성을 보여준다. 한 주소의 네트워크 부분은 N, 호스트 부분은 H로 표기했다.
표 13.2 역사적인 IPv4 주소 클래스
클래스 첫 바이트 형식 설명 A 1-127 N.H.H.H 초창기 네트워크나 DoD 용으로 확보된 주소다. B 128-191 N.N.H.H 대형 사이트용으로 보통은 서브넷을 가지며 얻기 힘들다. C 192-223 N.N.N.H 얻기 쉬우며 종종 세트로 구한다. D 224-239 ? 멀티캐스트 주소로서 영구 배정은 아니다. E 240-255 ? 실험용 주소들이다.
단 한 개의 물리적 네트워크에 수천 개의 컴퓨터가 연결돼 있는 것은 흔치 않은 일이다. 따라서 (네트워크당 각각 16,777,214개, 65,534개의 호스트를 갖는) 클래스 A와 클래스 B 주소는 대단히 낭비적이다. 예를 들어 127개의 클래스 A 네트워크들은 사용 가능한 4바이트 주소 공간의 절반까지 사용한다. IPv4 주소 공간이 이렇게 귀하게 될 것이라 생각한 사람은 없었을 것이다. 2
127
주소의 첫 바이트가 127일 때는 단 하나의 호스트를 가질 뿐 어떤 실제 하드웨어 인터페이스를 갖지 않는 가상적인 네트워크, 즉 '루프백 네트워크loopback network'를 의미한다. 루프백 주소 127.0.0.1은 항상 현재 호스트를 가리킨다. 부호명은 'localhost'다(이것은 모든 호스트가 127.0.0.1을 다른 컴퓨터라고 생각하기 때문에 IP 주소 고유성에 있어 또 하나의 작은 위반이다). 3
IPv4 특별한 주소 패턴
주소가 0으로만 되어 있거나 1로만 되어 있으면 This, 또는 All의 의미를 갖게 된다.
- 모두 0: This.
- 모두 1: All.
| 네트워크 ID | 호스트 ID | IP 주소 예 | 설명 |
|---|---|---|---|
| 모두 0 | 모두 0 | 0.0.0.0 |
자신, 이(This) 호스트, 기본 호스트 |
| 모두 0 | 어떤 값 | 0.91.215.5 |
네트워크 ID를 모르거나 표현할 필요가 없는 경우 |
| 어떤 값 | 모두 0 | 77.0.0.0 |
해당 조직의 전체 네트워크 자체(This) |
| 어떤 값 | 모두 1 | 77.255.255.255 |
해당 네트워크의 모든(All) 호스트(브로드캐스팅할 때 사용) |
| 모두 1 | 모두 1 | 255.255.255.255 |
전역 인터넷의 모든(All) 호스트 |
IPv6
IPv6 주소 표기법
RFC5952는 표기 단순화를 필수적인 의무 사항으로 만들고자 [RFC4921][RFC4921]을 업데이트한 것이다. 또한 모든 주소가 오직 하나의 텍스트 표현을 갖는다는 것을 보장하고자 다음과 같은 몇 가지 규칙을 추가했다.
- 16진수
a-f는 반드시 소문자로 표현해야 한다.::항목은 한 개의 16비트 그룹을 대체할 수 없다(단일 16비트 그룹의 표현은:0:을 사용한다).::으로 대체할 그룹을 선택할 수 있는 상황이라면::은 가장 길이가 긴0시퀀스를 대체해야 한다.현실 세계에서는 여전히 RFC5952에 따르지 않는 주소들을 보게 될 것이며 거의 모든 네트워킹 소프트웨어도 그것을 받아들인다. 하지만 여러분의 환경설정, 기록 관리, 소프트웨어에서는 RFC5952에 따를 것을 강력히 권장한다. 4
IPv4처럼 십진수로 IP 주소를 표현하기에 IPv6는 너무 길다는 문제가 있다.
따라서 IPv6는 :로 구분한 16진수로 주소를 표기한다.
예를 들어 다음과 같은 IPv6 주소가 있다고 하자. 편의상 4 비트마다 스페이스를 넣어 주었다.
1000 0000 0101 1011 0010 1101 1001 1101 1101 1100 0010 1000 0000 0000 0000 0000 0000 0000 0000 0000 1111 1100 0101 0111 1101 0100 1100 1000 0001 1111 1111 1111
이를 16자리씩 쪼갠 다음 각자 16진수로 변환하고 :으로 이어주면 된다.
즉 805b:2d9d:dc28:0000:0000:fc57:d4c8:1fff가 된다.
그리고 이를 짧게 표현하기 위해 0000을 0으로 줄여 표현하기도 한다.
805b:2d9d:dc28:0:0:fc57:d4c8:1fff
그래도 꽤 길기 때문에 :0:0:과 같이 0이 연속되는 것을 그냥 ::으로 줄이기도 한다.
805b:2d9d:dc28::fc57:d4c8:1fff
이 방식은 "0 압축(Zero Compression)"이라 부르는데, :0:0:을 ::으로 줄이는 것이 아니라 연속된 :0:0...을 ::로 만드는 방법이다.
예를 들어 ff00:4501:0:0:0:0:0:32를 0 압축하면 ff00:4501::32가 된다.
0:0:0:0:0:0:0:1은? ::1 이 된다.
0:0:0:0:0:0:0:0은? :: 이 된다.
그런데 ::만 쓰면 주소인지 아닌지 헷갈리므로 0::0으로 쓰는 방법도 있다.
한편, IPv6는 IPv4 주소를 내장하는 것이 가능하다.
마지막 32비트를 사용해 IPv4 주소를 표현할 수 있으며, 이를 위해서 익숙한 IPv4의 십진 표기법을 사용한다.
가령 다음의 IPv6 주소를
805b:2d9d:dc28::fc57:d4c8:1fff
다음과 같이 표현할 수 있는 것이다.
805b:2d9d:dc28::fc57:212.200.31.255
이 방법을 쓰면 0:0:0:0:0:0:192.168.0.1 같이 앞쪽에 0이 이어진 IPv6 주소를 ::192.168.0.1처럼 IPv4와 비슷한 모양으로 표현할 수 있다.
IPv6의 Network ID 길이
IPv6에도 IPv4처럼 네트워크 ID와 호스트 ID가 있다.
그리고 네트워크 ID 길이 지정은 IPv4의 CIDR과 똑같은 방법을 사용한다.
즉 /숫자를 주소 뒤에 붙여 네트워크 아이디의 비트 수를 표현한다.
예를 들면 다음과 같다.
805b:2d9d:dc28:0000:0000:fc57:d4c8:1fff/48
IPv6 특별한 주소 패턴
Reserved
- 미래의 목적을 위해 예약해 둔 공간.
0000 0000으로 시작하는 모든 주소.- 호환성을 위한 IPv4 주소 내장도 여기에 포함된다.
Private
- 이 주소는 특정 조직의 네트워크 바깥으로 나가지 않는다.
1111 1110 1로 시작하는 모든 주소.
Loopback
- IPv6의 루프백은
::1하나 뿐이다.
Unspecified
0:0:0:0:0:0:0:0. 즉::.- IPv4에서는 주소 값이 모두
0이면 This(자기 자신)의 의미를 갖고 있었다. - IPv6에서도 이 개념을 이어받았다. 대신 Unspecified(미지정) 주소라 부른다.
IPv6의 IPv4 주소 내장
IPv4 주소 내장은 두 가지로 나뉜다.
IPv6와 IPv4를 같이 쓰는 장비를 위한 주소
- 96개의 0 이 이어지고, 그 뒤는 32비트의 IPv4 주소.
- 즉 오른쪽 32 비트가 IPv4 주소를 표현하며, 앞은 모두 0.
예: 0:0:0:0:0:0:127.0.0.1, ::127.0.0.1
IPv4 만을 지원하는 장비를 위한 주소
- 80개의 0이 이어지고, 16개의 1이 이어진 다음, 그 뒤는 32비트의 IPv4 주소.
예: 0:0:0:0:ffff:127.0.0.1, ::ffff:127.0.0.1
IP 주소의 중복 방지는 어떻게?
- 주소가 중복으로 할당되지 않도록 통제하는 중앙 관리 기관이 필요하다.
- 중앙 기관에서 각 집단에 주소를 블록(범위)으로 나누어 주는 방식.
IP 주소 할당 중앙 기관
다음은 TCP/IP 완벽 가이드 16장에서 인용한 것이다.
인터넷도 거대한 IP 인터네트워크이기 때문에 전 세계적으로 수백만 개가 넘는 기관을 위해 이러한 조정 작업을 하는 기관이 필요하다. 인터넷의 IP 주소 할당 관리 작업은 원래 인터넷 할당 번호 관리기관(IANA, Internet Assigned Number Authority)에서 담당했다. IANA는 IP 주소 할당과 기타 중요 조정 작업(TCP/IP 프로토콜의 인자를 관리하는 등)을 수행했다. 1990년대 후반에 인터넷 이름/번호 할당 기관(ICANN, Internet Corporation for Assigned Names and Numbers)이라는 새로운 기관이 탄생했다. 이제 ICANN은 IANA의 주소 할당 임무를 감독하며 DNS 네임 등록과 같은 다른 업무도 관리한다.
IP 주소는 원래 기관에 직접 할당됐다. 초기 IP 주소지정 방법은 클래스를 이용했기 때문에 IANA는 클래스 A, B, C 블록의 주소를 할당했다. 하지만 오늘날의 주소지정은 CIDR의 계층적 주소 지정 방식을 사용하는 클래스 비사용 방법이다. 그래서 IANA는 주소를 직접 할당하지 않고 대륙별 인터넷 레지스트리(RIR, Regional Internet registries)에게 그 임무를 위임한다. 그러한 RIR에는 APNIC, ARIN, LACNIC, RIPE NCC가 있다. 각 RIR은 주소 블록을 하위 수준 레지스트리인 국가 인터넷 레지스트리(NIR, National Internet registries)와 로컬 인터넷 레지스트리(LIR, local Internet Registries)에게 다시 위임한다.
결국 ISP는 주소 블록을 할당받고 최종 사용자인 기관에게 그 주소를 분배한다. ISP의 고객 중 일부는 최종 사용 기관이지만 일부는 (더 작은) ISP이기도 하다. 이러한 ISP는 자신이 할당받은 주소를 사용하거나 다른 기관에 위임한다. 이것은 계층적으로 여러 단계에 걸쳐 일어날 수 있다. 이 방법은 IP 주소가 가장 효율적인 방법으로 할당되고 쓰이는 것을 보장한다.
IP Datagram(Packet)
- IP 데이터그램은 IP 패킷이라고도 불린다.
IP 데이터그램 캡슐화
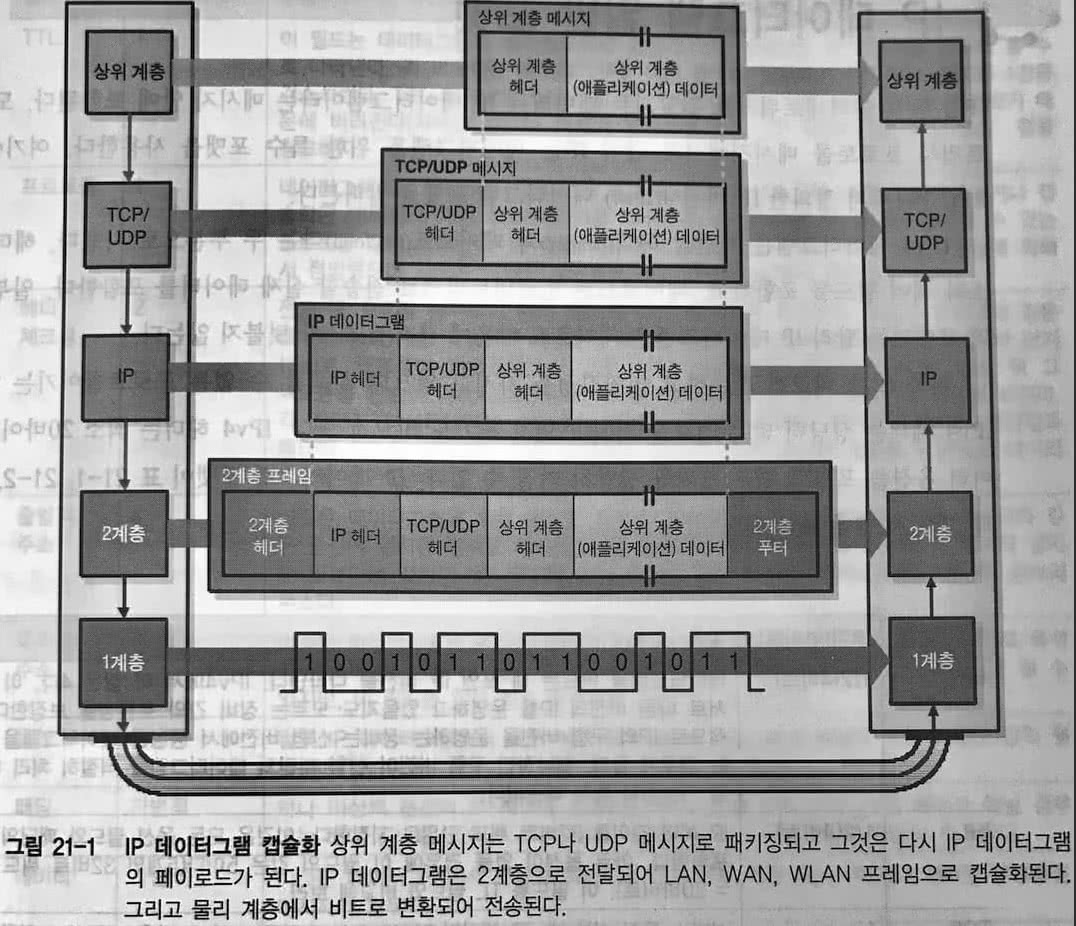
IP를 사용해 메시지를 보내려면 상위 계층 데이터를 IP 데이터그램으로 캡슐화하는 과정이 필요하다.
- 4계층: 상위 계층 메시지를 TCP/UDP 메시지로 포장.
- 3계층: TCP/UDP 메시지를 IP 데이터그램의 페이로드(본문)에 넣고 포장.
- 2계층: 데이터그램을 물리적으로 전달하는 기술에 맞는 프레임으로 포장.
- 물리적으로 전달하는 기술: LAN, WAN, WLAN 등등
- 1계층: 프레임을 비트로 전송.
IP Datagram과 데이터 링크 계층 Frame의 차이는 무엇인가?
- IP 데이트그램은 인터네트워크 상에서의 전송을 위해 설계된 것.
- 데이터 링크 계층 프레임은 물리 네트워크 내에서의 직접 전달에 쓰인다.
- 라우터에서 데이터그램을 받았다가 보낼 때 \(1 → 2 → 3 → 2 → 1\)계층을 통과하는 과정을 거친다.
- 따라서 라우터를 경유할 때마다 IP 데이터그램을 포장하는 프레임은 제거되고 IP데이터그램에 새로운 프레임이 씌워진다.
- OSI 모델의 라우팅 문서 참고.
- IP 데이터그램은 최종 목적지에 도착하기 전까지 변경되지 않는다(일부 제어 필드 제외).
IPv4 데이터그램 포맷
- 다음은 RFC 791에서 인용한 IP 데이터그램의 "헤더"이다.
- 페이로드는 생략되었으므로 좀 더 아래에 있는 데이터그램의 예제를 참고할 것.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| IHL |Type of Service| Total Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identification |Flags| Fragment Offset |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Time to Live | Protocol | Header Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Destination Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- 위의 숫자는 비트를 쉽게 세기 위한 일종의 눈금이다.
Version필드를 보면 바로 위에0 1 2 3이 있으므로 4 비트라는 것을 알 수 있다.IHL필드도4 5 6 7이 있으므로 4 비트.
다음은 RFC 791에서 인용한 데이터그램의 예제이다.
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Ver= 4 |IHL= 5 |Type of Service| Total Length = 472 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identification = 111 |Flg=0| Fragment Offset = 0 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Time = 123 | Protocol = 6 | header checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| source address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| destination address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
\ \
\ \
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
각 필드는 다음의 의미를 갖는다.
| 필드 | bit | 설명 |
|---|---|---|
| Version | 4 | IP 버전. IPv4에서 이 값은 4 이다. |
| IHL | 4 | Internet Header Length. 헤더 길이. 단위는 32bit word. 가령 이 값이 5이면 헤더의 길이는 \(5 \times 32 = 160\)bit. 즉 20byte. |
| TOS | 8 | Type of Service. 서비스 품질 기능(전송 우선 순위, 전송 방법 지정)인데 의도대로 잘 쓰이지 않아 훗날 DS로 재정의됨(RFC 2474). |
| TL | 16 | Total Length. 단위는 byte. 최대값은 \(2^{16}-1 = 65535\). 즉 데이터그램의 최대 길이는 65535 byte. |
| Identification | 16 | 수신자는 이 값을 사용해 단편화된 여러 메시지를 올바르게 재조합할 수 있다. (IP 데이터그램은 수신 순서가 보장되지 않는다.) 재조합은 오직 목적지 장비에서만 일어난다. |
| Flg | 3 | Flag. 3개의 제어 플래그. 첫번째 비트는 예비용으로 예약되어 있으며, 나머지 두 비트는 단편화 관리에 쓰인다. |
| Fragment Offset | 13 | 메시지 단편화가 일어날 때 전체 메시지 안에서 이 데이터의 위치, 또는 오프셋을 나타낸다. 단위는 64bit. |
| TTL | 8 | Time to Live. 각 라우터는 다음 홉(hop)으로 전달하기 전에 이 값을 1 감소시킨다. 0 이 되면 데이터그램은 버려지고, 최초 송신자에게 시간 초과 메시지가 전달된다. |
| Protocol | 8 | 데이터그램이 운반하는 상위 계층 프로토콜. TCP인지 UDP인지 등을 예약된 숫자로 표현한다. RFC 1700의 7 페이지 참고. |
| Header Checksum | 16 | 전송 오류를 방지하기 위한 헤더 체크섬. 체크섬이 계산값과 다르면 데이터그램은 버려진다. |
| Source Address | 32 | 출발지 IPv4 주소. 이 값은 최초로 데이터그램을 보낸 장비의 주소이다. |
| Destination Address | 32 | 목적지 IPv4 주소. 이 값은 최종 목적지의 주소이다. 임시 목적지(라우터)는 이 필드에 지정하지 않는다. |
| Options | 표준 헤더 뒤에 따로 붙일 수 있는 옵션. 길이는 정해져 있지 않다. 데이터그램이 경유한 각 라우터의 IP 주소를 목록으로 기록하거나 보안 등급 지정하는 등등의 옵션이 있다. | |
| Padding | 옵션이 붙었을 때, 헤더의 길이를 32비트의 배수로 맞추기 위해 추가하는 0bit 패딩. | |
| Data | 데이터그램에서 전송할 데이터. |
이 중 Flg에 해당하는 필드는 3개의 비트로 이루어지며 다음과 같은 의미를 갖는다.
| 필드 이름 | 위치 | 설명 |
|---|---|---|
| Reserved(예비용) | 첫번째 비트 | 아직 용도 없음. 그러므로 값은 항상 0. |
| DF(Don't Fragment) | 두번째 비트 | 1: 이 데이터그램을 단편화하지 말 것.0: 단편화해도 됨. |
| MF(More Fragments) | 세번째 비트 | 0: 이것이 메시지의 마지막 단편이다.1: 이것이 마지막 단편이 아니다. |
010: 단편화하지 않은 데이터그램. 단편이 1 개 밖에 없으므로 MF가0이다.001: 단편화한 데이터그램. 아직 더 받아야 할 단편이 있다.000: 단편화한 데이터그램. 마지막 단편.
IPv6 데이터그램 포맷
IPv6 에서는 헤더가 기본 헤더와 확장 헤더로 나뉘었다.
- 헤더
- 출발지, 목적지 등등 주요 정보를 갖는다.
- IPv4의 필드들 중 불필요한 필드는 삭제됨.
- 헤더 체크섬 필드도 삭제. 상위 계층과 데이터 링크 계층의 CRC 검사로 충분하기 때문.
- 크기는 40 바이트.
- 필수.
- 확장 헤더
- 단편화, 출발지 라우팅, 보안 등의 기능을 위한 옵션.
- 크기는 정해져 있지 않다.
- 필수 아님.
다음은 RFC 2460 3 페이지에 실려 있는 헤더 포맷이다.
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| Traffic Class | Flow Label |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Length | Next Header | Hop Limit |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Source Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Destination Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
각 필드는 다음의 의미를 갖는다.
| 필드 | 비트 | 설명 |
|---|---|---|
| Version | 4 | IP 버전. IPv6 에서 이 값은 6이다. |
| Traffic Class | 8 | IPv4 헤더의 TOS(Type of Service)필드를 대체한다. RFC 2474의 DS 방식을 사용. |
| Flow Label | 20 | 실시간 데이터그램 전달과 QoS(Quality of Service) 특성을 제공하기 위한 필드. |
| Payload Length | 16 | 페이로드의 사이즈. 단위는 바이트. 단, 확장 헤더의 사이즈도 페이로드 사이즈에 포함한다. |
| Next Header | 8 | 두 가지 용도로 쓴다. 확장 헤더가 없으면 IPv4 헤더의 프로토콜 필드를 대체한다. 확장 헤더가 있으면 첫 번째 확장 헤더 식별 용도로 사용한다. |
| Hop Limit | 8 | IPv4 헤더의 TTL(Time to Live)를 실제 사용에 맞는 이름으로 변경. |
| Source Address | 128 | 출발지 IPv6 주소. |
| Destination Address | 128 | 목적지 IPv6 주소. |
- 모든 기본/확장 헤더는 공통적으로
Next Header필드를 갖는다.- 다음으로 오는 확장 헤더와 관련된 값을 갖는다.
다음은 Next Header에 들어가는 값이다.
값에 따라 데이터그램의 프로토콜을 의미하기도 하고, 다음에 올 헤더의 타입을 명시하기도 한다.
| 값(Dec) | 프로토콜/다음 헤더 | 다음 헤더의 기능 |
|---|---|---|
| 0 | Hop 간 선택사항 확장 헤더. IPv4에서는 예약된 값. | 출발지에서 목적지까지 경로에 있는 모든 장비가 검사해야 하는 선택사항 집합. |
| 1 | ICMPv4 | |
| 2 | IGMPv4 | |
| 4 | IP 내 IP 캡슐화 | |
| 6 | TCP | |
| 8 | EGP | |
| 17 | UDP | |
| 41 | IPv6 | |
| 43 | 라우팅 확장 헤더 | 데이터그램의 전송 경로를 출발지 장비가 지정할 수 있게 한다. |
| 44 | 단편화 확장 헤더 | 데이터그램으로 원본 메시지의 단편만을 전송할 때 사용. |
| 46 | RSVP | |
| 50 | 암호화 보안 페이로드(ESP) 확장 헤더 | 보안을 위해 암호화한 데이터 사용. |
| 51 | 인증 헤더(AH) 확장 헤더 | 암호화한 데이터를 검사하기 위한 정보. |
| 58 | ICMPv6 | |
| 59 | 다음 헤더 없음 | |
| 60 | 목적지 선택사항 확장 헤더 | 데이터그램의 목적지에서만 적용되는 선택사항 집합. |
예를 들어 TCP를 전달하는 데이터그램이 있다고 하자.
| 헤더 | Next Header 값(Dec) | 의미 |
|---|---|---|
| 기본 헤더 | 0 | 다음 헤더가 있고, 그 헤더는 Hop 간 선택사항 확장 헤더이다. |
| 첫 번째 확장 헤더(Hop간 선택사항 확장 헤더) | 44 | 다음 헤더가 있고, 그 헤더는 단편화 확장 헤더이다. |
| 두 번째 확장 헤더(단편화 확장 헤더) | 6 | 이 데이터그램의 프로토콜은 TCP 이다. |
IPv4 단편화(Fragmentation)
IP 데이터그램의 사이즈가 데이터 링크 계층 프레임 포맷 페이로드 최대 사이즈보다 크면 데이터그램을 여러 개로 단편화해야 한다.
- 각 물리 네트워크는 일반적으로 고유의 프레임 포맷을 사용하며, 각 포맷은 각기 다른 데이터 사이즈 제한을 갖고 있다.
- IP 인터네트워크의 각 장비는 자신이 다른 장비와 맺는 2계층 연결의 용량(MTU)를 알아야 한다.
- MTU: Maximum Transmission Unit, Maximum Transfer Unit. 네트워크의 최대 전송 단위.
- 참고: MTU의 최소값은 576 바이트.
- MTU: Maximum Transmission Unit, Maximum Transfer Unit. 네트워크의 최대 전송 단위.
예를 들어 보자.
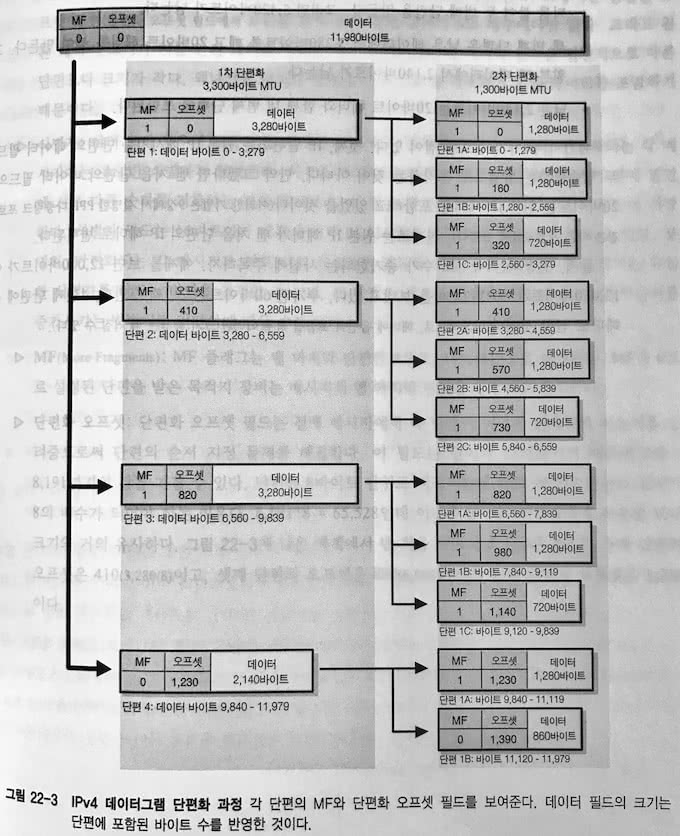
12,000 바이트의 IP 메시지를 보낼 때 장비의 MTU가 3,300 바이트라면?
- 다음과 같이 단편화된다.
- 3,300 바이트짜리 단편 3개
- 2,100 바이트짜리 단편 1개
이렇게 나뉜 단편이 전송되다가 MTU가 1,300 바이트인 두 라우터 연결을 통과하게 된다면?
- 다음과 같이 단편화된다.
- 3,300 바이트짜리 단편 → 1,300 바이트짜리 단편 2개, 700바이트짜리 단편 1개
- 2,100 바이트짜리 단편 → 1,300 바이트짜리 단편 1개, 800바이트짜리 단편 1개
따라서 1,300 바이트 MTU인 두 라우터 연결을 통과한 이후에는 다음과 같이 단편화된다.
- 1,300 바이트짜리 단편 7개
- 800 바이트짜리 단편 1개
- 700 바이트짜리 단편 3개
만약 DF 플래그가 1 이어서 단편화를 금지한 데이터그램이 MTU보다 크다면 어떻게 될까?
- 이런 경우 데이터그램은 그냥 버려지고, 목적지 접근 불가(Destination Unreachable) 메시지가 출발지 장비로 전송된다.
다음은 TCP/IP 완벽 가이드 22장의 그림을 인용한 것이다.
IPv6 단편화(Fragmentation)
단편화는 IPv6 에서 다음과 같은 변경이 있다.
| 변경된 항목 | IPv4 | IPv6 |
|---|---|---|
| MTU 최소값 | 576 바이트 | 1280 바이트(MTU가 커졌으므로 IPv4보다 단편화가 덜 발생한다) |
| Route 단편화 | 라우터가 단편화/재조합을 할 수 있었음 | 출발지 장비만 단편화 가능, 목적지 장비만 재조합 가능 |
| 헤더 단편화 | 헤더의 모든 필드가 고정 | 단편화 확장 헤더를 두고 데이터그램을 단편으로 나눌 경우에만 확장 헤더 사용 |
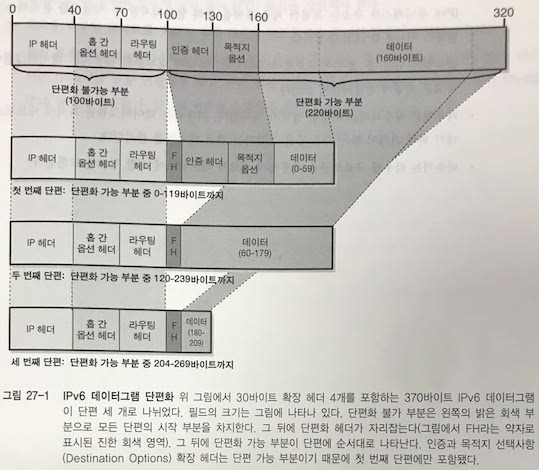
데이터그램은 단편화 불가 부분과 단편화 가능 부분으로 나뉜다.
- 단편화 불가 부분
- 모든 단편에 다 들어가야 한다.
- 기본 헤더와 몇몇 확장 헤더 등등.
- 단편화 가능 부분
- 데이터그램의 실제 데이터 부분 등등.
IPv6의 단편화 과정은 IPv4와 거의 같으며, 확장 헤더를 처리하는 과정이 다르다.
다음 이미지는 MTU가 230 바이트일 때, 320바이트의 데이터그램을 단편화하는 과정을 나타낸 것이다.
의문점들
왜 IPv1은 없고 IPv4가 IP의 첫 버전인가? 그리고 왜 IPv5는 없나?
- TCP 4 버전에서 TCP와 IP가 분리되었기 때문.
- RFC 1190: Experimental Internet Stream Protocol, Version 2 (ST-II)
- 인터넷 스트림 프로토콜 버전 2가 IPv5이다.
IPv5에 대체 무슨 일이 일어났는가?
인터넷 프로토콜 버전 4(IPv4)가 버전 6(IPv6)으로 대체됐다면 버전 5에는 무슨 일이 있었는가? 그리고 왜 IPv1부터 IPv3은 전혀 들어보지 못했을까?
IP 패킷의 첫 4개 비트는 버전을 나타낸다. 따라서 버전은 이론상 15개로 제한된다. 널리 사용되는 IPv4 이전에 0부터 3까지 4개의 실험적 버전이 있었다. 그러나 버전 4까지 이 버전 중 어떤 것도 공식적으로 표준화되지 않았다. 그 이후 버전 5는 나중에 VoIP(Voice over IP)가 된 것과 유사한 실시간 음성 및 영상 스트리밍용으로 만들어진 인터넷 스트림 프로토콜(Internet Stream Protocol) 용도로 지정됐다. 그러나 버전 5가 특히 버전 4와 동일한 주소 제한 문제를 겪었기 때문에 한 번도 널리 쓰이지 못했다. 그리고 버전 6가 나왔을 때 버전 5에 대한 개선 노력은 멈췄고 버전 6가 IPv4의 후속 버전으로 남았다. 버전 6가 이미 할당됐다는 잘못된 가정하에 그 버전이 처음에는 버전 7로 불리는 것 같았다. 버전 7, 8, 9 또한 할당됐지만 비슷한 이유로 더 이상 사용되지 않는다. IPv6의 후속 버전이 또 생긴다면 IPv10이나 그 다음이 될 것이다. 그 후속 버전은 틀림없이 이 보충 자료를 시작한 질문과 비슷한 질문을 이끌어낼 것이다.5
3계층 미만에서 작동하는 장비들도 IP를 사용하는가?
- TCP/IP 완벽 가이드 16장에서는 다음과 같이 설명한다.
리피터(repeater), 브리지(bridge), 스위치(switch) 같은 하위 수준 네트워크 연결 장비는 2계층(데이터 링크) 주소에 근거하여 트래픽을 통과시키기 때문에 IP 주소가 없어도 된다. 브리지와 스위치로 연결된 네트워크 세그먼트는 단일 브로드캐스트 도메인을 구성하기 때문에 거기에 속한 어떤 장비도 다른 장비와 라우팅 없이도 직접 데이터를 주고 받을 수 있다. IP에게 있어 브리지와 스위치는 본질적으로 없는 것, 즉 장비를 연결하는 케이블과 다를 바가 없다(몇 가지 예외는 있다). 하지만 그러한 장비도 관리 목적을 위해 선택적으로 IP 주소가 할당될 수 있다. 그 경우 브리지와 스위치는 네트워크에서 일반 호스트와 유사하게 동작한다.
단편화한 IP 데이터그램의 재조합은 왜 목적지 장비에서만 일어나는가?
- 라우터가 재조합을 하면 라우팅이 느려진다.
- 라우터가 모든 단편을 다 받을 때까지 기다려야 한다.
- 단편이 다양한 경로를 거쳐 갈 수 있기 때문에 어떤 라우터도 모든 단편을 다 모을 수 있다는 보장이 없음.
IP 주소는 고유한가?
하드웨어 바로 위의 다음 계층에서는 인터넷 주소 지정Internet Addressing(일반적으로는 IP Addressing이란 용어가 더 많이 사용됨)이 사용된다. 하나의 IP 주소는 특정한 네트워크 맥락 안에서 하나의 고유한 특정 목적지를 가리킨다. 하지만 IP 주소가 글로벌 범주에서 고유하다고 말하는 것은 정확한 얘기가 아니다. 물을 흐리게 만드는 여러 가지 특수한 경우가 있기 때문이다. 예를 들면 NAT는 한 개의 인터페이스 IP 주소를 사용해 다수의 머신을 위한 트래픽을 처리한다. 또한 IP 사설 주소 공간들은 주소가 외부 인터넷에 보여지지만 않는다면 다수의 사이트가 동시에 사용할 수 있는 주소들이다. 애니캐스트anycast 주소 지정은 하나의 IP 주소를 여러 머신이 공유한다.
IP 주소에서 하드웨어 주소로의 매핑은 TCP/IP 모델의 링크 계층에서 구현된다. 브로드캐스팅broadcasting(즉, 패킷의 목적지 주소를 '물리적 네트워크상의 모든 호스트'로 지정하는 것)을 지원하는 이더넷과 같은 네트워크에서 발송자는 시스템 관리자의 개입 없이 매핑 관계를 알아내고자 ARP 프로토콜을 사용한다. IPv6에서는 종종 인터페이스의 MAC 주소를 IP 주소의 일부로 사용함으로써 IP와 하드웨어 주소 간의 변환이 사실상 자동으로 수행되게 만들어준다. 6
함께 읽기
- [[/network/mac-address]]
참고문헌
- TCP/IP 완벽 가이드 / 찰스 M. 코지에록 저/강유, 김진혁, 민병호, 박선재 역 / 에이콘출판사 / 2007년 01월 25일 / 원제 : The TCP/IP Guide: A Comprehensive, Illustrated Internet Protocols Reference
- [POL] HTTP/2 in Action / 배리 폴라드 저/임혜연 역 / 에이콘출판사 / 발행 2020년 08월 31일 / 원서 : HTTP/2 in Action
- 유닉스·리눅스 시스템 관리 핸드북 5/e / 에비 네메스, 가스 스나이더, 트렌트 헤인, 벤 웨일리, 댄 맥킨 저 외 2명 / 에이콘출판사 / 발행: 2022년 01월 03일 / 원제: UNIX and Linux System Administration Handbook, 5th Edition
Links
- https://en.wikipedia.org/wiki/Dot-decimal_notation
- TCP/IP 주소 지정 및 서브넷 구성 기본 사항의 이해(support.microsoft.com)
- Oracle Solaris 관리: IP 서비스(docs.oracle.com)