macOS 초보를 위한 터미널 사용 가이드 - Week 02
file descriptor와 tee 사용법
- 이전 문서: [[/mac/terminal-guide/01]]
- 다음 문서: [[/mac/terminal-guide/03]]
file descriptor 0, 1, 2
이번에는 셸 명령에서 중요한 0, 1, 2 를 공부해 보도록 하겠습니다.
우리가 명령을 입력해 실행하면, 프로세스가 생성됩니다. 그리고 프로세스는 기본적으로 3개의 file descriptor를 갖습니다.
- 0 : stdin, 표준입력
- 1 : stdout, 표준출력
- 2 : stderr, 표준에러 (표준에러 출력)
예제와 그림
이해를 돕기 위해 간단한 명령 중 하나인 [[/cmd/echo]]를 실행해 봅시다.
$ echo hello
hello
이걸 그림으로 표현해보겠습니다. 공식적인 유형의 그림은 아니고 제가 좋아하는 방식으로 마음대로 표현한 그림입니다.

echo의 프로세스가 생성됐습니다.echo는 명령줄 인자로hello를 받았습니다.- 표준입력(
0)으로 받은 것은 없습니다. - 표준출력(
1)으로hello를 내보냈습니다.- 기본적으로 표준출력으로 내보내면 터미널 화면에 표시가 됩니다.
- 표준에러(
2)로는 아무것도 내보내지 않았습니다.- 실행과정에서 에러가 없었기 때문입니다.
이제 이 여기에 문자를 변환해주는 [[/cmd/tr]]를 연결해 봅시다.
다음은 [[/cmd/echo]]의 출력을 [[/cmd/tr]]로 전달하는 파이프라인 명령입니다.
$ echo hello | tr l r
herro
echo hello:hello를 출력.tr l r:echo의 출력인hello를 받아서l을r로 바꾼 결과를 출력.
이것도 그림으로 그려보겠습니다.

파이프 (|) 를 통해 echo의 출력이 tr의 입력으로 전달되는 것이 눈에 보일 것입니다.
파이프는 이전 프로세스의 표준출력(1)을 다음 프로세스의 표준입력(0)으로 연결해 주겠다고 선언하는 것입니다.
그래서 [[/cmd/tr]]{tr}은 [[/cmd/echo]]{echo}의 출력인 hello를 받아서 l을 r로 바꾼 결과인 herro를 출력하게 되었습니다.
그렇다면 이번에는 결과를 터미널 화면이 아니라 파일로 리다이렉팅 해 봅시다.
아래의 명령 파이프라인과 같이 echo | tr의 출력을 hello.txt 파일로 보내면, hello.txt 파일에는 herro가 저장될 것입니다.
$ echo hello | tr l r > hello.txt
$ cat hello.txt
herro
다음은 이 과정을 그림으로 표현한 것입니다. [[/cmd/tr]]{tr}의 표준출력(1)이 hello.txt 파일로 리다이렉팅 되는 것에 주목합시다.

Java의 System.in, System.out, System.err
이 가이드 문서를 통해 0, 1, 2 채널을 처음 알게 된 분들이 있다면, 생소하면서 신기한 느낌을 받고 있을지도 모르겠습니다.
그러나 평소 널리 알려져 있는 프로그래밍 언어를 통해 프로그래밍을 하고 있었다면 자신도 모르는 사이에 이들을 사용하고 있었을 것입니다.
예를 들어 [[/java]]의 java.lang.System 클래스를 열어보면 in, out, err이 있는데요, 이것들이 0, 1, 2 입니다.
- open jdk(jdk-23+6)의 System.in: 표준입력(
0)- 첫째줄의
The "standard" input stream.이라는 주석이 표준입력(0)을 설명하고 있습니다.
- 첫째줄의
/**
* The "standard" input stream. This stream is already
* open and ready to supply input data. Typically this stream
* corresponds to keyboard input or another input source specified by
* the host environment or user. In case this stream is wrapped
* in a {@link java.io.InputStreamReader}, {@link Console#charset()}
* should be used for the charset, or consider using
* {@link Console#reader()}.
*
* @see Console#charset()
* @see Console#reader()
*/
public static final InputStream in = null;
- open jdk(jdk-23+6)의 System.out: 표준출력(
1)- 첫째줄의
The "standard" output stream.이라는 주석이 표준출력(1)을 설명하고 있습니다. - 예를 들어
System.out.print("str")은 표준출력(1)으로str을 보내는 것입니다.
- 첫째줄의
/**
* The "standard" output stream. This stream is already
* open and ready to accept output data. Typically this stream
* corresponds to display output or another output destination
* specified by the host environment or user. The encoding used
* in the conversion from characters to bytes is equivalent to
* {@link Console#charset()} if the {@code Console} exists,
* <a href="#stdout.encoding">stdout.encoding</a> otherwise.
* <p>
* For simple stand-alone Java applications, a typical way to write
* a line of output data is:
* <blockquote><pre>
* System.out.println(data)
* </pre></blockquote>
* <p>
* See the {@code println} methods in class {@code PrintStream}.
*
* @see java.io.PrintStream#println()
* @see java.io.PrintStream#println(boolean)
* @see java.io.PrintStream#println(char)
* @see java.io.PrintStream#println(char[])
* @see java.io.PrintStream#println(double)
* @see java.io.PrintStream#println(float)
* @see java.io.PrintStream#println(int)
* @see java.io.PrintStream#println(long)
* @see java.io.PrintStream#println(java.lang.Object)
* @see java.io.PrintStream#println(java.lang.String)
* @see Console#charset()
* @see <a href="#stdout.encoding">stdout.encoding</a>
*/
public static final PrintStream out = null;
- open jdk(jdk-23+6)의 System.err
- 첫째줄의
The "standard" error output stream. This stream is already이라는 주석이 표준에러출력(2)을 설명하고 있습니다.
- 첫째줄의
/**
* The "standard" error output stream. This stream is already
* open and ready to accept output data.
* <p>
* Typically this stream corresponds to display output or another
* output destination specified by the host environment or user. By
* convention, this output stream is used to display error messages
* or other information that should come to the immediate attention
* of a user even if the principal output stream, the value of the
* variable {@code out}, has been redirected to a file or other
* destination that is typically not continuously monitored.
* The encoding used in the conversion from characters to bytes is
* equivalent to {@link Console#charset()} if the {@code Console}
* exists, <a href="#stderr.encoding">stderr.encoding</a> otherwise.
*
* @see Console#charset()
* @see <a href="#stderr.encoding">stderr.encoding</a>
*/
public static final PrintStream err = null;
/dev/fd
흥미로운 사실은 이런 0, 1, 2 가 내 컴퓨터의 하드디스크에 특수한 파일로 존재한다는 것입니다.
[[/cmd/ls#option-l]]{ls -l} 명령으로 [[/cmd/dev/fd]] 디렉토리를 조사해 보면 0, 1, 2 라는 이름의 파일을 확인할 수 있습니다. (3 이상은 운영체제나 다른 프로세스가 사용하고 있는 것이니 지금은 신경쓰지 않아도 됩니다.)
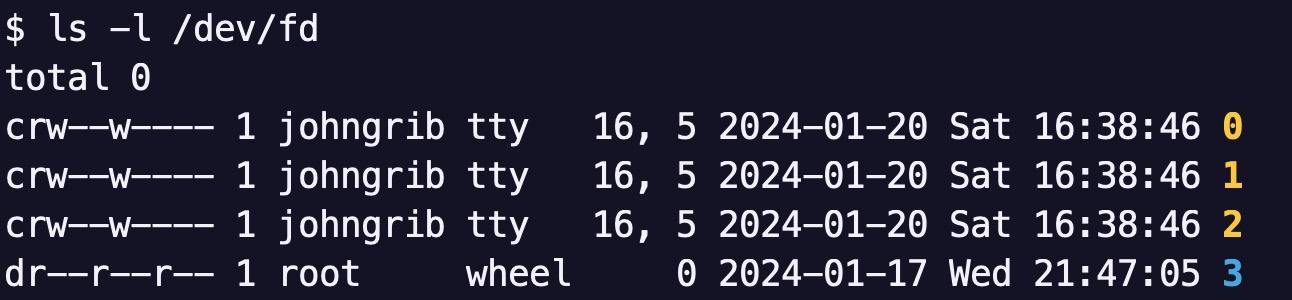
- 가장 왼쪽을 보면
c라고 되어 있는데, 이것은 바이트 문자를 처리하는 특수 디바이스를 의미합니다.- 즉 0, 1, 2 는 특수 디바이스입니다.
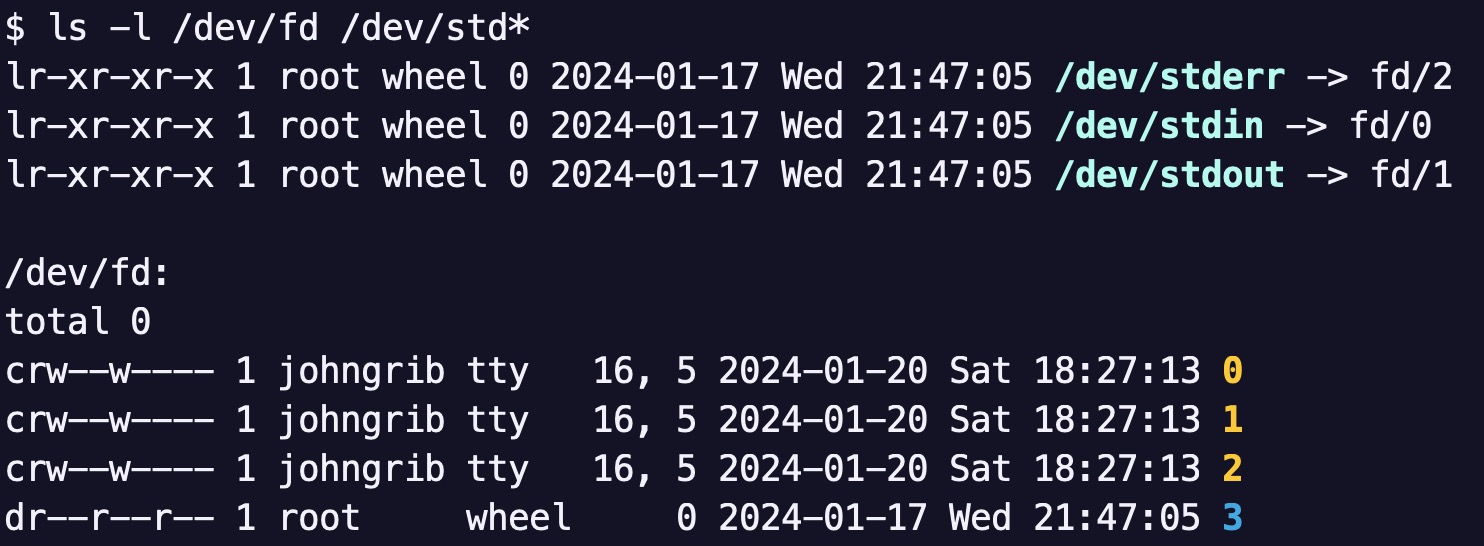
한편 0, 1, 2 가 의미하는 바가 표준입력, 표준출력, 표준에러이다 보니 이를 의미하는 이름으로 연결된 것도 있습니다.
ls -l /dev/std* 명령으로 확인해 보면 다음과 같이 확인할 수 있습니다.

0, 1, 2 가 각각 /dev/stdin, /dev/stdout, /dev/stderr 로 연결되어 있습니다.
- 가장 왼쪽의
l은 이 파일들이 심볼릭 링크라는 것을 의미합니다. - 심볼릭 링크에 대해서는 다음에 설명하고, 여기에서는 넘어가겠습니다.
출력 텍스트 스트림을 연결하기
이번에는 다음과 같이 [[/cmd/wc]]를 사용해서 3개의 파일의 줄 수를 조사해 봅시다.
참고로 asdf라는 파일은 존재하지 않는 파일인데, 에러 메시지를 확인하기 위해 일부러 집어넣었습니다.
$ wc -l ~/.bashrc asdf ~/.bash_profile
156 /Users/johngrib/.bashrc
wc: asdf: open: No such file or directory
52 /Users/johngrib/.bash_profile
208 total
- 출력 결과의 둘째 줄을 보면
No such file or directory라는 메시지가 출력되었습니다.- asdf라는 파일이 없기 때문입니다.
- 이 둘째 줄은 에러 메시지이므로, 표준에러(
2)로 출력되었을 것으로 추측할 수 있을 것입니다.
이번에 실행한 명령도 그림으로 표현해 보겠습니다.

- [[/cmd/wc]]{wc 프로세스}는
- 명령줄 인자로
-l, ~/.bashrc, asdf, ~/.bash_profile를 받았습니다. ~/.bashrc파일과~/.bash_profile파일을 읽고, 줄 수를 카운트한 결과를 표준출력(1)으로 내보냈습니다.- 디스크에서 찾지 못한 파일인
asdf에 대한 에러 메시지를 표준에러(2)로 내보냈습니다.
- 명령줄 인자로
2번 채널의 출력을 리다이렉팅하는 2>
위의 그림과 같이 잘 작동하는지 확인하기 위해 2번 채널로의 출력을 파일로 리다이렉팅해 봅시다.
$ wc -l ~/.bashrc asdf ~/.bash_profile 2> result2.txt
156 /Users/johngrib/.bashrc
52 /Users/johngrib/.bash_profile
208 total
1번 채널은 터미널 화면으로 잘 출력됐고, 2번 채널은 result2.txt 파일로 출력됐기 때문에 asdf 파일이 없다는 내용은 화면에 출력되지 않았습니다.
그리고 result2.txt 파일을 확인해 보면 에러 메시지가 잘 저장되어 있습니다.
$ cat result2.txt
wc: asdf: open: No such file or directory
1번 채널의 출력을 리다이렉팅하는 >
이번에는 1번 채널도 파일로 리다이렉팅해 봅시다.
$ wc -l ~/.bashrc asdf ~/.bash_profile > result1.txt 2> result2.txt
두 출력이 모두 파일로 리다이렉팅됐기 때문에 화면에는 아무것도 출력되지 않았습니다.
명령이 이제 조금씩 길어지기 시작했습니다.
명령을 여러 줄로 표현하려면 \를 사용하면 됩니다.
wc -l ~/.bashrc asdf ~/.bash_profile \
> result1.txt \
2> result2.txt
이제 result1.txt 파일과 result2.txt 파일을 확인해 봅시다.
$ cat result1.txt
156 /Users/johngrib/.bashrc
52 /Users/johngrib/.bash_profile
208 total
$ cat result2.txt
wc: asdf: No such file or directory
2번 채널의 출력을 1번 채널로 리다이렉팅하는 2>&1
두 채널의 출력을 하나로 모아보는 것이 필요한 경우도 있습니다.
2>&1 을 사용하면 2번 채널의 출력을 1번 채널로 리다이렉팅할 수 있습니다(단, 2>&1을 쓸 때 띄어쓰기를 하면 안됩니다).
$ wc -l ~/.bashrc asdf ~/.bash_profile 2>&1
156 /Users/johngrib/.bashrc
wc: asdf: open: No such file or directory
52 /Users/johngrib/.bash_profile
208 total
2>&1을 실행한 결과를 보면 2>&1을 쓰지 않았을 때와 똑같아 보입니다.
그러나 실제로는 차이가 좀 있습니다.
그림으로 그려보겠습니다.

이런 식으로 파이프라인을 구성했을 때 1번 채널을 파일로 리다이렉팅해주면 하나의 파일에 표준출력과 표준에러를 모두 저장할 수 있습니다.
# 2번 채널을 1번 채널로 리다이렉팅하고, 1번 채널을 파일로 리다이렉팅
wc -l ~/.bashrc asdf ~/.bash_profile > result.txt 2>&1
# 이렇게 해도 됩니다
# ↓ 띄어쓰기 없이 쓰면 덜 헷갈립니다
wc -l ~/.bashrc asdf ~/.bash_profile >result.txt 2>&1
# 이렇게 해도 됩니다
# ↓ > 대신 1> 을 써도 됩니다
wc -l ~/.bashrc asdf ~/.bash_profile 1>result.txt 2>&1
결과는 예상한 대로 파일 하나에 모든 출력이 모여 있습니다.
$ cat result.txt
wc: asdf: open: No such file or directory
156 /Users/johngrib/.bashrc
52 /Users/johngrib/.bash_profile
208 total
흔한 패턴: 2>/dev/null
짧고 간단한 명령 파이프라인을 구성해 실행할 때에는 에러 메시지가 화면에 출력되어도 크게 문제가 되지 않습니다. 오히려 에러 메시지 덕분에 문제 상황을 빨리 파악할 수 있기 때문에 에러 메시지를 화면에 출력하는 것이 좋습니다.
그러나 길고 복잡한 셸 스크립트 파일을 작성하거나 몇몇 중요하지 않은 에러 메시지가 반복적으로 출력되는 경우에 의도적으로 에러 메시지를 숨겨야 할 수도 있습니다.
이런 경우에 생각하기 쉬운 방법은 2번 채널을 특정한 로그 파일로 리다이렉팅하는 것일 겁니다.
wc -l ~/.bashrc asdf ~/.bash_profile 2> error.log
이러면 에러 메시지가 error.log 파일에 저장되기 때문에 화면에는 에러 메시지가 출력되지 않으며, 나중에 error.log 파일을 확인해 보는 것으로 에러 메시지를 확인할 수 있습니다.
그런데 만약 에러 로그를 아예 확인할 필요가 없고, 파일을 생성할 필요도 없는 경우라면 2번 출력을 "null 장치"로 리다이렉팅하는 것이 일반적입니다.
$ wc -l ~/.bashrc asdf ~/.bash_profile 2>/dev/null
156 /Users/johngrib/.bashrc
52 /Users/johngrib/.bash_profile
208 total
드디어 /dev/null이 등장했습니다.
/dev/null은 null device라는 가상의 장치로, 입력되는 모든 값을 그냥 버리기만 합니다.
이야기가 나온 김에 매뉴얼도 읽어봅시다. (/dev/null의 man 페이지를 보려면 4번 섹션을 지정해 줘야 합니다.)
man 4 null
/dev 디렉토리에 대하여
/dev/fd와 /dev/null이 들어있는 /dev 디렉토리는 장치 파일을 모아둔 곳입니다.
/dev는 device를 의미합니다(develop이 아닙니다).
/dev에는 file descriptor도 있고…
터미널 디바이스([[/cmd/tty]]{tty}: teletype 시절의 레거시가 아직 이 이름으로 남아있습니다)도 있고…
디스크도 있습니다.
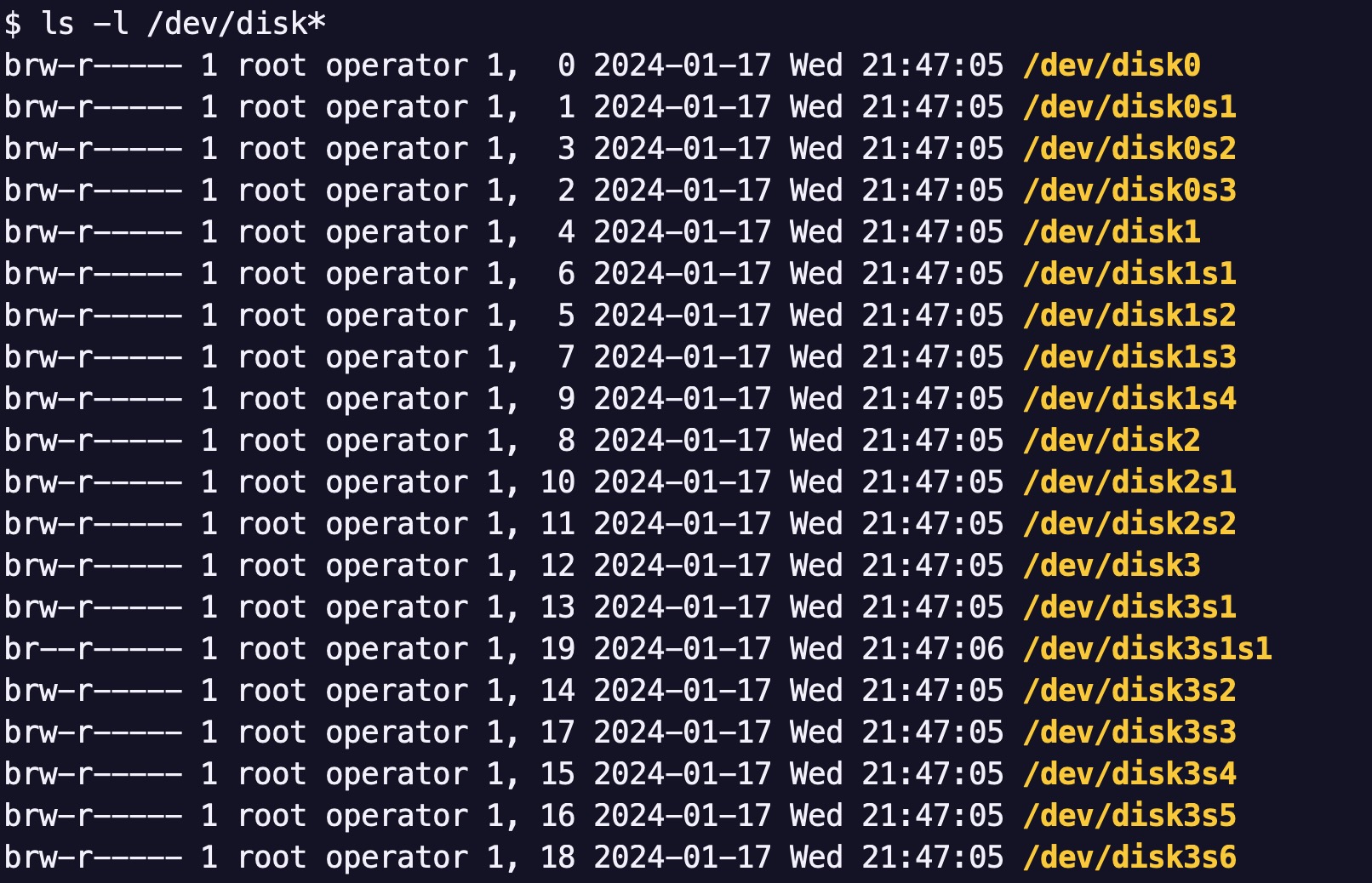
USB 메모리 스틱을 macOS 컴퓨터에 연결하면 디스크 장치 파일이 이 목록에 추가되니 한번 확인해 보세요.
tee 사용법
[[/cmd/tee]]는 자신의 0번 채널로 들어오는 입력을 1번 채널로 '그대로' 출력하면서, 동시에 명령줄 인자로 받은 파일로도 출력해줍니다.
[[/cmd/tee]]의 이름은 T자 모양의 연결파이프에서 유래했습니다.

이제 [[/cmd/tee]]를 사용해 봅시다.
[[/mac/terminal-guide/00#one-line-rsp]]{Week 00의 한줄짜리 가위바위보}에서 사용했던 명령을 다시 살펴봅시다.
printf "가위\n바위\n보\n" \
| sort -R \
| tail -1
이 명령 파이프라인을 실행하면 랜덤하게 가위바위보 중 하나가 출력됩니다.
그런데 이 명령의 중간 지점에서 생성되는 '랜덤 정렬된 결과'가 궁금하다면 어떻게 해야 할까요?
이럴 때 [[/cmd/tee]]를 사용하면 됩니다.
$ printf "가위\n바위\n보\n" | sort -R | tee sort-result.txt | tail -1
보
$ cat sort-result.txt
가위
바위
보
명령이 실행된 이후 출력된 결과는 [[/cmd/tee]]를 끼워넣기 전과 똑같아 보이지만,
[[/cmd/sort#option-random]]{sort -R}의 결과를 [[/cmd/tee]]{tee}가 sort-result.txt 파일로 빼돌려 저장했다는 것을 알 수 있습니다.
이것도 그림으로 그려보면 이해하기 쉽습니다.

[[/cmd/tee]]{tee}가 입력받은 출력을 파일로 빼돌리는 부분을 빨간색으로 표시했습니다.
[[/cmd/tee]]를 사용하면 이와 같이 중간에 값이 어떻게 되었는지를 확인하기 좋습니다.
명령 파이프라인의 마지막에 tee 사용하기
그런데 의외로 중간에서만 사용하는 것이 아니라 명령 파이프라인의 마지막에서도 [[/cmd/tee]]를 사용하는 경우가 은근히 많습니다.
printf "가위\n바위\n보\n" \
| sort -R \
| tail -1
| tee result.txt
이렇게 하면 명령 파이프라인의 최종 출력이 어떻게 될까요?
화면으로도 출력되고, 파일로도 출력됩니다.
출력 결과가 수천줄이 넘어가는 명령 파이프라인의 경우에는 실행이 완료되고 나서 스크롤을 계속 올려서 처음부터 확인해야 하는 번거로움이 있을 수 있습니다. 하지만 이렇게 [[/cmd/tee]]를 마지막에 사용해주면 대량의 출력 결과 앞부분이 궁금할 때 귀찮게 스크롤하지 않고 그냥 파일을 열어서 앞부분만 확인할 수 있습니다.
# less 뷰어로 열어서 원하는대로 스크롤
cat result.txt | less
# head를 써서 첫 20줄만 확인
head -n 20 result.txt
시험삼아 [[/cmd/seq]]를 사용해 1부터 1000까지의 수를 출력하고, 이를 [[/cmd/tee]]로 연결해 봅시다.
seq 1000 | tee result.txt
이 명령을 실행하면 1부터 1000까지의 수가 1000줄에 걸쳐 순서대로 출력되므로 앞부분을 보려면 스크롤을 많이 올려야 합니다.
하지만 결과가 화면에 출력되긴 했지만 파일로도 똑같은 내용이 출력되었으므로 파일을 열어서 앞부분만 확인하면 됩니다.
$ wc -l result.txt # 파일의 총 줄 수 확인
1000 result.txt
$ head result.txt # 파일의 앞부분 10줄만 출력
1
2
3
4
5
6
7
8
9
10
tee로 출력을 /dev/tty로 흘려보내기
[[/cmd/tee]]를 쓰면 출력을 빼돌려서 파일로 저장할 수 있다는 것을 알게 되었습니다.
그런데 가끔은 굳이 파일로 저장할 필요가 없을 때도 있잖아요? 그냥 출력만 화면에 보여주면 되는 경우도 있습니다.
이럴 땐 [[/cmd/tee]]가 [[/cmd/tty]]{/dev/tty}로 출력하도록 해주면 됩니다.
$ printf "가위\n바위\n보\n" | sort -R | tee /dev/tty | tail -1
가위
보
바위
바위
첫 세 줄(가위 보 바위)는 [[/cmd/tee]]가 [[/cmd/tty]]{/dev/tty} 파일로 출력을 보낸 결과이고,
마지막 한 줄(바위)은 전체 명령 파이프라인의 마지막 표준출력 결과입니다.
이런 신기한 결과가 나오는 이유는 [[/cmd/tty]]{/dev/tty}가 현재 우리가 사용하고 있는 터미널 장치를 가리키는 특수 파일이기 때문입니다. [[/cmd/tty]]{/dev/tty}는 터미널 장치이므로 입력 스트림을 받으면 터미널 화면에 출력을 해줍니다.
[[/cmd/tty]]{/dev/tty}가 장치 파일이라는 특성을 활용해 새로운 파일을 생성하지 않으면서도 우리가 보고 있는 터미널 화면으로 중간 결과를 출력하는 재미있는 트릭이라 할 수 있습니다.
명령어 파이프라인을 디버깅할 때 은근히 자주 써먹는 편이니 기억해두면 좋습니다.
한편, [[/cmd/tty]]{/dev/tty}로 보낸 텍스트 스트림은 표준 출력이 아니라 [[/cmd/tee]]{tee}가 빼돌려서 터미널 장치로 보낸 출력이기 때문에,
>를 써서 1번 채널로 리다이렉팅을 해줘도 파일로 입력되지 않습니다.
$ printf "가위\n바위\n보\n" | sort -R | tee /dev/tty | tail -1 > result.txt
보
바위
가위
- 위의 명령 파이프라인에서
보 바위 가위는 명령 파이프라인의 표준출력이 아닙니다.보 바위 가위는 [[/cmd/tty]]{/dev/tty}로 입력된 텍스트이며 결과적으로 화면으로 출력되었습니다.
- 명령 파이프라인의 표준출력은
result.txt파일로 리다이렉팅되었습니다.

이는 result.txt 파일의 내용을 확인해보면 알 수 있습니다.
$ head result.txt
가위
/dev/tty 동작 알아보기
[[/cmd/tty]]{/dev/tty}의 동작을 알아보기는 쉽습니다.
[[/cmd/echo]]를 [[/cmd/tty]]{/dev/tty} 파일로 출력을 리다이렉팅하면 터미널 화면에 출력됩니다.
$ echo 안녕하세요 > /dev/tty
안녕하세요
사실 device 디렉토리의 tty 장치 파일은 하나가 아닙니다. 매우 많습니다.
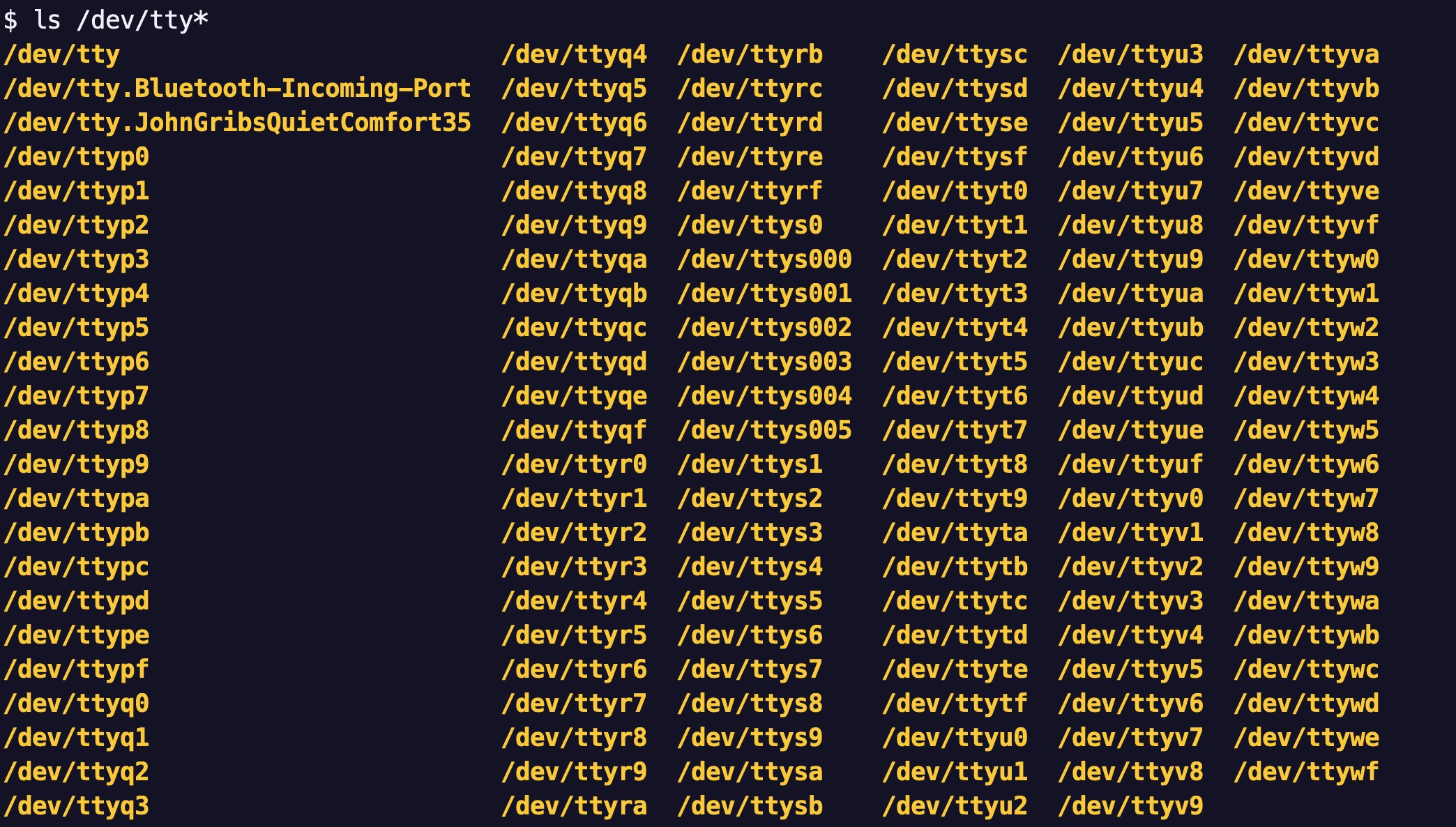
이들 대부분은 macOS 컴퓨터에서 내가 실행시킨 애플리케이션들이나 OS의 주요 프로세스들과 연결된 터미널들입니다.
프로세스 상태를 볼 수 있는 ps 명령을 실행해보면 내가 실행시킨 애플리케이션들의 프로세스들과 연결된 터미널들의 목록을 볼 수 있습니다.
$ ps -a
PID TTY TIME CMD
16473 ttys000 0:00.01 login -pfl johngrib /bin/bash -c exec -la bash /bin/bash
16474 ttys000 0:00.03 -bash
16323 ttys001 0:00.01 login -pfl johngrib /bin/bash -c exec -la bash /bin/bash
16324 ttys001 0:00.03 -bash
16703 ttys001 0:00.01 ps -a
16588 ttys002 0:00.01 login -pfl johngrib /bin/bash -c exec -la bash /bin/bash
16589 ttys002 0:00.03 -bash
두번째 컬럼을 잘 봐봅시다.
ttys000, ttys001, ttys002 이렇게 3개의 tty를 확인할 수 있습니다.
아니면 [[/cmd/cut]]를 써서 두번째 컬럼만 뽑아내고, [[/cmd/uniq]]로 중복을 제거해서 볼 수도 있겠죠.
$ ps -a | cut -d' ' -f2 | uniq
ttys000
ttys001
ttys002
아무튼 ttys000, ttys001, ttys002 이렇게 3개의 tty를 확인했습니다.
왜 3개이냐 하면, 제가 지금 터미널 탭을 3개를 띄워놓은 상태이기 때문입니다.
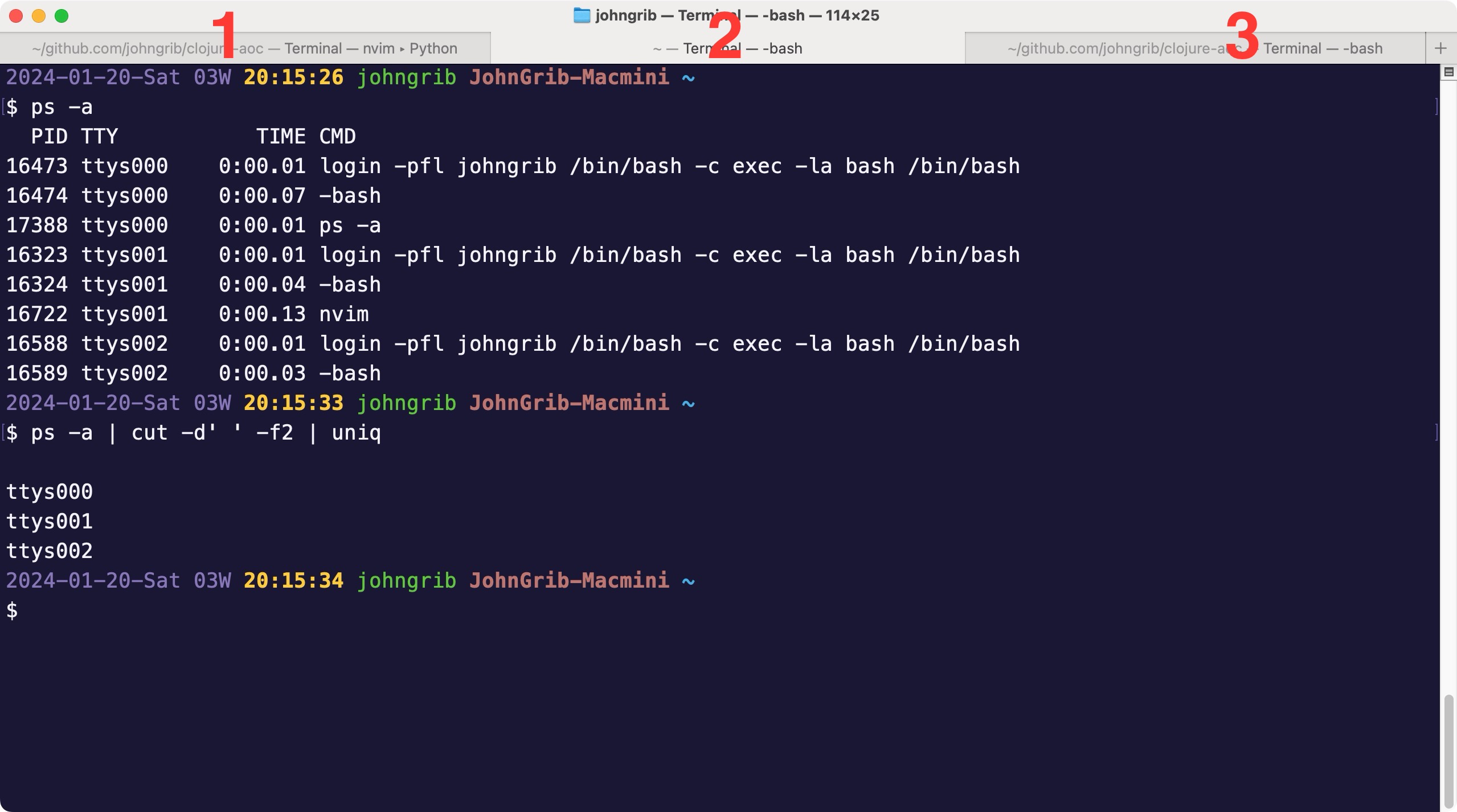
각 터미널이 어떤 tty인지 확인하려면 간단하게 해당 터미널에서 [[/cmd/tty]] 명령을 입력해보면 됩니다. 숫자는 적당히 생성된 순으로 부여되기 때문에 예상한 숫자와 좀 다를 수도 있습니다.
$ tty
/dev/ttys000
현재 터미널은 /dev/ttys000이군요.
출력을 두 개로 쪼개서 현재 터미널인 /dev/ttys000과 /dev/tty로 보내보면 /dev/tty가 현재 터미널로 연결되어 있음을 알 수 있습니다.
$ tty
/dev/ttys000
$ echo 안녕하세요 | tee /dev/ttys000 > /dev/tty
안녕하세요
안녕하세요
그렇다면 현재 터미널이 아닌 다른 터미널로 문자열을 보내보면 해당 터미널에 출력이 되겠죠.
/dev/ttys002 터미널에서 /dev/ttys000 터미널로 문자열을 보내보겠습니다.
$ tty # 확인
/dev/ttys002
$ echo 안녕하세요 > /dev/ttys000
출력이 보이지 않습니다. 이제 탭을 이동해서 /dev/ttys000 터미널로 가서 확인해 봅시다.
$ tty # 아까 확인한 결과
/dev/ttys000
$ 안녕하세요
$ 프롬프트 오른쪽에 다른 터미널에서 보낸 문자열 안녕하세요가 출력되어 있네요.
여러 터미널을 띄워놓고 이걸 실험해보면 꽤 재미있을 것입니다.
이렇게 [[/cmd/tty]]{/dev/tty}로 직접 텍스트를 보내면 해당 터미널에 출력됩니다.
이런 특성을 응용하면 특정한 메시지를 표준출력이나 표준에러가 아니라 그냥 터미널에 출력만 하는 트릭으로 써먹을 수 있습니다.
터미널 사용자에게 잡다한 메시지를 보여주고 싶지만, 표준출력으로는 해당 프로그램이 생성한 데이터만 엄격하게 내보내고 싶고, 표준에러로는 정말로 에러와 관련된 내용만 내보내고 싶을 때 쓸 수 있는 것입니다.
파이프라인을 이루는 각 명령은 비동기 방식으로 실행된다
앞에서 생성했던 result.txt 파일의 내용을 비워 봅시다.
다양한 방법이 있는데, 이번에는 앞에서 배웠던 /dev/null을 써서 해보겠습니다.
이렇게 하는 방법도 있다는 것을 보여주기 위해서입니다.
$ cat result.txt
바위
$ cat /dev/null > result.txt
$ cat result.txt
null 디바이스를 읽은 결과를 result.txt 파일로 리다이렉팅해 result.txt 파일의 내용을 비웠습니다.
이렇게 하면 result.txt 파일의 내용이 비워졌을 뿐 아니라 파일의 사이즈도 0이 되었습니다.
[[/cmd/file]]와 [[/cmd/wc]]로 확인해 봅시다.
$ file result.txt
result.txt: empty
$ wc -c result.txt
0 result.txt
이제 [[/cmd/tail]]{tail -f} 명령을 써서 result.txt 파일의 내용을 읽어봅시다.
[[/cmd/tail]]는 파일의 마지막 10줄을 보여주는 명령이었다는 것을 기억하고 있을 것입니다.
그런데 [[/cmd/tail]]{tail에 -f 옵션을 주면} 파일에 추가되는 내용을 실시간으로 출력해주는 모니터링 기능이 됩니다.
tail -f result.txt | grep hello
위의 명령어 파이프라인은 다음과 같이 작동합니다.
- [[/cmd/tail]]{tail}은
result.txt파일의 내용을 모니터링하고, 모든 내용을 출력합니다.- [[/cmd/tail]]{tail}의 출력은 [[/cmd/grep]]{grep}의 입력이 됩니다.
- [[/cmd/grep]]{grep}은 입력으로 받는 내용 중에서
hello가 포함된 라인이 있다면 그 라인을 출력합니다.
이 명령은 [[/cmd/tail]]{tail -f} 때문에 실행하면 자동으로 종료되지 않고 계속 떠 있게 됩니다.
이제 다른 터미널을 열고 다음과 같이 result.txt 파일에 자유롭게 내용을 추가해 봅시다.
echo hello? >> result.txt
echo hello... >> result.txt
echo asdf >> result.txt
echo hello1 >> result.txt
그리고 [[/cmd/tail]]{tail -f}를 실행한 터미널로 돌아와보면 다음과 같은 결과를 볼 수 있습니다.

흥미로운 것은 [[/cmd/tail]] 뿐 아니라 [[/cmd/grep]]도 프로세스를 종료하지 않고,
입력에서 계속 hello와 매치되는 라인을 필터링해 보여주고 있다는 것입니다.
이제 다른 터미널에서 프로세스 상태를 보는 명령인 ps를 실행해 보면 흥미로운 사실을 알 수 있습니다.
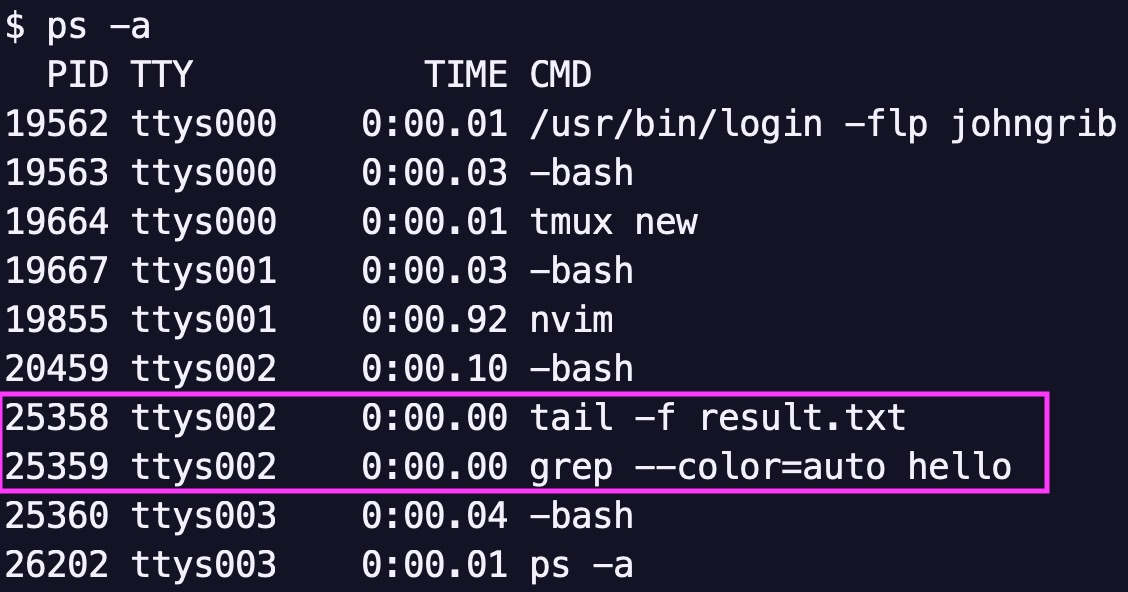
tail -f result.txt | grep hello가 작동되고 있는 터미널 /dev/ttys002에서 3개의 프로세스가 실행되고 있습니다.
그리고 그들 중 2개는 tail과 grep입니다.
- PID 20459 -bash
- PID 25358
tail -f result.txt - PID 25359
grep --color=auto hello
즉, 파이프라인을 구성하는 명령들은 앞의 명령이 종료된 다음 앞의 명령이 생성한 출력을 입력으로 받는 방식으로 순차적으로 작동하지 않습니다.
각 명령들의 프로세스는 별도로 실행되며 0, 1, 2 를 통해 메시지를 전달하는 방식으로 작동합니다.
한번 더 확인해보기 위해 파이프라인 자신을 구성하는 프로세스들을 확인하는 명령을 작성해 봅시다.
$ tty
/dev/ttys002
$ ps -a | egrep ttys002 | sed 's/^/ /' | sed 's/^ //'
20459 ttys002 0:00.11 -bash
28135 ttys002 0:00.01 ps -a
28136 ttys002 0:00.00 egrep --color=auto ttys002
28137 ttys002 0:00.00 sed s/^/ /
28138 ttys002 0:00.00 sed s/^ //
명령어 파이프라인을 구성한 모든 명령의 프로세스들의 PID를 확인할 수 있습니다.
ps -aegrep ttys002sed 's/^/ /'sed 's/^ //'
sed를 일부러 2개 넣은 것은 같은 명령이라 하더라도 각각의 프로세스가 별도로 생성되었다는 것을 보여주기 위해서였습니다.
이전, 다음 문서
- 이전 문서: [[/mac/terminal-guide/01]]
- 다음 문서: [[/mac/terminal-guide/03]]