(요약) The Transaction Concept - Virtues and Limitations by Jim Gray, June 1981
짐 그레이의 트랜잭션 컨셉 요약
- 일러두기
- 요약
- ABSTRACT
- INTRODUCTION: What is a transaction?
- A GENERAL MODEL OF TRANSACTIONS
- NonStop™: Making failures rare
- UPDATE IN PLACE: A poison apple?
- TIME-DOMAIN ADDRESSING: One solution
- LOGGING AND LOCKING: Another solution
- SUMMARY
- LIMITATIONS OF KNOWN TECHNIQUES
- NESTED TRANSACTIONS
- LONG-LIVED TRANSACTIONS
- INTEGRATION WITH PROGRAMMING LANGUAGES
- SUMMARY
- ACKNOWLEDGEMENTS
- REFERENCES
- 참고문헌
일러두기
이 개요는 내 편의대로 번역해 요약한 것이므로, 정확한 내용은 원문을 참고할 것.
요약
원문을 다음 링크에서 다운로드 받아 읽을 수 있다.
- The Transaction Concept: Virtues and Limitations by Jim Gray 1981
ABSTRACT
ABSTRACT: A transaction is a transformation of state which has the properties of atomicity (all or nothing), durability (effects survive failures) and consistency (a correct transformation). The transaction concept is key to the structuring of data management applications. The concept may have applicability to programming systems in general. This paper restates the transaction concepts and attempts to put several implementation approaches in perspective. It then describes some areas which require further study: (1) the integration of the transaction concept with the notion of abstract data type, (2) some techniques to allow transactions to be composed of sub-transactions, and (3) handling transactions which last for extremely long times (days or months).
개요
트랜잭션은 다음과 같은 속성을 갖는 상태 변환을 의미한다.
- 원자성(all or nothing)
- 지속성(effects survive failures)
- 일관성(a correct transformation)
트랜잭션 개념은 데이터 관리 애플리케이션 구조화의 핵심이며, 이 개념은 일반적인 프로그래밍 체계에 적용할 수 있다.
이 페이퍼는 트랜잭션 개념을 다시 설명하고 다양한 관점에서의 구현을 논의한다. 그러고 나서 추가적인 연구가 필요한 몇 가지 영역을 설명할 것이다.
- 추가적인 연구가 필요한 영역들
- (1) 추상 데이터 유형 개념과 트랜잭션 개념의 통합.
- (2) 트랜잭션이 하위 트랜잭션으로 구성되도록 허용하는 몇 가지 기술.
- (3) 극단적으로 긴 시간(몇일, 몇 달 단위)동안 지속되는 트랜잭션의 처리.
INTRODUCTION: What is a transaction?
들어가며: 트랜잭션이란 무엇인가?
The transaction concept derives from contract law. In making a contract, two or more parties negotiate for a while and then make a deal. The deal is made binding by the joint signature of a document or by some other act (as simple as a handshake or nod). If the parties are rather suspicious of one another or just want to be safe, they appoint an intermediary (usually called an escrow officer to coordinate the commitment of the transaction.
트랜잭션 개념은 계약 규칙(contract law)에서 비롯된다.
- 계약을 맺을 때: 둘 이상의 당사자가 잠시 협상(negotiate)을 한 다음 거래(deal)를 한다.
- 거래: 문서의 공동 서명이나 다른 합의 행위(악수나 고개를 끄덕이는 등)에 의해 구속력이 있다.
- 만약 당사자들이 서로를 의심하거나, 안전한 거래를 원할 경우 중개자(intermediary)를 지정한다.
- 이 중재자를 에스크로 담당자(escrow officer)라 부른다.
The Christian wedding ceremony gives a good example of such a contract. The bride and groom “negotiate” for days or years and then appoint a minister to conduct the marriage ceremony. The minister first asks if anyone has any objections to the marriage; he then asks the bride and groom if they agree to the marriage. If they both say, “I do”, he pronounces them man and wife.
기독교식 결혼식은 그러한 계약(contract)의 좋은 예이다.
- 신부와 신랑은 몇일 ~ 몇년동안 협상을 한 다음, 결혼식을 진행할 목사를 임명한다.
- 목사는 가장 먼저 결혼식 하객들에게 결혼식에 반대하는 사람이 있는지를 묻는다.
- 목사는 그 다음으로 신부와 신랑에게 결혼에 동의하는지 물어본다.
- 신부와 신랑이 모두 동의하면, 목사는 두 사람이 부부가 되었음을 선언한다.
Of course, a contract is simply an agreement. Individuals can violate if they are willing to break the law. But legally, a contract (transaction) can only be annulled if it was illegal in the first place. Adjustment of a bad transaction is done via further compensating transactions (including legal redress).
물론 계약(contract)은 단순한 동의의 일종이다. 따라서 개인이 마음먹고 법(law)을 위반하려 한다면 계약도 어길 수 있다.
- 그러나 법의 테두리 안에서 계약(transaction)은 처음부터 불법적으로 성사된 경우에만 해지될 수 있다.
- 잘못된 계약의 조정은 추가적인 보상 거래(법적 보상 포함)를 통해 이루어지게 된다.
The transaction concept emerges with the following properties:
- Consistency: the transaction must obey legal protocols.
- Atomicity: it either happens or it does not; either all are bound by the contract or none are.
- Durability: once a transaction is committed, it cannot be abrogated.
트랜잭션 개념은 다음의 속성들로 나타낼 수 있다.
- 일관성(Consistency): 트랜잭션은 적법한 프로토콜을 따라야 한다.
- 원자성(Atomicity): 발생하거나 발생하지 않아야 한다. 계약에 모든 것이 구속되거나, 전혀 그렇지 않거나 해야 한다.
- 지속성(Durability): 일단 트랜잭션이 확정되면(committed), 취소할 수 없다.
A GENERAL MODEL OF TRANSACTIONS
일반적인 트랜잭션 모델
Translating the transaction concept to the realm of computer science, we observe that most of the transactions we see around us (banking, car rental, or buying groceries) may be reflected in a computer as transformations of a system state.
A system state consists of records and devices with changeable values. The system state includes assertions about the values of records and about the allowed transformations of the values. These assertions are called the system consistency constraints.
The system provides actions which read and transform the values of records and devices. A collection of actions which comprise a consistent transformation of the state may be grouped to form a transaction. Transactions preserve the system consistency constraints – they obey the laws by transforming consistent states into new consistent states.
트랜잭션 개념을 컴퓨터 과학 영역에 적용해보자. 우리 주변에서 볼 수 있는 대부분의 트랜잭션(은행, 자동차 렌탈, 식료품 구매)을 컴퓨터에 반영해 보면 시스템 상태 변환 과정이라는 것을 알 수 있다.
- 시스템 상태는 변경 가능한 값을 가진 장치와 레코드들로 구성된다.
- 시스템 상태에는 레코드 값 및 허용된 값 변환에 대한 단언(assertions)이 포함된다.
- 이러한 단언을 시스템 일관성 제약이라 부른다.
- 시스템은 레코드와 장치의 값을 읽고 변환하는 작업을 제공한다.
- 상태의 일관된 변환을 구성하는 액션 집합을 그룹화해서 하나의 트랜잭션을 형성할 수 있다.
- 트랜잭션은 시스템 일관성 제약을 보존한다.
- 즉, 일관성있는 상태를 새로운 일관성 있는 상태로 변환하는 방식을 통해 규칙을 준수한다.
Transactions must be atomic and durable: either all actions are done and the transaction is said to commit, or none of the effects of the transaction survive and the transaction is said to abort.
- 트랜잭션은 원자적이고 지속성이 있어야 한다.
- 모든 작업이 수행된 이후에는 트랜잭션이 커밋되거나, 트랜잭션의 효과가 유지되지 않고 취소되었거나 둘 중의 하나여야 한다.
These definitions need slight refinement to allow some actins to be ignored and to account for others which cannot be undone. Actions on entities are categorized as:
- Unprotected: the action need not be undone or redone if the transaction must be aborted or the entity value needs to be reconstructed.
- Protected: the action can and must be undone or redone if the transaction must be aborted or if the entity value needs to be reconstructed.
- Real: once done, the action cannot be undone.
Operations on temporary files and the transmission of intermediate messages are examples of unprotected actions. Conventional database and message operations are examples of protected actions. Transaction commitment and operations on real devices (cash dispensers and airplane wings) are examples of real actions.
무시되어야 하는 작업이나 취소할 수 없는 작업 등을 설명하기 위해 몇 가지 개념을 더 추가하자.
- Unprotected: 트랜잭션을 중단해야 하거나 엔티티 값을 재구성해야 하는 경우에도 작업을 실행 취소하거나 다시 실행할 필요가 없음.
- 예: 임시 파일에 대한 작업이나 중간 메시지 전송.
- Protected: 트랜잭션을 중단해야 하거나 엔티티 값을 재구성해야 하는 경우라면 작업을 실행 취소하거나 다시 실행할 수 있음.
- 예: 일반적인 데이터베이스 및 메시지 작업.
- Real: 일단 완료되면 작업을 취소할 수 없음.
- 예: 실제 존재하는 장치들(현금 지급기, 비행기 날개)에 대한 거래 약속 및 운영.
Each transaction is defined as having exactly one of two outcomes: committed or aborted. All protected and real actions of committed transactions persist, even in the presence of failures. On the other hand, none of the effects of protected and real actions of an aborted transaction are ever visible to other transactions.
Once a transaction commits, its effects can only be altered by running further transactions. For example, if someone is underpaid, the corrective action is to run another transaction which pays an additional sum. Such post facto transactions are called compensating transactions.
각각의 트랜잭션은 "커밋(committed)" 또는 "취소(aborted)"라는 둘 중 하나의 결과를 낸다.
- 커밋된 트랜잭션의 모든 protected 또는 real 작업은 실패가 발생한 경우에도 계속 유지된다.
- 그러나 중단된(aborted) 트랜잭션의 protected 또는 real 작업의 영향은 다른 트랜잭션에서는 볼 수 없다.
일단 트랜잭션이 커밋되면, 다른 추가 트랜잭션을 실행해야지만 그 결과를 대체할 수 있다. 예를 들어 보자.
- 누군가가 돈을 부족하게 받았다면, 이에 대한 수정 조치는 부족한 만큼의 추가 금액을 지불하는 다른 트랜잭션을 실행하는 것이다.
- 이러한 사후 거래(post facto transactions)를 보상 거래(compensating transactions)라고 한다.
A simple transaction is a linear sequence of actions. A complex transaction may have concurrency within a transaction: the initiation of one action may depend on the outcome of a group of actions. Such transactions seem to have transactions nested within them, although the effects of the nested transactions are only visible to other parts of the transaction (see Figure 1).
간단한 트랜잭션과 복잡한 트랜잭션.
- 간단한 트랜잭션은 한 줄로 이어지는 일련(linear sequence)의 작업들이다.
- 복잡한 트랜잭션은 내부에서 동시성(concurrency) 처리가 있을 수 있다.
- 특정한 작업의 초기화는 다른 작업 그룹의 작업 결과에 의존할 수도 있다.
- 이러한 트랜잭션은 트랜잭션이 중첩(nested)된 것처럼 보이지만 중첩된 트랜잭션의 효과는 트랜잭션의 다른 부분에서만 볼 수 있다.
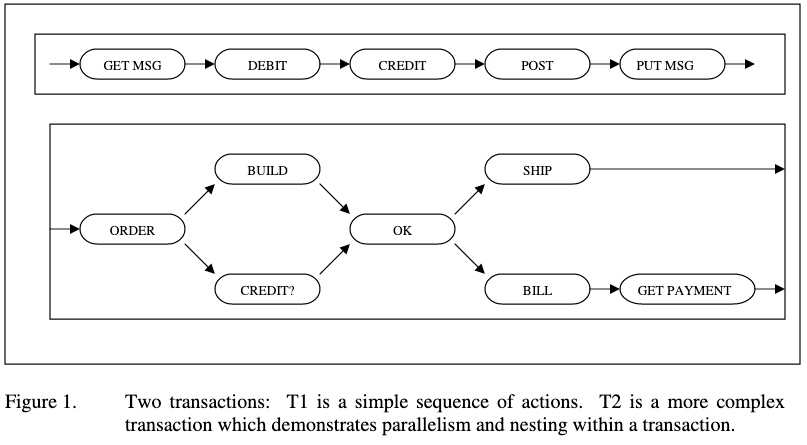
- T1: 간단한 일련의 작업.
- T2: 병렬성과 트랜잭션 중첩이 있는 복잡한 트랜잭션.
NonStop™: Making failures rare
NonStop™: 실패를 거의 발생시키지 않기
One way to get transaction atomicity and durability is to build a perfect system which never fails. Suppose you built perfect hardware which never failed, and software which did exactly what it was supposed to do. Your system would be very popular and all transactions would always be successful. But the system would fail occasionally because the people who adapted your system to their environment would make some mistakes (application programming errors) and the people who operated the system would make some mistakes (data entry and procedural errors). Even with very careful management, the system would fail every few months or years and at least one transaction in 100 would fail due to data-entry error or authorization error [Japan].
트랜잭션의 원자성과 지속성을 확보하는 한 가지 방법은 절대로 실패하지 않는 완벽한 시스템을 구축하는 것이다.
다음과 같이 가정해 보자.
- 만약 당신이 실패한 적이 없는 완벽한 하드웨어와 할 일을 정확히 수행해온 소프트웨어를 만들어냈다고 하자.
- 이 시스템은 매우 인기있을 것이고 모든 거래는 항상 성공할 것이다.
- 그러나 이 시스템은 가끔 실패할 수도 있는데, 그 이유는 다음과 같다.
- 시스템을 자신의 환경에 맞게 조정하는 사람이 실수(애플리케이션 프로그래밍 에러)를 저지른다.
- 시스템을 운영하는 사람이 실수(데이터 입력이나 절차상의 에러)를 저지른다.
- 매우 신중하게 관리한다 해도 이 시스템은 몇 개월이나 몇 년마다 실패하는 일이 발생할 것이다.
- 데이터 입력 오류나 인증 오류 등의 이유로 100번 중 한 번 이상은 트랜잭션이 실패할 것이다.
One may draw two conclusions from this:
- You don’t have to make a perfect system. One that fails once every thousand years is good enough.
- Even if the system is perfect, some transactions will abort because of data-entry error, insufficient funds, operator cancellation, or timeout.
이에 대해 두 가지 결론을 내릴 수 있다.
- 완벽한 시스템을 만들 필요는 없다. 천 년에 한 번 실패하는 정도로도 충분히 괜찮다.
- 시스템이 완벽하다 할지라도, 데이터 입력 오류/자금 부족/운영자에 의한 취소/시간 초과 등으로 인해 일부 트랜잭션은 취소(abort)되게 되어 있다.
This section discusses techniques for "almost perfect" systems and explains their relationship to transaction processing.
Imperfection comes in several flavors. A system may fail because of a design error or because of a device failure. The error may become visible to a user or redundant checks may detect the failure and allow it to be masked from the user.
A system is unreliable if it does the wrong thing (does not detect the error). A system is unavailable if it does not do the right thing within a specified time limit. Clearly, high availability is harder to achieve than high reliability.
이 섹션에서는 "거의 완벽한" 시스템을 위한 기술(techniques)과 트랜잭션 처리와의 관계를 설명한다.
- 불완전성은 여러 가지 형태로 드러난다.
- 하나의 시스템은 설계 오류나 기계 장치 오류 때문에 실패할 수 있다.
- 오류는 사용자가 볼 수 있는 형태로 나타날 수도 있고, 검사기가 실패를 감지하여 사용자에게 보여줄 수도 있다.
- 잘못된 작업을 수행한다면(오류가 발생했는데 감지하지 못했다면) 신뢰할 수 없는(unreliable) 시스템이다.
- 주어진 시간 제한 내에 올바른 작업을 수행하지 않는다면 가용하지 않은(unavailable) 시스템이다.
- 분명한 것은, 높은 가용성(availability)이 높은 신뢰성(reliability)보다 달성하기 어렵다는 것이다.
John Von Neumann is credited with the observation that a very reliable (and available) system can be built from unreliable components [Von Neumann]. Von Neumann’s idea was to use redundancy and majority logic on a grand scale (20,000 wires for one wire) in order to get mean-times-to-failure measured in decades. Von Neumann was thinking in terms of neurons and vacuum tubes which have mean-times-to-failures measured in days and which are used in huge quantities (millions or billions) in a system. In addition, Von Neumann’s model was flat so that any failure in a chain broke the whole chain.
존 폰 노이만은 신뢰할 수 없는 구성 요소들(unreliable components)을 사용해 매우 신뢰할 수 있고(very reliable), 가용성 있는(available) 시스템을 구축할 수 있다는 것을 관찰한 바 있다. 폰 노이만의 아이디어는 다음과 같다.
- 수십년 동안 평균 무고장 시간(mean-times-to-failure)을 측정하기 위해 거대한 규모에서 다수결 함수(majority logic)를 중복해 사용한다.
- 거대한 규모: 1개의 회선을 위해 20000개의 회선을 연결.
- 폰 노이만은 평균 고장 발생 횟수를 며칠 단위로 측정했다.
- 엄청나게 많이 사용되고 있는 시스템에 쓰인 뉴런과 진공관의 관점에서 생각했다.
- 또한 폰 노이만의 모델은 민감한 편이어서 하나의 실패만 발생해도 전체 체인을 망가뜨릴 수 있었다.
Fortunately, computer systems do not need redundancy factors of 20,000 in order to get very long mean-times-to-failure. Unlike Von Neumann’s nerve nets, computer systems are hierarchically composed of modules and each module is self-checked so that it either operates correctly or detects its failure and does nothing. Such modules are called fail-fast. Fail-fast computer modules such as processors and memories achieve mean times to failure measured in months. Since relatively few modules make up a system (typically less than 100), very limited redundancy is needed to improve the system reliability.
다행히도 컴퓨터 시스템은 매우 긴 기간의 평균 무고장 시간을 얻기 위해 (폰 노이만이 고려한 것과 같은) 20000개씩이나 되는 중복 요소가 필요하지 않다.
- 폰 노이만의 신경망과 달리 컴퓨터 시스템은 모듈화된 계층 구조로 이루어져 있고, 각각의 모듈은 자체 검사 기능이 있다.
- 따라서 각 모듈은 올바르게 작동하거나, 스스로 오류를 감지하여 아무것도 하지 않는다.
- 이러한 모듈을 Fail-fast라고 한다.
- 프로세서 및 메모리와 같은 Fail-fast 컴퓨터 모듈은 몇 개월 단위로 측정된 평균 무고장 시간을 달성해낸다.
- 비교적 적은 수의 모듈이 시스템을 구성하기 때문에(보통 100개 미만) 시스템 안정성을 향상시키기 위해서는 매우 제한된 중복성이 필요하다.
Consider the simple case of discs. A typical disc fails about once a year. Failures arise from bad spots on the disc, physical failure of the spindle or electronic failure of the path to the disc. It takes about an hour to fix a disc or get a spare disc to replace it. If the discs are duplexed (mirrored), and if they fail independently, then the pair will both be down about once every three thousand years. More realistic analysis gives a mean-time-to-failure of 800 years. So a system with eight pairs of discs would have an unavailable disc pair about once a century. Without mirroring, the same system would have an unavailable disc about eight times a year.
Although duplexed discs have been used since the late sixties [Heistand], we have been slow to generalize from this experience to the observation that:
- Mean-time-to-failure of modules are measured in months.
- Modules can be made fail-fast: either they work properly or they fail to work.
- Spare modules give the appearance of mean time to repair measured in seconds or minutes.
- Duplexing such modules gives mean times to failure measured in centuries.
이를 쉽게 이해하기 위해 디스크의 경우를 생각해 보자.
- 일반적인 디스크는 약 1년에 한 번 고장난다. 고장은 디스크 표면의 불량한 지점이나, 회전축의 물리적 오류, 또는 디스크 경로상의 전기적 오류로 인해 발생한다.
- 디스크 하나를 고치거나 교체할 예비 디스크를 가져오는 데에는 약 1 시간이 걸린다.
- 만약 디스크가 이중화(미러링)되어 있고 독립적으로 실패한다면, 디스크 쌍이 둘 다 한꺼번에 다운되는 것은 약 3천년에 한 번이다.
- 좀 더 현실적으로는 평균 무고장 시간은 800년 정도이다.
- 따라서 8쌍의 디스크가 있는 시스템은 약 100년에 한 번 정도는 디스크 쌍 하나를 사용할 수 없다.
- 만약 미러링이 없다면 동일한 시스템에서 1년에 약 8번 정도는 디스크를 사용할 수 없다.
1960년대 후반부터 이중화 디스크가 사용되었지만, 오랜 시간이 지나고 나서야 이 경험을 다음과 같이 일반화할 수 있었다.
- 모듈의 평균 무고장 시간은 개월 단위로 즉정된다.
- 모듈은 fail-fast 하게 만들 수 있다.
- 예비 모듈은 몇 초 또는 몇 분으로 측정된 평균 수리 시간을 제공한다.
- 이러한 모듈을 이중화하면 몇 백년의 동안 평균 무고장 시간을 측정할 수 있을 것이다.
The systematic application of these ideas to both hardware and software produces highly reliable and highly available systems.
High availability requires rethinking many concepts of system design. Consider, for example, the issue of system maintenance: one must be able to plug components into the system while it is operating. At the hardware level, this requires Underwriters Laboratory approval that there are no high voltages around, and requires that components tolerate high power drains and surges and, and, and …. At the software level, this means that there is no "SYSGEN" and that any program or data structure can be replaced while the system is operating. These are major departures from most current system designs.
이러한 아이디어를 하드웨어와 소프트웨어 양쪽에 체계적으로 적용하면 매우 신뢰할 수 있고(highly reliable), 높은 가용성을 가진(highly available) 시스템을 만들 수 있다.
높은 가용성을 달성하려면 시스템 디자인의 많은 개념을 다시 생각해보는 것이 필요하다.
예를 들어 시스템 유지보수 문제를 생각할 수 있다.
- 시스템이 작동하는 동안 특정 컴포넌트를 시스템에 연결할 수 있어야 한다.
- 하드웨어 레벨에서 보면, 이를 위해서는 주위에 고전압이 없고, 해당 컴포넌트가 고전압과 전압 변화를 견딜 수 있다는 것 등등등에 대해 Underwriters Laboratory의 승인을 받아야 한다.
- 소프트웨어 레벨에서는 "SYSGEN"이 없으며, 시스템이 작동하는 동안 프로그램이나 데이터 구조를 교체할 수 없음을 의미한다.
- 이러한 것들은 대부분의 최신 시스템 디자인의 관점과는 차이가 있다.
- (높은 가용성 중심의 관점이 새로운 관점이라는 의미)
Commercial versions of systems that provide continuous service are beginning to appear in the marketplace. Perhaps the best known are the Tandem systems. Tandem calls its approach to high availability NonStop (a Tandem trademark). Their systems typically have mean times to failure between one and ten years. At the hardware level, modules and paths are duplexed and all components are designed for reliable and fail-fast operation [Katzman]. At the software level, the system is structured as a message-based operating system in which each process may have a backup process which continues to work of the primary process should the primary process or its supporting hardware fail [Bartlett], [Bartlett2]. Alsberg proposed a related technique [Alsberg].
지속적인 서비스를 제공하는 시스템의 상용 버전이 시장에 나타나기 시작했다.
- 아마도 가장 잘 알려진 것은 Tandem systems일 것이다(이 페이퍼는 Tandem Computers에서 작성되었음을 염두에 두자).
- Tandem은 고가용성을 확보하기 위한 접근법을 NonStop(Tandem 트레이드 마크)이라 부른다.
- 이 시스템은 일반적으로 1 ~ 10년 사이의 무고장 시간을 갖고 있다.
- 하드웨어 레벨에서 모듈과 경로는 이중화되어 있으며, 모든 컴포넌트는 안정적이고(reliable), fail-fast하게 작동하도록 설계되었다.
- 소프트웨어 레벨에서 시스템은 메시지 기반 운영 체제로 구성된다. 그리고 각 프로세스에는 기본 프로세스 또는 지원 하드웨어가 실패할 경우 기본 프로세스를 계속 작동하는 백업 프로세스를 준비할 수 있다.
It is not easy to build a highly available system. Given such a system, it is non-trivial to program fault-tolerant applications unless other tools are provided; takeover by the backup process when the primary process fails is delicate. The backup process must somehow continue the computation where it left off without propagating the failure to other processes.
고가용성 시스템을 구축하는 것은 쉽지 않은 일이다.
- 이런 시스템에서 툴이 제공되지 않을 때 내결함성(fault-tolerant) 애플리케이션을 프로그래밍하는 것은 자명하지 않은(non-trivial) 일이다.
- 프라이머리 프로세스가 실패할 경우 백업 프로세스에 의한 테이크 오버가 매우 까다롭기 때문이다.
- 백업 프로세스는 실패를 다른 프로세스로 전파하지 않고 중단된 곳에서 작업을 계속 해야한다.
One strategy for writing fault-tolerant applications is to have the primary process “checkpoint” its state to the backup process prior to each operation. If the primary fails, the backup process picks up the conversation where the primary left off. Resynchronizing the requestor and server processes in such an event is very subtle.
Another strategy for writing fault-tolerant applications is to collect all the processes of a computation together as a transaction and to reset them all to the initial transaction state in case of a failure. In the event of a failure, the transaction is undone (to a save point or to the beginning) and continued from that point by a new process. The backout and restart facilities provided by transaction management free the application programmer from concerns about failures or process pairs.
내결함성(fault-tolerant) 애플리케이션을 만들기 위한 한 가지 전략은 다음과 같다.
- 각 작업 이전에 프라이머리 프로세스의 상태를 백업 프로세스에 "체크포인트"하는 것이다.
- 프라이머리 프로세스가 실패하면 백업 프로세스는 프라이머리가 남겨둔 곳부터 대화를 진행하도록 한다.
- 이러한 이벤트에서 요청자(requestor)와 서버 프로세스 사이를 다시 동기화하는 것은 매우 예민한 일이다.
내결함성 애플리케이션을 만들기 위한 또다른 전략은 다음과 같다.
- 계산의 모든 프로세스를 트랜잭션으로 함께 수집하고, 실패가 발생할 때 모든 프로세스를 초기 트랜잭션 상태로 재설정하는 것이다.
- 실패가 발생하면 트랜잭션이 (저장 지점 또는 시작 지점으로) 실행 취소되고, 새 프로세스에 의해 해당 시점부터 작동한다.
- 트랜잭션 관리에서 제공하는 backout 및 재시작 기능은 애플리케이션 프로그래머에게 실패 또는 프로세스 중복 쌍에 대한 걱정을 덜어준다.
The implementers of the transaction concept must use the primitive process-pair mechanism and must deal with the subtleties of NonStop; but, thereafter, all programmers may rely on the transaction mechanism and hence may easily write fault-tolerant software [Borr]. Programs in such a system look no different from programs in a conventional system except that they contain the verbs BEGIN-TRANSACTION, COMMIT-TRANSACTION and ABORT-TRANSACTION.
트랜잭션 개념을 구현하는 사람은 원시 프로세스 쌍 메커니즘(primitive process-pair mechanism)을 사용해야 하며, NonStop을 섬세하게 잘 다룰 수 있어야 한다.
- 그러나 일단 구현이 완료된 이후에는 모든 프로그래머가 트랜잭션 메커니즘에 의존할 수 있으므로 내결함성 소프트웨어를 쉽게 작성할 수 있다.
- 이러한 시스템의 프로그램들은
BEGIN-TRANSACTION,COMMIT-TRANSACTION및ABORT-TRANSACTION동사를 포함한다는 점을 빼고는 기존 시스템의 프로그램과 별반 다르지 않다.
Use of the transaction concept allows the application programmer to abort the transaction in case the input data or system state looks bad. This feature comes at no additional cost because the mechanism to undo a transaction is already in place.
In addition, if transactions are implemented with logging, then the transaction manager may be used to reconstruct the system state from an old state plus the log. This provides transaction durability in the presence of multiple failures.
트랜잭션 개념을 사용하면 다음과 같은 장점이 있다.
- 입력 데이터나 시스템 상태가 좋아 보이지 않을 때 애플리케이션 프로그래머가 트랜잭션을 중단하는 것이 가능하다.
- 이 기능은 트랜잭션을 취소하는 메커니즘이 이미 들어가 있으므로 추가 비용이 들어가지 않는다.
- 또한, 트랜잭션이 logging으로 구현되면 트랜잭션 관리자를 사용하여 이전 상태와 로그를 통해 시스템 상태를 재구축할 수 있다.
- 이 기능 덕분에 여러 건의 실패가 발생하는 경우에도 트랜잭션의 지속성을 보장할 수 있다.
In summary, NonStop™ techniques can make computer systems appear to have failure rates measured in decades or centuries. In practice, systems have a failure rates measured in months or years because of operator error (about one per year) and application program errors (several per year) [Japan]. These now become the main limit of system reliability rather than the software or hardware supplied by the manufacturer.
요약하자면 NonStop™ 기술은 컴퓨터 시스템의 고장률을 수십년 또는 수세기 단위로 측정되도록 할 수 있다.
- 실제의 시스템은 운영자 오류(약 1년에 1번)나 애플리케이션 프로그램 오류(약 1년에 여러 차례)로 인해 몇 개월 또는 몇 년 단위로 오류가 발생할 수 있다.
- 이는 이제 제조업체에서 제공하는 소프트웨어나 하드웨어의 문제가 아닌 시스템 안정성(reliability)의 주요 한계이다.
This section showed the need for the transaction concept to ease the implementation of fault-tolerant applications. There are two apparently different approaches to implementing the transaction concept: time-domain addressing and logging plus locking. The following sections explain these two approaches and contract them.
To give a preview of the two techniques, logging clusters the current state of all objects together and relegates old versions to a history file called a log. Time-domain addressing clusters the complete history (all versions) of each object with the object. Each organization will be seen to have some unique virtues.
이 섹션에서는 내결함성 애플리케이션의 구현을 용이하게 하기 위한 트랜잭션 개념의 필요성을 보여주었다.
트랜잭션 개념을 구현하는 데에는 두 가지 상이한 접근 방법이 있다. 다음 섹션에서는 이 두 가지 접근 방법을 설명한다.
- 시간 도메인 주소 지정 방법.
- 로깅 및 잠금 방법.
각각의 장점을 갖고 있는 두 가지 기술에 대해 미리 언급하자면, 다음과 같다.
- 로깅은 모든 객체의 현재 상태를 클러스터링하고, 이전 버전을 log라는 히스토리 파일로 기록해 둔다.
- 시간 도메인 주소 지정은 각 객체의 전체 기록(모든 버전)을 객체와 함께 클러스터링 한다.
UPDATE IN PLACE: A poison apple?
덮어쓰기 업데이트는 독이 든 사과인가?
When bookkeeping was done with clay tablets or paper and ink, accountants developed some clear rules about good accounting practices. One of the cardinal rules is double-entry bookkeeping so that calculations are self-checking, thereby making them fail-fast. A second rule is that one never alters the books; if an error is made, it is annotated and a new compensating entry is made in the books. The books are thus a complete history of the transactions of the business.
점토판이나 종이로 된 회계 장부에 기록을 하던 회계사들은 몇 가지 괜찮은 규칙을 개발했다.
- 그런 기본 규칙 중 하나는, 자체적인 점검이 가능해서 계산이 빠르게 실패하도록 하는 복식 부기(double-entry bookkeeping)이다.
- 두 번째 규칙은 장부 기록(books)을 절대 수정하지 않는다는 것이다.
- 오류가 발생하면 (지우고 다시 쓰는 것이 아니라) 주석을 추가하고, 장부에 새로운 보상 항목을 작성한다.
- 이를 통해 기록은 비즈니스 거래의 완전한 히스토리가 된다.
The first computer systems obeyed these rules. The bookkeeping entries were represented on punched cards or on tape as records. A run would take in the old master and the day’s activity, represented as records on punched cards. The result was a new master. The old master was never updated. This was due in part to good accounting practices but also due to the technical aspects of cards and tape: writing a new tape was easier than re-writing the old tape.
The advent of direct access storage (discs and drums) changed this. It was now possible to update only a part of a file. Rather than copying the whole disc whenever one part was updated, it became attractive to update just the parts that changed in order to construct the new master. Some of these techniques, notably side files and differential files [Severence] did not update the old master and hence followed good accounting techniques. But for performance reasons, most disc-based systems have been seduced into updating the data in place.
최초의 컴퓨터 시스템은 이러한 규칙을 따랐다.
- 부기(bookkeeping) 항목은 천공 카드나 테이프에 기록되었다.
- 한번의 실행으로 이전 마스터와 해당 일의 활동을 가져올 수 있다.
- 그리고 그 결과는 새로운 마스터가 되며, 이전 마스터는 업데이트되지 않는다.
- 이런 방식은 회계 관행에서 가져온 것이기도 했지만, 천공 카드와 테이프의 기술적인 측면에서 비롯된 것이기도 했다.
- 새 테이프에 쓰는 것이 기존 테이프에 다시 쓰는 것보다 쉬웠기 때문이다.
그러나 디스크나 드럼 같은 직접 엑세스 스토리지(direct access storage)가 출현하며 이러한 상황이 바뀌었다.
- 파일의 일부만 업데이트하는 것이 가능해진 것이다.
- 한 부분을 업데이트할 때 전체 디스크를 복사하는 것보다, 새 마스터를 구성하기 위해 변경한 부분만 업데이트하는 것이 꽤 매력적으로 느껴졌다.
- 이러한 기술 중 몇몇은, 특히 사이드 파일이나 변경(differential) 파일들은 이전 마스터를 업데이트하지 않았으므로 회계사들의 좋은 규칙을 따른 것이라 할 수 있었다.
- 그러나 대부분의 디스크 기반 시스템은 성능상의 이유로 덮어쓰는 업데이트(update in place)라는 유혹에 시달리게 되었다.
TIME-DOMAIN ADDRESSING: One solution
방법 하나: 시간-도메인 주소 지정 기법
Update-in-place strikes many systems designers as a cardinal sin: it violates traditional accounting practices that have been observed for hundreds of years. There have been several proposals for systems in which objects are never altered: rather an object is considered to have a time history and object addresses become <name,time> rather than simply name. In such a system, an object is not “updated”; it is “evolved” to have some additional information. Evolving an object consists of creating a new value and appending it as the current (as of this time) value of the object. The old value continues to exist and may be addressed by specifying any time within the time interval that value was current. Such systems are called “time-domain addressing” or “version-oriented systems”. Some call them immutable object systems, but I think that is a misnomer since objects do change values with time.
덮어쓰기 방식의 업데이트(Update-in-place)는 많은 시스템 설계자들에게 수백년간 지켜져온 회계 관행을 위반하는 엄청난 죄악일 수 있다.
- 객체가 변경되지 않는 시스템에 대해서는 다양한 제안 사항이 있다.
- 각 객체는 시간 기록을 갖고 있고, 객체의 주소는 단순한 이름이 아니라
<name, time>과 같이 된다. - 이러한 시스템에서 객체는 "업데이트"되지 않으며, 추가 정보를 얻기 위해 "진화(evolved)"된다.
- 객체 진화는 새 값을 생성하고, 현재 값(시간)을 추가하는 작업으로 구성된다.
- 이전 값은 사라지지 않고 계속 존재하며, 특정 시간을 지정하는 방식으로 주소를 지정해 찾아낼 수 있다.
- 각 객체는 시간 기록을 갖고 있고, 객체의 주소는 단순한 이름이 아니라
- 이러한 시스템을 "시간 도메인 주소 지정(time-domain addressing)" 또는 "버전 지향 시스템(version-oriented systems)"이라 부른다.
- 어떤 사람들은 이를 불변 객체 시스템(immutable object systems)이라 부르기도 하는데, 나(짐 그레이)는 객체는 시간이 지남에 따라 값이 변화하기 때문에 잘못된 이름이라 생각한다.
Davies and Bjork proposed an implementation for time-domain addressing as a “general ledger” in which each entity had a time sequence of values [Davies], [Bjork]. Their system not only kept these values but also kept the chain of dependencies so that if an error was discovered, the compensating transaction could run and the new value could be propagated to each transaction that depended on the erroneous data. The internal book-keeping and expected poor performance of such a system discouraged most who have looked at it. Graham Wood at the University of Newcastle showed that the dependency information grows exponentially [Wood].
Davies와 Bjork는 time domain addressing의 구현으로 각 엔티티가 값의 시간 시퀀스를 갖는 "일반 원장(general ledger)" 방식을 제안했다.
- 이 방식은 단순히 값을 보관하고 있을 뿐만 아니라 의존성이 있는 연결구조(chain of dependencies)를 유지한다.
- 이렇게 하면 오류가 발견되면 보상 트랜잭션이 실행될 수 있고, 오류 데이터에 의존하는 각각의 트랜잭션에 새 값을 전파할 수 있다.
- 그러나 이러한 시스템의 내부 부기와 예상된 성능 저하는 실망스러웠음.
- Newcastle 대학의 Graham Wood는 이 방식을 사용하면 의존성 정보가 기하 급수적으로 증가한다는 것을 보였다.
Dave Reed has made the most complete proposal for a transaction system based on time-domain addressing [Reed]. In Reed’s proposal an entity E has a set of values Vi each of which is valid for a time period. For example the entity E and its value history might be denoted by:
\[E: < V0, [T0, T1) >, <V1, [T1, T2)>, <V2, [T2,*)>\]meaning that E had value V0 from time T0 up to T1, at time T1 it got value V1 and at time T2 it got value V2 which is the current value. Each transaction is assigned a unique time of execution and all of its reads and writes are interpreted with respect to that time. A transaction at time T3 reading entity E gets the value of the entity at that time. In the example above, if T3>T2 then the value V2 will be made valid for the period [T2,T3). A transaction at time T3 writing value V3 to entity E starts a new time interval:
\[E: <V0, [T0, T1)>, <V1, [T1, T2)>,<V2, [T2, T3)>,<V3, [T3,*)>\]If T2 > = T3 then the transaction is aborted because it is attempting to rewrite history.
Dave Reed는 time-domain addressing 방식에 기반한 트랜잭션 시스템에 대한 가장 완벽한 제안을 했다.
- Reed의 제안에서 엔티티
E는 일정 기간 동안 유효한 값Vi의 집합을 갖고 있다. - 예를 들어 엔티티
E와 그 값의 히스토리는 다음과 같이 표현할 수 있다.
E의 의미는 다음과 같다.
- 시간
T0부터T1까지E는V0값을 갖는다. - 시간
T1부터T2까지E는V1값을 갖는다. - 시간
T2부터E는V2값을 가지며, 이것이 현재 값이다.
각 트랜잭션에는 고유한 실행시간이 할당되고, 모든 읽기/쓰기는 해당 시간과 관련하여 해석된다.
- 엔티티
E를 읽을 때 시간이T3라면 그 트랜잭션은 해당하는 시간의 엔티티의 값을 얻게 될 것이다. - 위의 예에서
T3 > T2이면,V2값은[T2, T3)기간 동안 유효하게 된다. - 시간
T3일 때 값V3를 엔티티E에 쓰는 트랜잭션은 새로운 시간 간격(time interval)을 시작하는 것이다.
만약 \(T2 \ge T3\) 이면, 이 트랜잭션은 취소된다. 과거 히스토리를 덮어쓰는 것이 되기 때문이다.
The writes of the transaction all depend upon a commit record. At transaction commit, the system validates (makes valid) all of the updates of the transaction. At transaction abort the system invalidates all of the updates. This is done by setting the state of the commit record to commit or abort and then broadcasting the transaction outcome.
This is a simplified description of Reed’s proposal. The full proposal has many other features including a nested transaction mechanism. In addition, Reed does not use “real” time but rather “pseudo-time” in order to avoid the difficulties of implementing a global clock. See [Reed2] and Svobodova] for very understandable presentations of this proposal.
트랜잭션 쓰기는 커밋 레코드에 따라 달라진다.
- 트랜잭션을 커밋하면, 시스템은 트랜잭션의 모든 업데이트의 유효성을 검사한다.
- 트랜잭션을 중단(abort)하면, 시스템은 업데이트를 무효화한다.
- 커밋 또는 중단 둘 중 하나의 결과가 나오면 트랜잭션 결과를 브로드캐스팅한다.
이것이 바로 Reed의 제안을 간단히 설명한 것이다.
- 전체 설명에는 중첩 트랜잭션(nested transaction)을 포함해 다른 여러 기능들이 들어 있다.
- Reed는 글로벌한 시계 구현의 어려움을 회피하기 위해 "실제 시간"이 아니라 "의사 시간"을 사용한다.
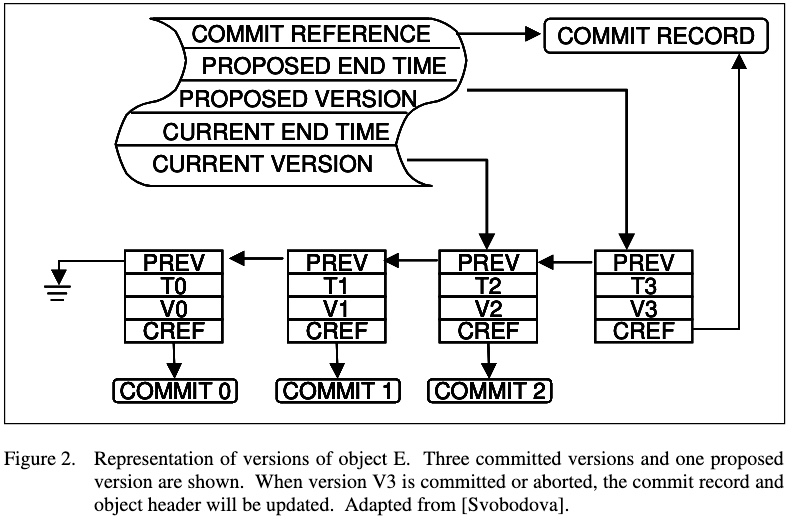
그림 2. 객체 E의 여러 버전들을 표현한 그림. 세 개의 커밋된 버전(committed version)과 하나의 요청된 버전(proposed version)이 그림에 나타나 있다. V3 버전이 커밋되거나 중단되면 커밋 레코드와 객체 헤더가 업데이트된다.
Reed observes that this proposal is a unified solution to both the concurrency control problem and the reliability problem. In addition, the system allows applications the full power of time- domain addressing. One can easily ask questions such as “What did the books look like at year-end?”
Reed는 이 방법이 동시성 제어 문제와 안전성 문제 모두에 대한 통합 솔루션이라는 것을 확인한다.
- 그리고 이 시스템은 애플리케이션으로 하여금 time-domain addressing의 모든 기능을 사용할 수 있게 해준다.
- "작년 말에 회계 장부가 어떻게 구성되어 있었습니까?" 같은 질문을 쉽게 할 수 있게 된다.
There are some problems with time-domain addressing proposals:
- Reads are writes: reads advance the clock on an object and therefore update its header. This may increase L/O activity.
- Waits are aborts: In most cases a locking system will cause conflicts to result in one process waiting for another. In time-domain systems, conflicts abort the writer. This may preclude long-running “batch” transactions which do many updates.
- Timestamps force a single granularity: reading a million records updates a million timestamps. A simple lock hierarchy allows sequential (whole file) and direct (single record) locking against the same data (at the same time).
- Real operations and pseudo-time: If one reads or writes a real device, it is read at some real time or written at some real time (consider the rods of a nuclear reactor, or an automated teller machine which consumes and dispenses money). It is unclear how real time correlates with pseudo-time and how writes to real devices are modeled as versions.
As you can see from this list, not all the details of implementing a time-domain addressing system have been worked out. Certainly the concept is valid. All but the last issue are performance issues and may well be solved by people trying to build such systems. Many people are enthusiastic about this approach, and they will certainly find ways to eliminate or ameliorate these problems. In particular, Dave Reed and his colleagues at MIT are building such a system [Svobodova].
time-domain addressing에는 다음과 같은 단점들도 있다.
- 읽기를 할 때 쓰기가 발생한다: 읽는 행위가 객체의 시계를 앞당기므로 객체의 헤더가 업데이트된다. 이렇게 하면 L/O 활동이 증가할 수 있다.
- 대기를 통한 중단: 대부분의 경우 잠금 시스템을 사용하면 충돌이 발생하게 되고, 하나의 프로세스가 다른 프로세스를 기다리게 된다. 시간 도메인 시스템에서 충돌이 발생하면 기록기를 중단시키게 된다. 이로 인해 많은 업데이트를 수행하는 오랜 시간 동안 돌아가는 "배치" 트랜잭션을 금지해야 할 수도 있다.
- 타임스탬프는 단일 세분화를 강제한다: 백만 개의 레코드를 읽으면 백만 개의 타임스탬프가 업데이트된다. 단순 잠금 계층은 동일한 데이터에 대해 순차적(전체 파일) 또는 직접(단일 레코드) 잠금을 동시에 허용한다.
- 실제 작업과 의사 시간: 실제 장치를 사용해 읽거나 쓰게 되면 실시간으로 읽고 기록하게 된다(원자로, 현금 자동 입출금기). 실시간과 의사 시간의 상관 관계 및 실제 장치에 대한 쓰기가 버전으로 모델링되는 방법은 명백하지 않다.
위의 목록에서 볼 수 있듯이, time-domain addressing 시스템 구현에 대한 모든 세부 사항이 해결된 것은 아니다. 이 개념은 유효하며, 마지막 문제를 제외한 모든 문제는 성능 문제이기 때문에 이런 시스템을 구축하려는 사람들이 해결하게 될 수도 있다. MIT와 Dave Reed와 동료들은 그런 시스템을 구축하려 노력하고 있다.
LOGGING AND LOCKING: Another solution
또 다른 방법: 로깅과 잠금
Logging and locking are an alternative implementation of the transaction concept. The legendary Greeks, Ariadne and Theseus, invented logging. Ariadne gave Theseus a magic ball of string which he unraveled as he searched the Labyrinth for the Minotaur. Having slain the Minotaur, Theseus followed the string back to the entrance rather then remaining lost in the Labyrinth. This string was his log allowing him to undo the process of entering the Labyrinth. But the Minotaur was not a protected object so its death was not undone by Theseus' exit.
Hansel and Gretel copied Theseus’ trick as they wandered into the woods in search of berries. They left behind a trail of crumbs that would allow them to retrace their steps by following the trail backwards, and would allow their parents to find them by following the trail forwards. This was the first undo and redo log. Unfortunately, a bird ate the crumbs and caused the first log failure.
로깅과 잠금은 트랜잭션 개념의 대안적인 구현이다.
- 로깅(logging)은 그리스 신화에 나오는 아리아드네와 테세우스가 발명한 것이다.
- 아리아드네는 미궁에서 미노타우로스를 찾기 위해 미궁을 탐색하려던 테세우스에게 마법의 실뭉치 공을 주었다.
- 미노타우로스를 죽인 테세우스는 미궁 안에서 길을 잃은 상태가 되었지만, 실을 따라 입구로 돌아갈 수 있었다.
- 즉, 실은 테세우스가 미궁에 들어간 과정을 취소할 수 있게끔 한 기록(log)이었던 것이다.
- 물론 미노타우로스는 프로텍티드 객체(protected object)가 아니었기 때문에 죽음이 취소되지는 않았다.
헨젤과 그레텔은 딸기를 찾아 숲 속을 헤매게 되었을 때 테세우스의 방법을 모방했다.
- 헨젤과 그레텔은 빵 조각을 바닥에 흘렸으므로, 그 흔적을 따라 되돌아갈 수 있었다.
- 따라서 헨젤과 그레텔의 부모가 흔적을 따라 가면서 그들을 찾아낼 수 있게 했다.
- 이 방법은 최초의 실행 취소(undo)와 재실행(redo) 로그였던 것이다.
- 안타깝게도 그들이 흘린 빵조각은 새들이 먹었고, 최초의 로그 실패(log failure) 사례가 되었다.
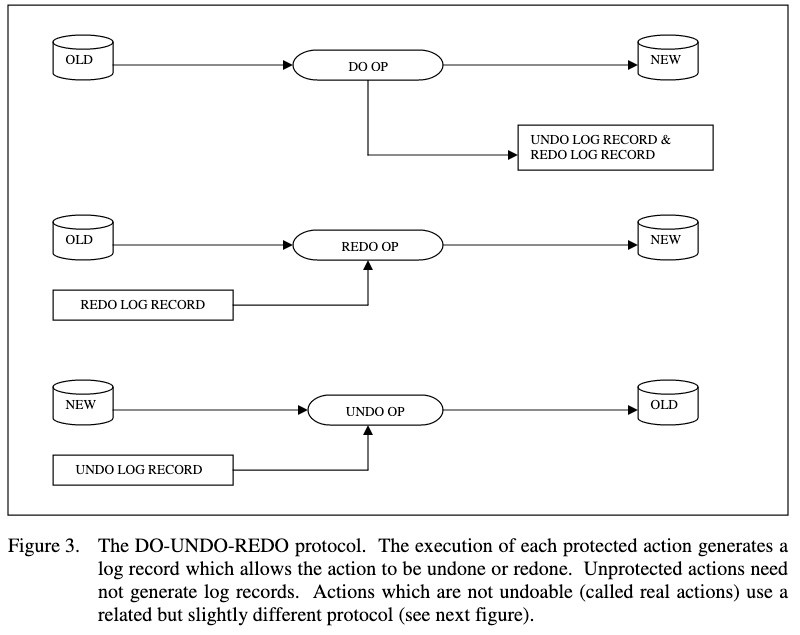
그림 3. DO-UNDO-REDO 프로토콜.
- 각각의 protected 작업을 실행하면 로그 레코드가 생성되며, 이 로그를 사용해 작업을 취소하거나 다시 실행할 수 있게 된다.
- 보호되지 않은 작업은 로그 레코드를 생성하지 않아도 된다.
- 실행취소할 수 없는 작업(real action)은 이와 관계있지만 조금 다른 프로토콜을 사용한다(다음 그림을 볼 것).
The basic idea of logging is that every undoable action must not only do the action but must also leave behind a string, crumb or undo log record which allows the operation to be undone. Similarly, every redoable action must not only do the operation but must also generate a redo log record which allows the operations to be redone. Based on Hansel and Gretel’s experience, these log records should be made out of strong stuff (not something a bird would eat). In computer terms, the records should be kept in stable storage – usually implemented by keeping the records on several non-volatile devices, each with independent failure modes. Occasionally, a stable copy of each object should be recorded so that the current state may be reconstructed from the old state.
로깅의 기본적인 아이디어는, 모든 실행 취소 가능한 작업이 작업을 수행할 뿐만 아니라 작업을 실행취소할 수 있게끔 하는 실, 빵 조각, 또는 실행 취소 로그 레코드를 남겨야 한다는 것이다.
- 마찬가지로 모든 재실행 가능한 작업은 작업을 수행할 뿐만 아니라 작업을 재실행할 수 있게 해주는 재실행 로그 레코드도 생성해야 한다.
- 헨젤과 그레텔의 경험을 토대로, 이러한 로그 기록은 새들이 날아와 먹을 수 없는 튼튼한 재료로 만들어야 한다.
- 컴퓨터 측면에서 이러한 레코드는 안정적인 저장소에 보관되어야 한다.
- 일반적으로는 각각 독립적인 장애 모드(independent failure modes)를 가진 여러 개의 비 휘발성 장치(non-volatile devices)에 레코드를 보관하는 방식으로 구현한다.
- 때때로, 각 객체의 안정적인 사본을 기록해야 할 필요도 있다. 이를 통해 현재 상태가 이전 상태에서 재구성될 수 있도록 한다.
The log records for database operations are very simple. They have the form:
- NAME OF TRANSACTION:
- PREVIOUS LOG RECORD OF THIS TRANSACTION:
- NEXT LOG RECORD OF THIS TRANSACATION:
- TIME:
- TYPE OF OPERATION:
- OBJECT OF OPERATION:
- OLD VALUE:
- NEW VALUE:
DB 작업을 위한 로그 레코드는 매우 단순하다. 다음과 같은 형태를 갖는다.
- NAME OF TRANSACTION:
- PREVIOUS LOG RECORD OF THIS TRANSACTION:
- NEXT LOG RECORD OF THIS TRANSACATION:
- TIME:
- TYPE OF OPERATION:
- OBJECT OF OPERATION:
- OLD VALUE:
- NEW VALUE:
The old and new values can be complete copies of the object, but more typically they just encode the changed parts of the object. For example, an update of a field of a record of a file generally records the names of the file, record and field along with the old and new field values rather than logging the old and new values of the entire file or entire record.
old 값과 new 값은 객체의 완전한 복사본일 수 있지만, 일반적으로는 객체의 변경된 부분만 인코딩한다. 예를 들어, 파일 레코드의 필드 업데이트는 일반적으로 전체 파일이나 전체 레코드의 이전 값/새 값을 전부 로깅하지 않고, 그 대신 이전 및 새 필드 값과 함께 파일, 레코드 및 필드의 이름만 기록한다.
The log records of a transaction are threaded together. In order to undo a transaction, one undoes each action is its log. This technique may be used both for transaction abort issued by the program and for cleaning up after incomplete (uncommitted) transactions in case of a system problem such as deadlock or hardware failure.
In the event that the current state of an object is lost, one may reconstruct the current state from an old state in stable storage by using the redo log to redo all recent committed actions on the old state.
Some actions need not generate log records. Actions on unprotected objects (e.g. writing on a scratch file), and actions which do not change the object state (e.g. reads of the object) need not generate log records.
트랜잭션의 로그 레코드는 함께 스레드된다. 그러므로 하나의 트랜잭션을 실행 취소하면, 각각의 실행 취소도 해당 트랜잭션의 로그가 된다. 이 기법은 프로그램에 의해 실행된 트랜잭션 중단과 교착 상태 또는 하드웨어 오류와 같은 시스템 문제와 같은 불완전한(커밋되지 않은) 트랜잭션 후처리에 모두 사용할 수 있다.
객체의 현재 상태가 손상되는 일이 발생하면, redo 로그를 사용해 이전 상태에 대해 최근 커밋된 모든 작업을 재실행하는 방법으로 스테이블 저장소의 이전 상태에서 현재 상태를 재구성할 수 있다.
일부 작업은 로그 레코드를 생성할 필요가 없기도 하다. 예를 들어 보호되지 않는 객체에 대한 작업(스크래치 파일에 쓰기 등)이나 객체 상태를 변경하지 않는 작업(객체 읽기)과 같은 경우는 로그 레코드를 생성할 필요가 없다.
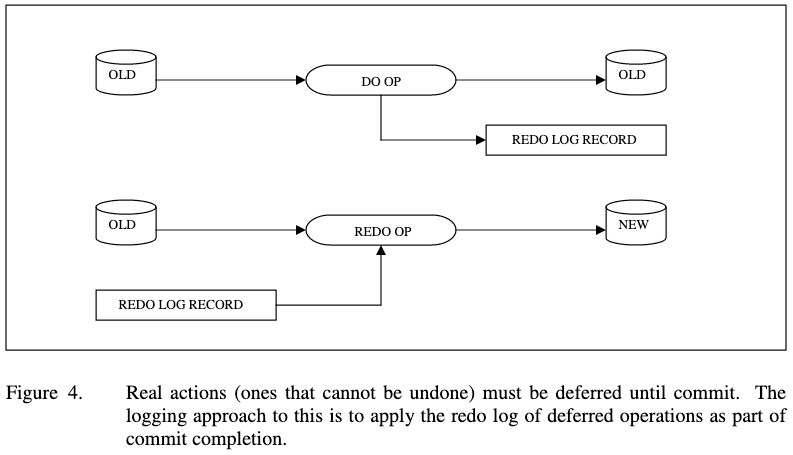
그림 4. 실제 작업(실행 취소할 수 없는 작업)은 커밋할 때까지 연기해야 한다. 로깅으로 이 방식을 구현하려면 지연 작업의 redo 로그를 적용하는 것을 커밋 완료 작업에 포함시킨다.
On the other hand, some actions must initially only generate log records which will be applied at transaction commit. A real action which cannot be undone must be deferred until transaction commit. In a log-based system, such actions are deferred by keeping a redo log of deferred operations. When the transaction successfully commits, the recovery system uses this log to do the deferred actions for the first time. These actions are named (for example by sequence number) so that duplicates are discarded and hence the actions are restartable (see below).
반면에 어떤 작업은 처음부터 로그 레코드만 생성해서 트랜잭션을 커밋할 때 적용하도록 한다.
- real 작업은 취소할 수 없으므로 트랜잭션이 커밋될 때까지 미뤄둬야 한다.
- 로그 기반 시스템에서는 이렇게 미뤄두는 작업의 redo 로그를 유지한다.
- 트랜잭션이 성공적으로 커밋까지 도달하면, 복구 시스템은 이 로그를 사용해서 지연됐던 작업을 수행한다.
- 이러한 작업들은 이름(예: 시퀀스 번호)을 지정해 중복을 방지하며, 따라서 작업을 재시작하는 것도 가능하다(아래 글 참고).
Another detail is that the undo and redo operations must be restartable, that is if the operation is already undone or redone, the operation should not damage or change the object state. The need for restartability comes from the need to deal with failures during undo and redo processing. Restartability is usually accomplished with version numbers (for disc pages) and with sequence numbers (for virtual circuits or sessions). Essentially, the undo or redo operation reads the version or sequence number and does nothing if it is the desired number. Otherwise it transforms the object and the sequence number.
또 다른 세부 사항은 실행 취소(undo) 및 다시 실행 작업(redo)을 다시 시작할 수 있어야 한다는 것이다.
- 즉, 작업이 이미 실행 취소되었거나(undone) 다시 실행된 경우(redone) 작업이 객체 상태를 손상 시키거나 변경해서는 안된다는 것.
- '재시작 가능(restartability)'은 실행 취소 및 재실행 처리 중 오류를 처리해야할 수 있기 때문에 필요하다.
- 재시작 가능(restartability)은 일반적으로 버전 번호(디스크 페이지용)와 시퀀스 번호(가상 회로 또는 세션용)를 사용하여 수행된다.
- 실행 취소(undo) 또는 다시 실행(redo) 작업은 버전이나 시퀀스 번호를 읽은 다음, 원하는 시퀀스 번호라면 아무 작업도 수행하지 않는다.
- 그렇지 않으면(시퀀스 번호가 다르면) 객체와 시퀀스 번호를 변경한다.
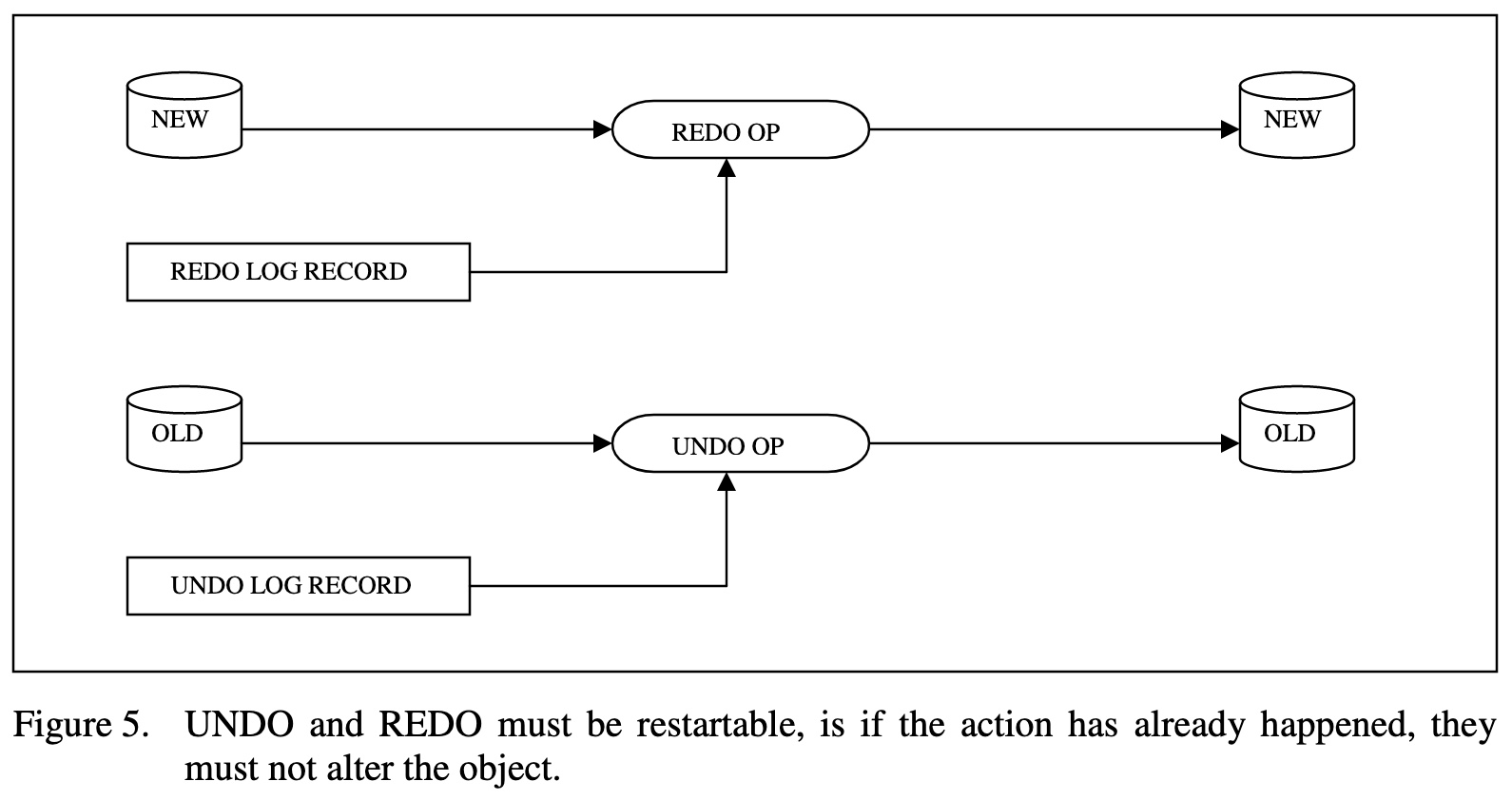
그림 5. UNDO 와 REDO 는 restartable 해야 하며, 작업이 이미 시작된 상태라면 객체를 변경해서는 안된다.
In a log-based scheme, transaction commit is signaled by writing the commit record to the log. If the transaction has contributed to multiple logs then one must be careful to assure that the commit appears either in all logs or in none of the logs. Multiple logs frequently arise in distributed systems since there are generally one or more logs per node. They also arise in central systems.
로그 기반 체계에서, 트랜잭션 커밋은 로그에 커밋 레코드를 기록하여 신호를 보낸다.
- 만약 해당 트랜잭션이 여러 개의 로그에 기여했다면 다음을 주의해야 한다.
- 커밋이 모든 로그에 나타나게 된다.
- 커밋이 어느 로그에도 나타나지 않는다.
- 이런 멀티 로그 현상은 분산 시스템에서 자주 발생한다.
- 노드마다 하나 이상의 로그를 갖고 있기 때문이다.
- 물론 중앙 집중식 시스템에서도 발생할 수 있다.
The simplest strategy to make commit an atomic action is to allow only the active node of the transaction to decide to commit or abort (all other participants are slaves and look to the active node for the commit or abort decision). Rosenkranz, Sterns and Lewis describe such a scheme [Rosenkranz].
Rosenkranz, Sterns, Lewis의 체계.
- 커밋을 원자적 액션으로 만드는 가장 단순한 전략은,
- 트랜잭션의 활성 노드만 커밋 또는 중단(abort)을 결정하도록 허용하는 것이다.
- (참가하고 있는 다른 모든 노드는 slave이며 커밋이나 중단 결정을 위해 액티브 노드를 본다)
It is generally desirable to allow each participant in a transaction to unilaterally abort the transaction prior to the commit. If this happens, all other participants must also abort. The two-phase commit protocol is intended to minimize the time during which a node is not allowed to unilaterally abort a transaction. It is very similar to the wedding ceremony in which the minister asks “Do you?” and the participants say “I do” (or “No way!”) and then the minister says “I now pronounce you”, or “The deal is off”. At commit, the two-phase commit protocol gets agreement from each participant that the transaction is prepared to commit. The participant abdicates the right to unilaterally abort once it says “I do” to the prepare request. If all agree to commit, then the commit coordinator broadcasts the commit message. If unanimous consent is not achieved, the transaction aborts. Many variations on this protocol are known (and probably many more will be published).
- 일반적으로 트랜잭션의 각 참가자가 커밋 전에 트랜잭션을 일방적으로 중단(abort)할 수 있도록 허용하는 것이 바람직하다.
- 이런 중단이 발생하면 다른 모든 참가자도 중단해야 한다.
- 2단계 커밋 프로토콜은 노드가 트랜잭션을 일방적으로 중단할 수 없는 시간을 최소화하기 위한 것이다.
- 결혼식을 진행하는 목사가 "당신도 동의합니까?"라고 질문하는 것과 매우 비슷하다.
- 참가자들은 질문에 대해 "동의합니다"(또는 "아니오!")라고 대답하고, 목사는 "지금부터 두 사람이 부부가 되었음을 선언합니다" 또는 "결혼이 취소되었습니다"라고 말한다.
- 2단계 커밋 프로토골은 커밋을 할 때 각각의 참가자들에게 트랜잭션을 커밋할 준비가 되었다는 동의를 받는다.
- 참가자가 준비 요청에 "동의합니다"라고 대답하면 일방적으로 중단(abort)할 수 있는 권리를 포기하게 된다.
- 모두가 커밋에 동의하면 진행자가 커밋 메시지를 브로드캐스팅한다.
- 만약 만장일치로 동의하지 않게 된다면 트랜잭션은 중단(abort)된다.
- 이 프로토콜에 대해 알려진 변형이 많이 있다.
If transactions run concurrently, one transaction might read the outputs (updates or messages) of another transaction. If the first transaction aborts, then undoing it requires undoing the updates or messages read by the second transaction. This in turn requires undoing the second transaction. But the second transaction may have already committed and so cannot be undone. To prevent this dilemma, real and protected updates (undoable updates) of a transaction must be hidden from other transactions until the transaction commits. To assure that reading two related records, or rereading the same record, will give consistent results, one must also stabilize records which a transaction reads and keep them constant until the transaction commits. Otherwise a transaction could reread a record and get two different answers [Eswaran].
만약 여러 트랜잭션이 동시에 실행된다면, 한 트랜잭션이 다른 트랜잭션의 업데이트 결과나 메시지 같은 출력(outputs)을 읽을 수 있다.
- 첫 번째 트랜잭션을 중단하는 경우 undo를 하려면 두번째 트랜잭션에서 읽은 업데이트나 메시지를 undo 해야 한다.
- 그러면 두 번째 트랜잭션을 undo 해야 한다.
- 그러나 두번째 트랜잭션이 이미 커밋된 경우엔 undo를 할 수 없다.
- 이런 딜레마를 방지하려면 트랜잭션이 커밋될 때까지 트랜잭션의 real 과 protected 업데이트(undo 가능한 업데이트들)를 다른 트랜잭션에게서 숨겨야 한다.
- 두 개의 서로 관계 있는 레코드를 읽거나, 하나의 레코드를 다시 읽는 것이 일관된 결과를 제공하도록 보장하려면 트랜잭션이 읽는 레코드를 안정화하고(stabilize), 트랜잭션이 커밋될 때까지 유지해야 한다.
- 그렇지 않으면 트랜잭션이 레코드를 다시 읽고 두 가지 다른 결과를 얻을 수 있다.
There appear to be many ways of achieving this input stability and hiding outputs. They all seem to boil down to the following ideas:
- A transaction has a set of inputs "I".
- A transaction has a set of outputs "O".
- Other transactions may read "I" but must not read or write "O".
이러한 입력 안정성을 달성하고 출력을 숨기는 방법은 여러 가지가 있는데, 모두 다음과 같은 아이디어로 요약할 수 있다.
- 하나의 트랜잭션은 입력 집합 "I"를 갖는다.
- 하나의 트랜잭션은 출력 집합 "O"를 갖는다.
- 다른 트랜잭션은 "I"는 읽을 수 있지만, "O"는 읽거나 쓰면 안된다.
Some schemes try to guess the input and output sets in advance and do set intersection (or predicate intersection) at transaction scheduling time to decide whether this transaction might conflict with some already executing transactions. In such cases, initiation of the new transaction is delayed until it does not conflict with any running transaction. IMS/360 seems to have been the first to try this scheme, and it has been widely rediscovered. It has not been very successful. IMS abandoned predeclaration (called “intent scheduling”) in 1973 [Obermarck].
어떤 체계는 입력 및 출력 집합을 미리 추측하고 트랜잭션 스케쥴링 시간에 교집합(intersection)을 설정하여 이 트랜잭션이 이미 실행중인 다른 일부 트랜잭션과 충돌할 수 있는지를 결정한다.
- 이런 경우, 새 트랜잭션의 시작은 실행중인 트랜잭션과 충돌하지 않을 때까지 지연한다.
- IMS/360은 이 방식을 처음 시작한 체계로 보이며, 널리 재발견되었지만 그닥 성공적이지는 않았다.
- IMS는 1973년에 이 미리 추측하는 방식("의도 스케쥴링(intent scheduling)")을 포기했다.
A simpler and more efficient scheme is to lock an object when it is accessed. This technique dynamically computes the I and O sets of the transaction. If the object is already locked, then the requestor waits. Multiple readers can be accommodated by distinguishing two lock modes: one indicating update access and another indicating read access. Read locks are compatible while update locks are not.
심플하면서도 더 효율적인 방법은 객체에 액세스할 때 객체를 잠그는(lock) 것이다.
- 이 기법은 트랜잭션의 I 세트와 O 세트를 동적으로 계산한다.
- 객체에 이미 잠금이 걸려 있으면 요청자는 대기하면 된다.
- 두 개의 잠금 모델을 사용하면 여러 읽기 요청자를 수용할 수 있다.
- 업데이트 엑세스를 나타내는 잠금 모드
- 읽기 엑세스를 나타내는 잠금 모드
- 읽기 잠금은 호환(compatible)되지만 업데이트 잠금은 호환되지 않는다.
An important generalization is to allow locks at multiple granularities. Some transactions want to lock thousands of records while others only want to lock just a few. A solution is to allow transactions to issue a lock as a single predicate which covers exactly the records they want locked. Testing for lock conflict involves evaluation or testing membership in such predicates [Eswaran]. This is generally expensive. A compromise is to pick a fixed set of predicates, organize them into a directed acyclic graph and lock from root to leaf. This is a compromise between generality and efficiency [Gray1].
중요한 일반화는 여러 세분성(multiple granularities)에서 잠금을 허용하는 것이다.
- 어떤 트랜잭션은 수 천개의 레코드를 잠그려 하고, 어떤 트랜잭션은 몇 개의 레코드만 잠그려 한다.
- 해결책은 트랜잭션이 잠금을 원하는 레코드를 정확히 포함하는 단일 술어(predicate)로 잠금을 발행하도록 허용하는 것이다.
- 잠금 충돌 테스트에는 이러한 술어들의 멤버쉽 평가나 테스트가 포함된다.
- 이것은 일반적으로 비싼 연산이다.
- 타협점은 고정된 술어 세트를 선택하여, 방향성 비순환 그래프로 구성하고, 루트에서 리프까지 잠금을 거는 것이다.
- 이 방법이 일반적인 사용과 효율성 사이의 절충안이라 할 수 있다.
If a transaction T waits for a transaction T’ which is waiting for T, both transactions will be stalled forever in deadlock. Deadlock is rare, but it must be dealt with. Deadlock must be detected (by timeout or by looking for cycles in the who-waits-for-whom graph), a set of victims must be selected and they must be aborted (using the log) and their locks freed [Gray1], [Beeri]. In practice, waits seem to be rare (one transaction in 1000 [Beeri]) and dead locks seem to be miracles. But it appears that deadlocks per second rise as the square of the degree of multiprogramming and as the fourth power of transaction size [Gray3], indicating that deadlocks may be a problem in the future as we see large transactions or many concurrent transactions.
만약 트랜잭션 T가 트랜잭션 T' 을 기다리고 있는데, T'도 T를 기다리고 있다면 두 트랜잭션은 데드락에 빠져 영원히 멈추게 된다.
- 데드락은 드물게 발생하지만 반드시 처리해야 한다.
- 데드락은 반드시 감지해야 한다(타임아웃 또는 who-waits-for-whom 그래프에서 주기를 검색하는 방식으로).
- 데드락의 희생자 집합을 선택하고 로그를 사용해 중단(abort)하고, 잠금을 해제해야 한다.
- 실제로는 대기 자체가 드물기 때문에(트랜잭션 1000번 중 한번 꼴), 데드락이 발생하는 건 거의 기적으로 보인다.
- 그러나 초당 데드락 발생 건수는 멀티 프로그래밍 정도의 제곱과 트랜잭션 크기의 4제곱에 비례해 증가하는 것으로 보인다.
- 대규모 트랜잭션이나 많은 수의 동시성 트랜잭션을 생각해 보면 데드락이 향후 미래에 문제가 될 수 있음을 알 수 있다.
SUMMARY
The previous sections discussed apparently different approaches to implementing the transaction concept: time-domain addressing and logging. It was pointed out that to make log operations restartable, the object or object fragments are tagged with version numbers. Hence, most logging schemes contain a form of time-domain addressing.
- 앞의 섹션에서는 트랜잭션 개념을 구현하는 방법들 중 시간 도메인 주소 지정과 로깅에 대해 설명했다.
- 로그 작업을 다시 시작할 수 있도록 하기 위해 객체 또는 객체 조각에 버전 번호 태그가 지정된다는 점이 포인트였다.
- 대부분의 로깅 체계에는 시간 도메인 주소 지정 형식이 포함된다.
If each log record is given a time stamp, then a log can implement time-domain addressing. If Gretel had written a time on each crumb, then we could find out where they were at a certain time by following the crumbs until the desired time interval was encountered. Logging systems write the old value out to the log and so do not really discard old values. Rather, the log is a time-domain addressable version of the state and the disk contains the current version of the state.
각각의 로그 레코드에 타임 스탬프가 주어지면 로그는 시간 도메인 주소 지정 방법을 구현할 수 있다.
- 만약 그레텔이 빵 부스러기에 시간을 기록했다고 하자.
- 그랬다면 원하는 시간에 도달할 때까지 빵 부스러기를 따라가면서 헨젤과 그레텔이 어떤 시간에 어디에 있었는지를 알아낼 수 있다.
- 로깅 시스템은 이전 값을 로그에 기록하므로 실제로 이전 값을 버리지 않는다.
- 오히려 로그는 시간 도메인 주소 지정이 가능한 상태 버전이며 디스크에는 현재 버전의 상태가 포함된다.
Time-domain addressing schemes "garbage collect" old versions into something that looks very much like a log and they use locks to serialize the update of the object headers [Svobodova].
시간 도메인 주소 지정 체계는 이전 버전을 "garbage collect"하여 로그와 매우 유사한 것으로 만들고, 잠금을 사용해 객체 헤더 업데이트를 직렬화한다.
I conclude from this that despite the external differences between time domain addressing and logging schemes, they are more similar than different in their internal structure. There appear to be difficulties in implementing time-domain addressing. Arguing by analogy, Dave Reed asserts that every locking and logging trick has an analogous trick for time-domain addressing. If this is true, both schemes are viable implementations of transactions.
나는 이를 통해 시간 도메인 주소 지정과 로깅 체계 사이의 외부적인 차이에도 불구하고 두 방식의 내부 구조가 유사하다는 결론을 내린다.
시간 도메인 주소 지정은 구현이 어려운 것으로 보인다.
Dave Reed는 모든 잠금 및 로깅 트릭이 시간 도메인 주소 지정과 유사한 트릭을 가지고 있다고 주장한다. 이 주장이 사실이라면, 두 방식 모두 트랜잭션 개념의 실행 가능한 구현이다.
LIMITATIONS OF KNOWN TECHNIQUES
알려진 기법들의 한계점들
The transaction concept was adopted to ease the programming of certain applications. Indeed, the transaction concept is very effective in areas such as airline reservations, electronic funds transfer or car rental. But each of these applications has simple transactions of short duration. I see the following difficulties with current transaction models:
- Transactions cannot be nested inside transactions.
- Transactions are assumed to last minutes rather than weeks.
- Transactions are not unified with programming language.
트랜잭션 개념은 특정 애플리케이션의 프로그래밍을 쉽게 하기 위해서 채택된 것이다.
실제로 트랜잭션 개념은 항공편 예약, 전자적 자금 이체, 또는 자동차 렌탈과 같은 영역에서 매우 효과적이다. 이러한 애플리케이션들은 모두 짧은 시간 단위의 간단한 트랜잭션을 갖는다.
트랜잭션 모델에는 다음과 같은 어려운 점들이 있다.
- 트랜잭션은 트랜잭션 내부에 중첩될 수 없다.
- 트랜잭션은 몇 주(weeks) 단위가 아니라 몇 분 단위로 간주된다.
- 트랜잭션은 프로그래밍 언어와 통합되지 않는다.
NESTED TRANSACTIONS
중첩된 트랜잭션
Consider implementing a travel agent system. A transaction in such a system consists of:
- Customer calls the travel agent giving destination and travel dates.
- Agent negotiates with airlines for flights.
- Agent negotiates with car rental companies for cars.
- Agent negotiates with hotels for rooms.
- Agent receives tickets and reservations.
- Agent gives customer tickets and gets credit card number.
- Agent bills credit card.
- Customer uses tickets.
Not infrequently, the customer cancels the trip and the agent must undo the transaction.
여행사 시스템을 구현한다고 생각해 보자. 이 시스템의 트랜잭션은 다음 사항들로 구성될 것이다.
- 고객이 여행사 에이전트에 전화해서 여행 목적지와 여행 날짜를 이야기한다.
- 에이전트는 항공편에 대해 항공사와 협상한다.
- 에이전트는 렌터카에 대해 자동차 렌탈 회사와 협상한다.
- 에이전트는 객실에 대해 호텔 직원과 협협상한다.
- 에이전트가 각 티켓과 각 예약을 수령한다.
- 에이전트는 고객에게 신용 카드 번호를 받고, 고객에게 티켓들을 넘겨준다.
- 에이전트는 신용 카드로 청구한다.
- 고객은 티켓을 사용한다.
만약 고객이 여행을 취소하면 상담원도 거래(transaction)를 취소해야 한다.
The transaction concept as described thus far crumbles under this example. Each interaction with other organizations is a transaction with that organization. It is an atomic, consistent, durable transformation. The agent cannot unilaterally abort an interaction after it completes, rather the agent must run a compensating transaction to reverse the previous transaction (e.g., cancel reservation). The customer thinks of this whole scenario as a single transaction. The agent views the fine structure of the scenario, treating each step as an action. The airlines and hotels see only individual actions but view them as transactions. This example makes it clear that actions may be transactions at the next lower level of abstraction.
지금까지 설명해왔던 트랜잭션 개념은 이 예제에서 무너진다. 다른 조직과의 각각의 상호작용(interaction)은 해당 조직과의 트랜잭션이라 할 수 있다. 이는 원자적이고(atomic), 일관성이 있고(consistent), 지속적인(durable) 변환이다.
에이전트는 어떤 상호작용이 완료된 후에는 해당 상호작용을 일방적으로 중단할 수 없다. 어쩔 수 없이 에이전트는 보상 트랜잭션을 실행하는 방식으로 이전 트랜잭션을 되돌려야 한다(예: 예약 취소).
한편, 고객은 이 전체 시나리오를 하나의 거래로만 생각하고 있다.
에이전트는 시나리오의 세부 사항을 알고 있으며, 각각의 단계를 해야 할 행동으로 취급한다.
항공사와 호텔의 경우는 개별적인 액션만 알고 있지만, 그 액션을 트랜잭션으로 생각한다.
이 여행사 예제는 어떤 작업들은 낮은 수준의 추상화 레벨에서 트랜잭션이 될 수 있다는 점을 보여준다.
An approach to this problem that seems to offer some help is to view a transaction as a collection of:
- Actions on unprotected objects.
- Protected actions which may be undone or redone.
- Real actions which may be deferred but not undone.
- Nested transactions which may be undone by invoking compensating transaction.
트랜잭션을 다음 항목들의 집합으로 보는 것은 이 문제에 대해 도움이 될만한 접근 방식이라 할 수 있다.
- Unprotected 객체에 대한 작업.
- 실행 취소하거나 재시도 가능한 Protected 작업.
- 연기할 수 있지만 취소할 수는 없는 Real 작업.
- 보상 트랜잭션을 호출하는 방식으로 작업을 되돌릴 수 있는 중첩 트랜잭션.
Nested transactions differ from protected actions because their effects are visible to the outside world prior to the commit of the parent transaction.
중첩된 트랜잭션은 protected 작업과는 다른 것인데, 부모 트랜잭션이 커밋되기 전에 그 효과가 외부세계에 표시되기 때문이다.
When a nested transaction is run, it returns as a side effect the name and parameters of the compensating transaction for the nested transaction. This information is kept in a log of the parent transaction and is invoked if the parent is undone. This log needs to be user-visible (part of the database) so that the user and application can know what has been done and what needs to be done or undone. In most applications, a transaction already has a compensating transaction so generating the compensating transaction (either coding it or invoking it) is not a major programming burden. If all else fails, the compensating transaction might just send a human the message “Help, I can’t handle this”.
중첩된 트랜잭션이 실행되면, 중첩된 트랜잭션에 대한 보상 트랜잭션의 이름과 매개 변수가 사이드 이펙트를 통해 반환된다. 이 정보는 상위 트랜잭션의 로그에 보관되며, 상위 트랜잭션이 실행 취소될 때 호출된다. 이 로그는 데이터베이스의 일부로서 사용자가 볼 수 있어야 하며, 이를 통해 사용자와 애플리케이션은 어떤 작업이 완료되었고 어떤 작업이 완료/취소되어야 하는지를 알 수 있어야 한다.
대부분의 애플리케이션에서의 트랜잭션은 이미 보상 트랜잭션 기능이 같이 있을 것이므로 보상 트랜잭션을 생성(코딩하거나 호출하거나)하는 것은 그리 대단한 프로그래밍적인 부담은 아니다.
만약 모든 방법이 실패하게 되었을 때 담당자에게 "도와주세요. 이거 어떻게 처리해야 할지 모르겠어요."라는 메시지를 보내는 것도 보상 트랜잭션이라 할 수 있다.
This may not seem very satisfying, but it is better than the entirely manual process that is in common use today. At least in this proposal, the recovery system keeps track of what the transaction has done and what must be done to undo it.
이건 그닥 만족스러운 방법은 아니지만, 오늘날 일반적으로 사용되는 완전한 수동 프로세스보다는 낫다. 적어도 이 제안에서 복구 시스템은 트랜잭션이 수행한 작업과, 이 작업을 실행 취소하기 위해 수행해야 하는 작업을 추적하며 보관하고 있기 때문이다.
At present, application programmers implement such applications using a technique called a “scratchpad” (in IMS) and a “transaction work area” in CICS. The application programmer keeps the transaction state (his own log) as a record in the database. Each time the transaction becomes active, it reads its scratchpad. This re-establishes the transaction state. The transaction either advances and inserts the new scratchpad in the database or aborts and uses the scratchpad as a log of things to undo. In this instance, the application programmer is implementing nested transactions. It is a general facility that should be included in the host transaction management system.
오늘날의 애플리케이션 프로그래머들은 "scratchpad"(in IMS)와 "transaction work area"라고 부르는 기술들을 사용해서 이러한 애플리케이션을 구현한다.
일단, 애플리케이션 프로그래머는 트랜잭션 상태(자신의 로그)를 데이터베이스에 기록으로 남긴다. 그리고 트랜잭션이 활성화될 때마다 스크래치 패드를 읽는데, 이렇게 하면 트랜잭션 상태가 다시 설정된다. 트랜잭션은 데이터베이스에 새 스크래치 패드를 진행/삽입/중단하는데, 스크래치 패드를 실행 취소할 작업의 로그로 사용하기 때문이다. 이 방식을 통해 애플리케이션 프로그래머는 중첩 트랜잭션을 구현할 수 있는데, 이는 호스트 트랜잭션 관리 시스템에 포함되어야 하는 일반적인 기능이다.
Some argue that nested transactions are not transactions. They do have some of the transaction properties:
- Consistent transformation of the state.
- Either all actions commit or are undone by compensation.
- Once committed, cannot be undone.
They use the BEGIN, COMMIT and ABORT verbs. But they do not have the property of atomicity. Others can see the uncommitted updates of nested transactions. These updates may subsequently be undone by compensation.
트랜잭션의 다음 속성들을 이유로 중첩 트랜잭션이 트랜잭션이 아니라는 의견도 있다.
- 상태의 일관성 있는 변형.
- 모든 액션은 커밋되거나 보상을 통해 취소된다.
- 일단 커밋되면 취소할 수 없다.
중첩 트랜잭션들은 BEGIN, COMMIT, ABORT라는 동사를 사용하지만, 원자성을 갖고 있지 않은 것이다.
그리고 누군가가 중첩 트랜잭션의 커밋되지 않은 업데이트를 보는 것도 가능하다.
물론 이런 업데이트는 보상 트랜잭션을 통해 취소될 수 있다.
LONG-LIVED TRANSACTIONS
장기간 지속되는 트랜잭션
A second problem with the travel agent example is that transactions are suddenly long-lived. At present, the largest airlines and banks have about 10,000 terminals and about 100 active transactions at any instant. These transactions live for a second or two and are gone forever. Now suppose that transactions with lifetimes of a few days or weeks appear. This is not uncommon in applications such as travel, insurance, government, and electronic mail. There will be thousands of concurrent transactions. At least in database applications, the frequency of deadlock goes up with the square of the multiprogramming level and the fourth power of the transaction size [Gray3]. You might think this is a good argument against locking and for time-domain addressing, but time-domain addressing has the same problem.
여행사 예제의 두 번째 문제는 트랜잭션이 갑자기 오래 걸리게 될 수도 있다는 것이다.
현재 가장 큰 규모의 항공사나 은행들은 약 10,000 개의 터미널과 약 100 개의 활성화된 트랜잭션을 순간순간 처리하고 있다. 이러한 트랜잭션들은 해봐야 1~2초 정도 지속될 뿐이다.
그런데 라이프타임이 며칠이나 몇 주나 되는 트랜잭션이 나타났다고 생각해 보자. 이런 트랜잭션은 수천개의 동시 트랜잭션이 발생할 수 있는 여행, 보험, 정부기관, 전자 우편과 같은 애플리케이션에서는 드문 일이 아니다.
데이터베이스 애플리케이션에서 데드락의 빈도는 멀티 프로그래밍 수준의 제곱과 트랜잭션 크기의 4제곱에 비례하여 증가한다.
이것이 잠금 방식을 반대하고 시간 도메인 주소 지정을 지지할만한 좋은 주장이라고 생각할 수 있겠지만, 시간 도메인 주소 지정에도 동일한 문제가 있다.
Again, the solution I see to this problem is to accept a lower degree of consistency [Gray2] so that only “active” transactions (ones currently in the process of making changes to the database) hold locks. “Sleeping” transactions (travel arrangements not currently making any updates) will not hold any locks. This will mean that the updates of uncommitted transactions are visible to other transactions. This in turn means that the UNDO and REDO operations of one transaction will have to commute with the DO operations of others. (i.e. if transaction T1 updates entity E and then T2 updates entity E and then T1 aborts, the update of T2 should not be undone). If some object is only manipulated with additions and subtractions, and if the log records the delta rather than the old and new value, then UNDO and REDO, may be made to commute with DO. IMS Fast Path uses the fact that plus and minus commute to reduce lock contention. No one knows how far this trick can be generalized.
다시 말하지만, 나는 이 문제에 대한 해결책은 "Active" 트랜잭션(현재 데이터베이스를 변경하고 있는 트랜잭션)만 잠금을 유지하도록 낮은 수준의 일관성을 허용하는 것이라 생각한다.
그리고 "Sleeping" 트랜잭션(현재 업데이트가 없는 여행 준비)은 잠금을 유지하지 않는다.
이는 커밋되지 않은 트랜잭션의 업데이트가 다른 트랜잭션에 드러나게 된다는 것을 의미한다.
이것은 한 트랜잭션의 UNDO 및 REDO 작업이 다른 트랜잭션의 DO 작업과 교환될 수 있어야 한다는 것을 의미한다.
(가령 트랜잭션 T1 이 엔티티 E를 업데이트를 마친 다음, T2가 엔티티 E를 업데이트했다고 하자. 그리고 이 때 T1이 취소된다면, T2의 업데이트는 취소할 수 없어야 한다.)
만약 일부 객체가 덧셈과 뺄셈으로만 변경되고,
로그가 이전 값과 새로운 값이 아니라 델타 값을 기록하고 있다면,
UNDO와 REDO가 DO와 교환되도록 만들 수 있다.
IMS Fast Path는 덧셈 및 뺄셈 교환을 통해 잠금 경합을 줄이는데, 이 트릭이 얼마나 일반화될 수 있는지는 아무도 모른다.
A minor problem with long-running transactions is that current systems tend to abort them at system restart. When only 100 transactions are active and people are waiting at terminals to resubmit them, this is conceivable (but not nice). When 10,000 transactions are lost at system restart, then the old approach of discarding them all at restart is inconceivable. Active transactions may be salvaged across system restarts by using transaction save points: a transaction declares a save point and the transaction (program and data) is reset to its most recent save point in the event of a system restart.
장기 실행 트랜잭션의 사소한 문제 하나는 시스템이 재시작될 때 트랜잭션을 중단하는 경향이 있다는 것이다.
만약 100개의 트랜잭션이 활성화되어 있는데, 사람들이 그 트랜잭션들을 다시 등록하기 위해 터미널 앞에서 줄을 서서 기다리고 있는 상황도 생각해볼 수는 있다(그러나 좋은 상황은 아니군요).
시스템을 재시작할 때 10,000 개의 트랜잭션이 손실된다고 생각해 보면, 재시작할 때 트랜잭션을 모두 버리는 예전 방법은 고려할 수 없다.
활성 트랜잭션은 트랜잭션 세이브 포인트를 사용하여 시스템 재시작시 복구할 수 있다. 트랜잭션은 세이브 포인트를 선언하고, 시스템이 재시작되면 트랜잭션(프로그램과 데이터)은 가장 최근의 세이브 포인트로 재설정되는 것이다.
INTEGRATION WITH PROGRAMMING LANGUAGES
프로그래밍 언어와의 통합
How should the transaction concept be reflected in programming languages? The proposal I favor is providing the verbs BEGIN, SAVE, COMMIT and ABORT. Whenever a new object type and its operations are defined, the protected operations on that type must generate undo and redo log records as well as acquiring locks if the object is shared. The type manager must provide UNDO and REDO procedures which will accept the log records and reconstruct the old and new version of object. If the operation is real, then the operation must be deferred and the log manager must invoke the type manager to actually do the operation at commit time. If the operation is a nested transaction, the operation must put the name of the compensating transaction and the input to the compensating transaction in the undo log. In addition, the type manager must participate in system checkpoint and restart or have some other approach to handling system failures and media failures.
트랜잭션 개념은 프로그래밍 언어에 어떻게 반영되어야 할까?
내가 제안하고 싶은 방법은 BEGIN, SAVE, COMMIT, ABORT라는 동사들을 지원하는 것이다.
새로운 객체 유형과 그 객체에 대한 작업이 정의될 때마다, 그 객체에 대한 protected 작업은 undo와 redo 로그 레코드를 생성하고, 객체가 공유된 상태라면 잠금을 획득해야 한다.
타입 관리자는 로그 레코드를 허용하고 이전 버전과 새 버전의 객체를 재구성할 수 있는 UNDO, REDO 프로시저를 반드시 제공해야 한다.
만약 작업이 real 이라면 작업을 연기해야 하고, 로그 관리자는 커밋 시간에만 실제 작업을 수행하기 위해 타입 관리자를 호출해야 한다.
만약 중첩된 트랜잭션인 경우, 작업은 보상 트랜잭션의 이름과 보상 트랜잭션에 주어지는 입력을 undo 로그에 넣어야 한다.
또한, 타입 관리자는 시스템 체크포인트와 재시작에 참여해야 한다. 그렇지 않으면 시스템 오류나 미디어 오류를 처리하는 다른 기법을 갖고 있어야 한다.
I’m not sure that this idea will work in the general case and whether the concept of transaction does actually generalize to non-EDP areas of programming. The performance of logging may be prohibitive. However, the transaction concept has been very convenient in the database area and may be applicable to some parts of programming beyond conventional transaction processing. Brian Randell and his group at Newcastle have a proposal in this area [Randell]. The artificial intelligence languages such as Interlisp support backtracking and an UNDO-REDO facility. Barbara Liskov has been exploring the idea of adding transactions to the language Clu and may well discover a new approach.
이 아이디어가 일반적인 경우에 효과가 있을지, 그리고 트랜잭션 개념이 실제로 non-EDP 프로그래밍 영역으로 일반화되는지는 확실하지 않다. 로깅에 필요한 성능이 엄청날 수 있기 때문이다.
그러나 트랜잭션 개념은 데이터베이스 영역에서 매우 편리하여, 평범한 기존의 트랜잭션 처리를 넘어서는 기능이 필요한 프로그래밍의 일부 영역에 적용될 수 있다.
Brian Randell과 그의 그룹은 이 분야에 대해 제안을 한 바 있다.
그리고 Interlisp와 같은 인공지능 언어는 백트랙킹과 UNDO-REDO 기능을 지원한다.
Barbara Liskov는 Clu 언어에 트랜잭션을 추가하는 아이디어를 연구하고 있으며, 이 연구에서 새로운 접근방식을 발견할 수 있다.
SUMMARY
Transactions are not a new idea; they go back thousands of years. The idea of a transformation being consistent, atomic and durable is simple and convenient. Many implementation techniques are known and we have practical experience with most of them. However, our concept of transaction and the implementation techniques we have are inadequate to the task of many applications. They cannot handle nested transactions, long-lived transactions and they may not fit well into conventional programming systems.
트랜잭션은 새로운 종류의 아이디어가 아니며, 그 역사는 수천년 전으로 거슬러 올라갈 수 있다.
변경에 대한 일관성, 원자성, 지속성이라는 아이디어는 간단하고 편리하다.
이에 대해 수많은 구현 기술이 알려져 있으며, 우리들은 이 기법들을 실제로 다룬 경험도 갖고 있다.
그러나 우리의 트랜잭션 개념과 그 구현 기법들은 중첩된 트랜잭션과, 수명이 긴 트랜잭션을 처리할 수 없으며, 기존 프로그래밍 시스템에 적합하지 않을 수 있어 많은 애플리케이션 개발 작업에 적용하기에는 부적절하다.
We may be seeing the Peter Principle in operation here: “Every good idea is generalized to its level of inapplicability”. But I believe that the problems I have outlined here (long-lived and nested transactions) must be solved.
"모든 좋은 아이디어는 적용 불가능한 수준에 도달할 때까지 일반화된다"는 피터의 원칙이 여기에서도 작동하는 것을 볼 수 있다. 그러나 여기에서 설명한 문제(수명이 긴 트랜잭션과 중첩 트랜잭션)는 반드시 해결해야 한다고 나는 생각한다.
I am optimistic that the transaction concept provides a convenient abstraction for structuring applications. People implementing such applications are confronted with these problems and have adopted expedient solutions. One contribution of this paper is to abstract these problems and to sketch generalizations of techniques in common use which address the problems. I expect that these general techniques will allow both long-lived and nested transactions.
나는 트랜잭션이라는 개념이 애플리케이션 구조화를 위해 편리한 추상화를 제공한다고 생각한다. 이런 애플리케이션을 구현하는 사람들은 이미 이런 문제들을 직면해왔고, 적절한 해결책들을 적용해왔다. 이 페이퍼는 그러한 문제를 추상화하고 문제를 해결하는 일반적인 사용 기술의 일반화를 스케치하는 것이라 할 수 있다. 나는 이런 일반적인 기술들이 장기 트랜잭션과 중첩 트랜잭션을 모두 허용할 것으로 기대한다.
ACKNOWLEDGEMENTS
감사 인사
This paper owes an obvious debt to the referenced authors. In addition, the treatment of nested and long-lived transactions grows from discussions with Andrea Borr, Bob Good, Jerry Held, Pete Homan, Bruce Lindsay, Ron Obermarck and Franco Putzolu. Wendy Bartlett, Andrea Borr, Dave Gifford and Paul McJones made several contributions to the presentation.
이 논문은 본문에 인용한 저자분들에게 명백한 빚을 지고 있습니다. 또한, 중첩 트랜잭션과 장기 트랜잭션 처리에 대한 내용은 Andrea Borr, Bob Good, Jerry Held, Pete Homan, Bruce Lindsay, Ron Obermarck, Franco Putzolu 와의 토론에서 발전했습니다. Wendy Bartlett, Andrea Borr, Dave Gifford, Paul McJones는 발표에 많은 기여를 해 주셨습니다.
REFERENCES
생략.
참고문헌
- The Transaction Concept: Virtues and Limitations by Jim Gray 1981