CAP Twelve Years Later - How the "Rules" Have Changed By Eric Brewer
CAP 정리 발표 후 12년 - '규칙'은 어떻게 변했는가
- 원문: CAP Twelve Years Later: How the "Rules" Have Changed
- 2000년에 CAP 정리를 발표한 Eric Brewer가 2012년에 쓴 글. Computer 매거진에 처음으로 게재되었다.
- Eric Brewer는 버클리 컴퓨터 과학 교수이자, Google의 인프라스트럭처 부사장이다.
CAP Twelve Years Later: How the "Rules" Have Changed 번역
The CAP theorem asserts that any networked shared-data system can have only two of three desirable properties. However, by explicitly handling partitions, designers can optimize consistency and availability, thereby achieving some trade-off of all three.
In the decade since its introduction, designers and researchers have used (and sometimes abused) the CAP theorem as a reason to explore a wide variety of novel distributed systems. The NoSQL movement also has applied it as an argument against traditional databases.
The CAP theorem states that any networked shared-data system can have at most two of three desirable properties:
- consistency (C) equivalent to having a single up-to-date copy of the data;
- high availability (A) of that data (for updates); and
- tolerance to network partitions (P).
CAP 정리는 네트워크로 연결된 공유 데이터 시스템이 세 가지 바람직한 속성 중에서 오직 두 가지만 가질 수 있다고 주장합니다. 그러나 시스템 설계자는 파티션을 명시적으로 취급함으로써 일관성과 가용성을 최적화할 수 있고, 3가지 속성의 타협점을 찾을 수 있습니다.
CAP 정리를 세상에 발표한 이후 10년이 흘렀습니다. 그 동안 설계자들과 연구자들은 CAP 정리를 다양한 새로운 분산 시스템을 탐구하는 근거로 사용했으며, 어떤 경우에는 남용하기도 했습니다. 또한 NoSQL을 선호하는 진영에서는 전통적인 데이터베이스에 대항하는 근거로 CAP 정리를 적용했습니다.
CAP 정리에 따르면, 네트워크로 연결된 공유 데이터 시스템은 다음의 3가지 바람직한 특성 중 최대 2가지만 가질 수 있습니다.
- 데이터의 최신 복사본을 하나만 가지는 것과 동일한 수준의 일관성(C)
- 데이터(업데이트)에 대한 높은 가용성(A)
- 네트워크 파티션에 대한 장애 허용(P)
This expression of CAP served its purpose, which was to open the minds of designers to a wider range of systems and tradeoffs; indeed, in the past decade, a vast range of new systems has emerged, as well as much debate on the relative merits of consistency and availability. The "2 of 3" formulation was always misleading because it tended to oversimplify the tensions among properties. Now such nuances matter. CAP prohibits only a tiny part of the design space: perfect availability and consistency in the presence of partitions, which are rare.
CAP이 전달하려하는 바는 설계자들이 더 넓은 범위의 시스템과 타협점을 고려할 수 있게 해 준 데에 의의가 있습니다. 실제로 지난 10년 동안 다양한 새로운 시스템들이 등장했으며, 일관성과 가용성의 상대적 장점을 저울질하는 많은 논쟁이 이루어졌습니다.
"3가지 중 2가지" 공식은 항상 오해의 소지가 있었습니다. 왜냐하면 이 공식은 세 속성들 사이의 팽팽한 긴장을 과도하게 단순화하는 경향이 있었기 때문입니다.
이제는 이런 미묘한 차이가 중요해졌습니다. CAP은 설계 영역의 극히 일부분, 즉 '파티션이 있는 경우의 완벽한 가용성과 일관성'만을 금지합니다.
Although designers still need to choose between consistency and availability when partitions are present, there is an incredible range of flexibility for handling partitions and recovering from them. The modern CAP goal should be to maximize combinations of consistency and availability that make sense for the specific application. Such an approach incorporates plans for operation during a partition and for recovery afterward, thus helping designers think about CAP beyond its historically perceived limitations.
파티션을 전제하는 경우라면 설계자들은 여전히 일관성과 가용성 사이에서 선택을 해야 합니다. 그러나 파티션을 다루고 복구하는 방법들은 놀라울 정도로 다양합니다.
CAP의 현대적인 목표는 특정 애플리케이션에 적합한 '일관성과 가용성의 조합'을 극대화하는 것입니다.
이러한 접근 방식은 파티션이 가동하는 동안의 운영 계획과 그 이후의 복구 계획을 통합하여, 설계자들이 역사적으로 인식된 한계를 넘어 CAP에 대해 생각할 수 있게 도와줍니다.
Why "2 of 3" is missleading
왜 "3가지 중 2가지"는 오해의 소지가 있는가?
The easiest way to understand CAP is to think of two nodes on opposite sides of a partition. Allowing at least one node to update state will cause the nodes to become inconsistent, thus forfeiting C. Likewise, if the choice is to preserve consistency, one side of the partition must act as if it is unavailable, thus forfeiting A. Only when nodes communicate is it possible to preserve both consistency and availability, thereby forfeiting P. The general belief is that for wide-area systems, designers cannot forfeit P and therefore have a difficult choice between C and A. In some sense, the NoSQL movement is about creating choices that focus on availability first and consistency second; databases that adhere to ACID properties (atomicity, consistency, isolation, and durability) do the opposite. The "ACID, BASE, and CAP" sidebar explains this difference in more detail.
CAP을 이해하는 가장 쉬운 방법은 파티셔닝으로 생성된 두 개의 노드를 생각해보는 것입니다. 하나 이상의 노드가 상태를 업데이트할 수 있게 해주면, 노드들 사이에 불일치가 발생해 '일관성'(C)을 달성하지 못하게 됩니다. 이와 비슷하게, 이번에는 '일관성'을 유지하는 선택을 한다면 둘 중 한쪽은 사용 못하는 것처럼 작동해야 하므로, '가용성'(A)을 잃게 됩니다. 이런 노드들이 서로 통신하고 있는 동안에만 '일관성'과 '가용성'을 모두 달성할 수 있는데, 이렇게 하면 '파티션 장애 허용'(P)을 달성하지 못하게 됩니다.
일반적으로 광역 시스템의 경우라면 설계자들은 P를 포기할 수 없습니다. 그래서 C와 A 사이에서 어려운 선택을 해야 합니다. 어떤 면에서, NoSQL 운동은 가용성을 최우선으로 하고 일관성을 두번째 기준으로 삼는 전략에 대한 것이기도 합니다. ACID 속성(원자성, 일관성, 격리성, 지속성)을 준수하는 데이터베이스는 이런 방향과는 정반대의 전략을 취합니다. "ACID, BASE, 그리고 CAP" 섹션에서 이 차이점에 대해 좀 더 자세히 설명하겠습니다.
In fact, this exact discussion led to the CAP theorem. In the mid-1990s, my colleagues and I were building a variety of cluster-based wide-area systems (essentially early cloud computing), including search engines, proxy caches, and content distribution systems. [1] Because of both revenue goals and contract specifications, system availability was at a premium, so we found ourselves regularly choosing to optimize availability through strategies such as employing caches or logging updates for later reconciliation. Although these strategies did increase availability, the gain came at the cost of decreased consistency.
사실 바로 이 논의가 CAP 정리로 이어지게 된 것입니다.
1990년대 중반에 나는 동료들과 함께 클러스터 기반의 광역 시스템(사실상 초기 클라우드 컴퓨팅)을 구축하고 있었습니다. 여기에는 검색 엔진, 프록시 캐시, 컨텐츠 배포 시스템 등이 포함돼 있었습니다. 매출 목표와 계약된 스펙 때문에 시스템 가용성이 매우 중요했기 때문에, 캐시를 사용하거나 나중에 조정할 용도의 업데이트 로깅 등의 전략을 써서 가용성을 최적화하려 노력했습니다. 그런데 이런 전략들이 가용성을 높여주긴 했지만, 일관성이 떨어지는 대가를 치러야 했습니다.
The first version of this consistency-versus-availability argument appeared as ACID versus BASE,[2] which was not well received at the time, primarily because people love the ACID properties and are hesitant to give them up. The CAP theorem’s aim was to justify the need to explore a wider design space-hence the "2 of 3" formulation. The theorem first appeared in fall 1998. It was published in 1999 [3] and in the keynote address at the 2000 Symposium on Principles of Distributed Computing,[4] which led to its proof.
이러한 '일관성 vs 가용성' 논쟁의 첫 번째 버전은 'ACID vs BASE'1로 나타났습니다. 당시에는 이런 관점이 잘 받아들여지지 않았는데 많은 사람들이 ACID 속성을 선호해서 포기하기를 꺼려했기 때문입니다.
CAP 정리의 목적은 더 넓은 설계 영역을 탐구할 이유를 제공하는 것이었고, 그에 따라 "3가지 중 2가지" 공식이 등장했습니다. 이 정리는 1998년 가을에 처음 등장해서 1999년에 발표되었고, 2000년에 있었던 분산 컴퓨팅 원리에 대한 심포지엄 기조 연설로 소개됐으며 이후 증명까지 이어졌습니다.
As the "CAP Confusion" sidebar explains, the "2 of 3" view is misleading on several fronts. First, because partitions are rare, there is little reason to forfeit C or A when the system is not partitioned. Second, the choice between C and A can occur many times within the same system at very fine granularity; not only can subsystems make different choices, but the choice can change according to the operation or even the specific data or user involved. Finally, all three properties are more continuous than binary. Availability is obviously continuous from 0 to 100 percent, but there are also many levels of consistency, and even partitions have nuances, including disagreement within the system about whether a partition exists.
"CAP 혼란" 섹션에서 설명하겠지만, "3가지 중 2가지"라는 관점은 여러 가지 측면에서 오해받기 쉽습니다.
- 첫째, 파티션은 드문 현상이기 때문에 시스템이 파티션되지 않은 경우라면 일관성(C)이나 가용성(A)을 포기할 이유가 거의 없습니다.
- 둘째, 같은 시스템 내에서도 매우 세밀한 수준에서 일관성(C), 가용성(A) 중 하나를 여러 차례 선택할 수 있습니다.
- 그리고 하위 시스템마다 다른 선택을 할 수도 있고 작업, 특정 데이터, 사용자에 따라서도 이 선택은 변경될 수 있습니다.
- 마지막으로, 세 가지 속성 모두 on/off 가 아니라 연속적인 성질을 갖고 있습니다.
- 가용성의 경우에는 명백히 0% 에서 100% 사이의 연속적인 값을 갖지만,
- 일관성에도 여러 단계가 있으며,
- 파티션의 세부사항에도 '뉘앙스'가 있습니다. 어떤 것이 파티션이고 어떤 것이 파티션이 아닌지에 대해 시스템 내에서도 의견이 달라질 수 있는 것입니다.
Exploring these nuances requires pushing the traditional way of dealing with partitions, which is the fundamental challenge. Because partitions are rare, CAP should allow perfect C and A most of the time, but when partitions are present or perceived, a strategy that detects partitions and explicitly accounts for them is in order. This strategy should have three steps: detect partitions, enter an explicit partition mode that can limit some operations, and initiate a recovery process to restore consistency and compensate for mistakes made during a partition.
이러한 뉘앙스를 탐구하려면 파티션을 처리하는 전통적인 방법을 밀어버려야 하는데, 이것이 근본적인 과제라 할 수 있습니다.
파티션이 드문 현상이므로, CAP은 대부분의 경우 완벽한 일관성(C)과 가용성(A)을 허용해야 합니다. 그러나 파티션이 존재하거나 인식되고 있는 경우라면 파티션을 감지하고 이를 명시적으로 처리하는 전략이 필요합니다.
이 전략은 3 단계로 이루어져야 합니다.
- 파티션 감지,
- 일부 작업을 제한할 수 있는 명시적인 파티션 모드 전환,
- 복구 프로세스를 시작하여 일관성을 복원하고 파티션 중에 발생한 실수를 보상하는 것입니다.
Acid, base, and cap
ACID, BASE, 그리고 CAP
ACID and BASE represent two design philosophies at opposite ends of the consistency-availability spectrum. The ACID properties focus on consistency and are the traditional approach of databases. My colleagues and I created BASE in the late 1990s to capture the emerging design approaches for high availability and to make explicit both the choice and the spectrum. Modern large-scale wide-area systems, including the cloud, use a mix of both approaches.
ACID와 BASE는 일관성-가용성 스펙트럼의 양 극단에 있는 두 가지 설계 철학을 나타냅니다. ACID 속성은 일관성에 초점을 맞추는 데이터베이스의 전통적인 접근 방식입니다.
나와 동료들은 1990년대 후반에 고가용성을 위한 새로운 설계 접근법을 포착해 '선택'과 '스펙트럼'을 명확히 표현하기 위해 BASE를 만들었습니다. 클라우드를 포함하는 현대적인 대규모 광역 시스템들은 모두 이러한 두 가지 접근법을 혼합해서 사용합니다.
Although both terms are more mnemonic than precise, the BASE acronym (being second) is a bit more awkward: Basically Available, Soft state, Eventually consistent. Soft state and eventual consistency are techniques that work well in the presence of partitions and thus promote availability.
두 용어 모두 정확한 의미를 담는 건 아니고 기억하기 쉽게 만든 축약어에 가깝습니다. 특히 BASE는 기본적으로(B) 가용하고(A) 소프트 상태(S)를 가지며, 최종 일관성(E)을 갖는다는 의미인데, 축약어로는 ACID보다 BASE가 좀 더 어색한 편입니다.
소프트 상태와 최종 일관성은 파티션이 있는 경우에 잘 작동하여 가용성을 높여주는 기술입니다.
The relationship between CAP and ACID is more complex and often misunderstood, in part because the C and A in ACID represent different concepts than the same letters in CAP and in part because choosing availability affects only some of the ACID guarantees. The four ACID properties are:
CAP과 ACID의 관계는 더 복잡하며, 종종 오해를 받기도 합니다. 그 이유는 ACID의 C(일관성), A(원자성)가 CAP의 C(일관성), A(가용성)와 다른 개념을 나타내는데, 가용성을 선택하면 ACID가 보장하는 것들 중 일부만 영향을 받기 때문입니다.
ACID의 네 가지 속성은 다음과 같습니다.
Atomicity (A). All systems benefit from atomic operations. When the focus is availability, both sides of a partition should still use atomic operations. Moreover, higher-level atomic operations (the kind that ACID implies) actually simplify recovery.
원자성(A). 모든 시스템은 원자적 연산을 사용하면 이득을 볼 수 있습니다. 가용성에 중점을 두는 경우라면, 파티션의 양쪽 모두 원자적 연산을 사용해야 합니다. 게다가, 더 높은 수준의 원자적 연산(ACID가 의미하는 종류)은 실제로 복구를 단순화합니다.
Consistency (C). In ACID, the C means that a transaction pre-serves all the database rules, such as unique keys. In contrast, the C in CAP refers only to single-copy consistency, a strict subset of ACID consistency. ACID consistency also cannot be maintained across partitions. partition recovery will need to restore ACID consistency. More generally, maintaining invariants during partitions might be impossible, thus the need for careful thought about which operations to disallow and how to restore invariants during recovery.
일관성(C). ACID의 C는 트랜잭션이 유니크 키와 같은 모든 데이터베이스 규칙을 지키보도록 보장한다는 의미입니다.
반면, CAP에서의 C는 단일 복사본 일관성만을 의미하며, ACID에서 말하는 일관성의 엄격한 하위 집합입니다. 또한 파티션 간에 ACID의 일관성을 유지할 수 없으므로, 파티션 복구를 할 때 ACID 일관성을 복원해야 합니다.
일반적으로, 파티션 중에 불변성을 유지하는 것은 불가능할 수 있으므로, 어떤 작업을 허용하지 않을지와 복구 과정에서 불변성을 어떻게 복원할지에 대한 신중한 고려가 필요합니다.
Isolation (I). Isolation is at the core of the CAP theorem: if the system requires ACID isolation, it can operate on at most one side during a partition. Serializability requires communication in general and thus fails across partitions. Weaker definitions of correctness are viable across partitions via compensation during partition recovery.
격리성(I). 격리성은 CAP 정리의 핵심입니다. 만약 시스템이 ACID 격리성을 요구한다면, 파티션 동안에는 최대 한쪽에서만 작동할 수 있습니다. 직렬화 가능성은 일반적으로 통신을 필요로 하므로, 파티션을 넘나들면 실패하게 됩니다. 파티션 복구 과정에서 보상을 제공하는 방식으로 파티션 간의 정확성에 대한 약한 정의가 가능합니다.
Durability (D). As with atomicity, there is no reason to forfeit durability, although the developer might choose to avoid needing it via soft state (in the style of BASE) due to its expense. A subtle point is that, during partition recovery, it is possible to reverse durable operations that unknowingly violated an invariant during the operation. However, at the time of recovery, given a durable history from both sides, such operations can be detected and corrected. In general, running ACID transactions on each side of a partition makes recovery easier and enables a framework for compensating transactions that can be used for recovery from a partition.
영속성(D). 원자성과 마찬가지로 영속성은 포기할 이유가 없습니다. 그러나 개발자는 비용 때문에 소프트 상태(BASE 스타일)를 사용하여 영속성이 필요하지 않게 할 수도 있습니다. 파티션 복구 과정에서, 파악하지 못 하는 사이에 불변성을 위반한 영속성 작업을 되돌릴 수 있다는 것은 다행스런 일입니다. 복구 시점에서 양쪽에서 얻은 영속성 기록을 통해 이런 작업들을 감지하고 수정할 수 있습니다. 일반적으로, 파티션 양쪽에서 ACID 트랜잭션을 실행하면 복구가 더 쉬워지고, 파티션 복구를 위해 사용할 수 있는 보상 트랜잭션에 대한 프레임워크를 가능하게 합니다.
Cap-latency connection
CAP-지연 연결
In its classic interpretation, the CAP theorem ignores latency, although in practice, latency and partitions are deeply related. Operationally, the essence of CAP takes place during a timeout, a period when the program must make a fundamental decision-the partition decision:
- cancel the operation and thus decrease availability, or
- proceed with the operation and thus risk inconsistency.
고전적인 해석에 따르면, CAP 정리는 지연(latency)을 무시한다고도 합니다. 그러나 실제로는 파티션과 지연은 깊은 관련이 있습니다.
운영의 측면에서 CAP의 본질은 타임아웃(timeout) 동안에 일어납니다. 이 타임아웃 동안에 프로그램은 근본적인 결정, 즉 다음과 같은 파티션 결정을 내리게 됩니다.
- 작업을 취소하여 가용성을 낮춰야 할지, 아니면
- 작업을 계속 진행하여 불일치가 발생하는 위험을 감수할지
Retrying communication to achieve consistency, for example, via Paxos or a two-phase commit, just delays the decision. At some point the program must make the decision; retrying communication indefinitely is in essence choosing C over A.
예를 들어 일관성을 달성하기 위해 Paxos나 2단계 커밋 기법으로 통신을 재시도하면 결정에 시간이 걸리게 됩니다.
어느 시점이건 프로그램이 결정을 내려야만 하는 상황인데, 이럴 때 통신을 무한정 재시도하는 것은 본질적으로 A(가용성)보다 C(일관성)을 선택하는 것입니다.
Thus, pragmatically, a partition is a time bound on communication. Failing to achieve consistency within the time bound implies a partition and thus a choice between C and A for this operation. These concepts capture the core design issue with regard to latency: are two sides moving forward without communication?
따라서 실용적인 관점에서 보면, 파티션의 존재는 통신에 대한 시간 제한을 의미합니다.
시간 제한 내에 일관성을 달성하지 못하면 파티션이 발생합니다. 그러므로 이 작업을 위해 C(일관성)와 A(가용성) 중에서 하나를 선택해야만 합니다.
이러한 개념은 지연 시간과 관련된 핵심적인 설계 문제, 즉 나뉘어진 양쪽은 통신 없이도 진행이 가능한가라는 문제를 포착합니다.
This pragmatic view gives rise to several important consequences. The first is that there is no global notion of a partition, since some nodes might detect a partition, and others might not. The second consequence is that nodes can detect a partition and enter a partition mode-a central part of optimizing C and A.
이러한 실용적인 관점은 몇 가지 중요한 결과를 도출합니다.
- 첫째, 어떤 노드는 파티션을 감지하고 어떤 노드는 감지하지 못할 수 있으므로 파티션에 대한 글로벌 개념이 존재하지 않는다는 것입니다.
- 둘째, 노드가 파티션을 감지하고 파티션 모드로 들어갈 수 있다는 것인데, 이는 C(일관성)와 A(가용성)의 최적화에 중요한 역할을 합니다.
Finally, this view means that designers can set time bounds intentionally according to target response times; systems with tighter bounds will likely enter partition mode more often and at times when the network is merely slow and not actually partitioned.
마지막으로 이 관점은, 설계자가 목표 응답 시간에 따라 의도적으로 시간 제한을 설정할 수 있다는 것을 의미합니다. 더 엄격한 제한을 갖는 시스템은 네트워크가 단지 느릴 뿐이고 실제로 파티션이 아닌 경우에도, 더 자주 파티션 모드로 들어갈 가능성이 높습니다.
Sometimes it makes sense to forfeit strong C to avoid the high latency of maintaining consistency over a wide area. Yahoo’s PNUTS system incurs inconsistency by maintaining remote copies asynchronously. [5] However, it makes the master copy local, which decreases latency. This strategy works well in practice because single user data is naturally partitioned according to the user’s (normal) location. Ideally, each user’s data master is nearby.
지리적으로 넓은 영역에 걸쳐 일관성을 유지하는 데 필요한 높은 지연 시간(high latency)을 피하기 위해 강력한 C(일관성)를 포기하는 것이 합리적일 때도 있습니다.
Yahoo의 PNUTS 시스템은 원격 복사본을 비동기적으로 유지하는 방식으로, 고의로 일관성을 희생한 것입니다. PNUTS는 로컬에 마스터 카피를 만들어 지연 시간을 줄입니다. 이 전략은 한 명의 사용자 데이터가 그 사용자의 (일반적인) 지리적 위치에 따라 자연스럽게 파티셔닝되기 때문에 실제로 잘 작동합니다. 각 사용자의 데이터 마스터가 사용자와 가까운 지역에 있다면 이상적으로 작동할 것입니다.
Facebook uses the opposite strategy:[6] the master copy is always in one location, so a remote user typically has a closer but potentially stale copy. However, when users update their pages, the update goes to the master copy directly as do all the user’s reads for a short time, despite higher latency. After 20 seconds, the user’s traffic reverts to the closer copy, which by that time should reflect the update.
Facebook은 이와는 반대되는 전략을 사용합니다. 마스터 카피는 항상 한 위치에 두고, 보통 지리적으로 더 가깝지만 오래되었을 가능성이 있는 카피본을 원격 사용자가 갖게 됩니다.
그리고 사용자가 자신의 페이지를 업데이트하면 지연 시간이 길어지더라도 짧은 시간 동안 모든 사용자의 읽기가 마스터 카피를 바라보게 됩니다.
20초가 지나면 사용자의 트래픽은 더 가까운 카피본으로 돌아가게 되는데, 그 때까지는 업데이트가 반영되어 있어야 합니다.
Cap confusion
CAP 혼란
Aspects of the CAP theorem are often misunderstood, particularly the scope of availability and consistency, which can lead to undesirable results. If users cannot reach the service at all, there is no choice between C and A except when part of the service runs on the client. This exception, commonly known as disconnected operation or offline mode,[7] is becoming increasingly important. Some HTML5 features-in particular, on-client persistent storage-make disconnected operation easier going forward. These systems normally choose A over C and thus must recover from long partitions.
CAP 정리의 관점은 종종 오해를 불러일으키는데 특히 가용성과 일관성의 범위가 그렇습니다. 그리고 이런 오해로 인해 바람직하지 않은 결과를 초래할 수 있습니다.
만약 사용자들이 서비스에 전혀 접속할 수 없는 상황이라면, 서비스 일부가 클라이언트에서 돌아가는 경우를 제외하고는 C(일관성)와 A(가용성) 사이에서 선택의 여지가 없습니다.
보통 연결이 끊긴 상태(disconnected operation) 또는 오프라인 모드(offline mode)라고 알려져 있는 이 예외는 점점 더 중요해지고 있습니다. 가령 HTML5의 일부 기능, 특히 온 클라이언트 퍼시스턴트 스토리지는 앞으로 이런 연결이 끊긴 상태의 작업을 더 쉽게 만들어줍니다. 이런 시스템들은 보통 C(일관성)보다 A(가용성)를 선택하므로, 긴 파티션으로부터 복구하는 것을 감수해야 합니다.
Scope of consistency reflects the idea that, within some boundary, state is consistent, but outside that boundary all bets are off. For example, within a primary partition, it is possible to ensure complete consistency and availability, while outside the partition, service is not available. Paxos and atomic multicast systems typically match this scenario.[8] In Google, the primary partition usually resides within one datacenter; however, Paxos is used on the wide area to ensure global consensus, as in Chubby,[9] and highly available durable storage, as in Megastore.[10]
일관성의 범위는 어떤 경계 내에서는 상태가 일관을 유지하지만, 그 경계를 넘어선 곳에서는 모든 것이 불확실하다는 개념을 반영합니다.
예를 들어, 주 파티션 내에서는 완전한 일관성과 가용성을 보장할 수 있지만, 파티션 외부에서는 이런 것들을 보장할 수 없습니다.
Paxos와 원자적 멀티캐스트 시스템은 보통 이런 시나리오에 부합합니다. Google에서는 주 파티션은 일반적으로 하나의 데이터센터에 존재하게 하지만, Paxos는 Chubby와 같은 글로벌 합의를 보장하기 위해 넓은 지역에서 사용되기도 하고 Megastor와 같은 고가용성 내구성 스토리지를 위해서도 사용됩니다.
Independent, self-consistent subsets can make forward progress while partitioned, although it is not possible to ensure global invariants. For example, with sharding, in which designers prepartition data across nodes, it is highly likely that each shard can make some progress during a partition. Conversely, if the relevant state is split across a partition or global invariants are necessary, then at best only one side can make progress and at worst no progress is possible.
독립돼있고 자체 일관성을 갖는 하위 집합은 파티션 상태에서도 진행이 가능하지만, 전역 불변성을 보장하지는 못합니다.
예를 들어 노드와 노드 사이에 데이터를 미리 파티셔닝해두는 샤딩(sharding)의 경우, 각 샤드는 파티션 상태에서도 어느 정도 진행이 가능합니다.
하지만 '연관 상태'가 파티션에 걸쳐 분할되어 있거나 전역 불변성이 필요한 경우라면, 최선의 경우에도 한 쪽만 진행이 가능하고 최악의 경우에는 어느쪽도 진행이 불가능하게 됩니다.
Does choosing consistency and availability (CA) as the "2 of 3" make sense? As some researchers correctly point out, exactly what it means to forfeit P is unclear. [11],[12] Can a designer choose not to have partitions? If the choice is CA, and then there is a partition, the choice must revert to C or A. It is best to think about this probabilistically: choosing CA should mean that the probability of a partition is far less than that of other systemic failures, such as disasters or multiple simultaneous faults.
"3개 중 2개"로 일관성과 가용성(CA)을 선택하는 것은 의미가 있을까요? 일부 연구자들이 정확하게 지적했듯이, P를 포기한다는 것이 정확히 무엇을 의미하는지는 명확하지 않습니다.
파티션이 설계자가 선택할 수 있는 문제일까요? 만약 CA를 선택했는데 파티션이 발생한다면, 선택은 C(일관성) 또는 A(가용성) 둘 중 하나를 희생하는 것으로 돌아가야 합니다.
확률을 고려해 생각하는 것이 가장 좋습니다. CA를 선택한다는 것은 파티션이 발생할 확률이 '재해'나 '동시 다발적으로 발생하는 여러 장애'와 같은 다른 시스템 장애보다 훨씬 적다는 것을 의미합니다.
Such a view makes sense because real systems lose both C and A under some sets of faults, so all three properties are a matter of degree. In practice, most groups assume that a datacenter (single site) has no partitions within, and thus design for CA within a single site; such designs, including traditional databases, are the pre-CAP default. However, although partitions are less likely within a datacenter, they are indeed possible, which makes a CA goal problematic. Finally, given the high latency across the wide area, it is relatively common to forfeit perfect consistency across the wide area for better performance.
이런 관점이 의미가 없는 것은 아닙니다. 실제 시스템들은 일부 결함 상황에서 C와 A를 모두 잃기도 하기 때문입니다. 이 세 가지 속성은 모두 정도의 문제인 것입니다.
실제로 대부분의 그룹은 데이터센터(단일 사이트) 내에 파티션이 없다고 가정하고 단일 사이트 내에서 CA를 설계합니다. 이런 설계의 사례로는 전통적인 데이터베이스도 포함되며, 이것이 CAP 정리 등장 이전의 기본 상식이었습니다.
그러나 데이터센터 내에 파티션이 존재할 가능성이 낮다 해도 실제로 파티션이 발생할 수 있기 때문에, CA 목표에 문제가 생길 수 있습니다.
마지막으로, 광역 지역의 높은 지연 시간을 고려해 더 나은 성능을 위해 광역 지역 전체 규모에서의 완벽한 일관성은 포기하는 것이 비교적 일반적인 일입니다.
Another aspect of CAP confusion is the hidden cost of forfeiting consistency, which is the need to know the system’s invariants. The subtle beauty of a consistent system is that the invariants tend to hold even when the designer does not know what they are. Consequently, a wide range of reasonable invariants will work just fine. Conversely, when designers choose A, which requires restoring invariants after a partition, they must be explicit about all the invariants, which is both challenging and prone to error. At the core, this is the same concurrent updates problem that makes multithreading harder than sequential programming.
CAP 혼란의 또 다른 측면은 일관성을 포기하는 데 드는 숨겨진 비용, 즉 시스템의 불변성을 알아야 한다는 것입니다.
일관된 시스템의 교묘한 아름다움은, 설계자가 불변성이 무엇인지도 모르는 경우에도 불변성이 유지되는 경향이 있다는 것입니다. 그러므로 합리적인 범위의 다양한 불변성이 잘 작동하고 있습니다.
하지만 설계자가 '파티션 후 불변성을 복원해야 하는' A(가용성)를 선택하게 되면, 모든 불변값에 대해 명시해야 하는데 이건 꽤나 어렵고 오류가 발생하기 쉬운 것입니다. 이는 순차적 프로그래밍보다 멀티스레딩을 더 어렵게 만드는 동시성(concurrent) 업데이트 문제와 동일한 문제입니다.
Managing partitions
파티션 관리
The challenging case for designers is to mitigate a partition’s effects on consistency and availability. The key idea is to manage partitions very explicitly, including not only detection, but also a specific recovery process and a plan for all of the invariants that might be violated during a partition. This management approach has three steps:
설계자에게 있어 어려운 문제는 파티션이 일관성과 가용성에 미치는 영향을 완화하는 것입니다.
핵심 아이디어는 파티션을 매우 명시적으로 관리하는 것인데, 파티션 감지 뿐만 아니라 특정한 복구 프로세스와 파티션 중에 위반될 수 있는 모든 불변성에 대한 계획도 포함해야 합니다.
이런 관리 방식에는 세 가지 단계가 있습니다.
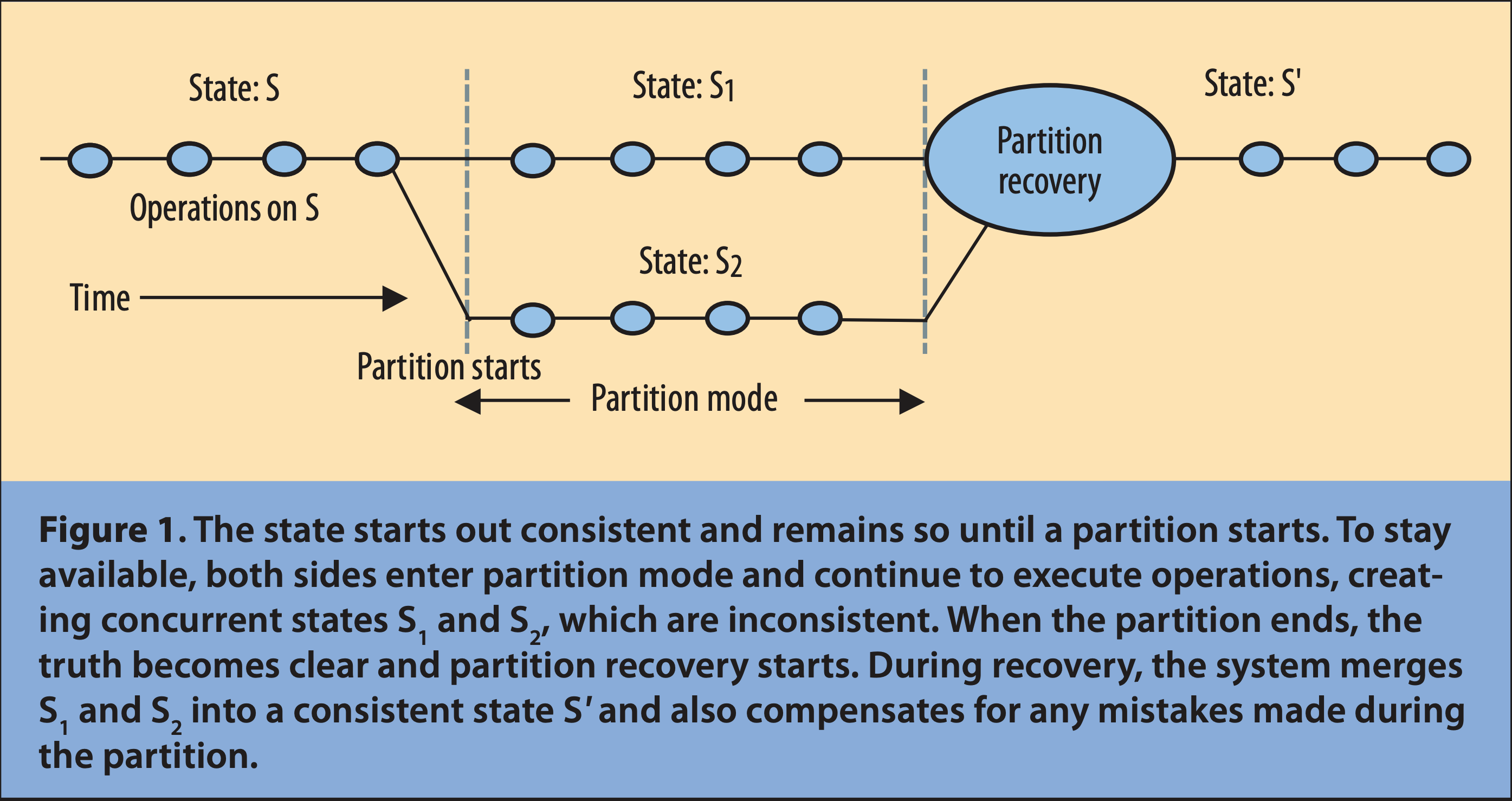
Figure 1. The state starts out consistent and remains so until a partition starts. To stay available, both sides enter partition mode and continue to execute operations, creating concurrent states S1 and S2 , which are inconsistent. When the partition ends, the truth becomes clear and partition recovery starts. During recovery, the system merges S1 and S2 into a consistent state S' and also compensates for any mistakes made during the partition.
Figure 1. 일관성을 유지하는 상태는 파티션이 시작될 때까지 유지됩니다. 가용성을 유지하기 위해 양쪽 모두 파티션 모드로 전환해 작업을 계속 실행하여, 일관성이 없는 동시 상태 S1과 S2가 생성됩니다. 파티션이 종료되면 파티션이 나뉘었던 사실이 드러나, 파티션 복구가 시작됩니다. 복구 중에 시스템은 S1과 S2를 일관된 상태 S'로 병합하고, 파티션 중에 발생한 모든 실수를 보정합니다.
- detect the start of a partition,
- enter an explicit partition mode that may limit some operations, and
- initiate partition recovery when communication is restored.
- 파티션의 발생을 감지합니다.
- 일부 작업을 제한할 수 있는 명시적인 파티션 모드로 전환합니다.
- 통신이 복구되면 파티션 복구를 시작합니다.
The last step aims to restore consistency and compensate for mistakes the program made while the system was partitioned.
마지막 단계는 일관성을 복원하고 시스템이 파티션된 동안 프로그램이 저지른 실수를 보정하는 것을 목표로 합니다.
Figure 1 shows a partition’s evolution. Normal operation is a sequence of atomic operations, and thus partitions always start between operations. Once the system times out, it detects a partition, and the detecting side enters partition mode. If a partition does indeed exist, both sides enter this mode, but one-sided partitions are possible. In such cases, the other side communicates as needed and either this side responds correctly or no communication was required; either way, operations remain consistent. However, because the detecting side could have inconsistent operations, it must enter partition mode. Systems that use a quorum are an example of this one-sided partitioning. One side will have a quorum and can proceed, but the other cannot. Systems that support disconnected operation clearly have a notion of partition mode, as do some atomic multicast systems, such as Java’s JGroups.
Figure 1은 파티션의 진행 과정을 보여줍니다.
일반 작업은 원자적 작업들의 시퀀스이므로, 파티션은 항상 작업과 작업 사이에서 시작됩니다. 일단 시스템 타임아웃이 발생하면, 시스템은 파티션을 감지하고 감지한 쪽이 파티션 모드로 전환합니다. 만약 파티션이 실제로 존재한다면 양쪽 모두 파티션 모드로 전환되지만, 한쪽에서만의 일방적인 파티션도 가능합니다. 이러한 경우에는 다른 쪽에서 필요에 따라 통신을 요청하고 이 쪽에서 올바르게 응답하거나, 아니면 통신이 필요하지 않으므로 어느 쪽이건 작업은 일관성있게 유지됩니다. 그러나 감지한 쪽에서는 일관성이 없는 작업이 있을 수 있으므로, 파티션 모드로 전환해야만 합니다.
쿼럼(quorum)2을 사용하는 시스템이 이러한 일방적인 파티셔닝의 예라 할 수 있습니다. 한쪽은 쿼럼을 가지고 있어서 계속 진행할 수 있지만, 다른 쪽은 진행할 수 없습니다. 연결이 끊긴 작업을 지원하는 시스템에는 분명히 파티션 모드의 개념을 갖고 있습니다. Java의 JGroup과 같은 일부 원자적 멀티캐스팅 시스템도 이와 마찬가지입니다.
Once the system enters partition mode, two strategies are possible. The first is to limit some operations, thereby reducing availability. The second is to record extra information about the operations that will be helpful during partition recovery. Continuing to attempt communication will enable the system to discern when the partition ends.
시스템이 파티션 모드로 전환되면 두 가지 전략이 가능해집니다.
- 첫째, 일부 작업을 제한하여 가용성을 낮추는 것입니다.
- 둘째, 파티션을 복구할 때 도움이 될만한 작업에 대한 추가 정보를 기록하는 것입니다.
계속해서 통신을 시도하면 시스템이 파티션이 종료되는 시점을 파악할 수 있습니다.
Which operations should proceed?
어떤 작업이 계속 진행되어야 하는가?
Deciding which operations to limit depends primarily on the invariants that the system must maintain. Given a set of invariants, the designer must decide whether or not to maintain a particular invariant during partition mode or risk violating it with the intent of restoring it during recovery. For example, for the invariant that keys in a table are unique, designers typically decide to risk that invariant and allow duplicate keys during a partition. Duplicate keys are easy to detect during recovery, and, assuming that they can be merged, the designer can easily restore the invariant.
어떤 작업을 제한해야 하는지 결정하는 것은, 주로 시스템이 유지해야 하는 불변성에 따라 달라집니다. 불변성 집합이 주어지면 설계자는 파티션 모드 중에 특정 불변성을 유지할지, 아니면 복구를 잘 하기 위해 불변성을 위반할 위험을 감수할지를 결정해야 합니다.
예를 들어 테이블의 유니크 키가 고유하다는 불변성의 경우, 일반적으로 설계자들은 이 불변성을 위반하고 파티션 중에 중복 키를 허용하도록 결정합니다. 중복된 키는 복구 중에 쉽게 감지할 수 있기도 하고, 병합할 수도 있다고 가정하면 설계자는 쉽게 불변성을 복구할 수 있습니다.
For an invariant that must be maintained during a partition, however, the designer must prohibit or modify operations that might violate it. (In general, there is no way to tell if the operation will actually violate the invariant, since the state of the other side is not knowable.) Externalized events, such as charging a credit card, often work this way. In this case, the strategy is to record the intent and execute it after the recovery. Such transactions are typically part of a larger workflow that has an explicit order-processing state, and there is little downside to delaying the operation until the partition ends. The designer forfeits A in a way that users do not see. The users know only that they placed an order and that the system will execute it later.
그러나 파티션 중에도 유지되어야 하는 불변성에 대해서는, 설계자는 이를 위반할 수 있는 작업을 금지하거나 수정해야 합니다. (보통은 다른 쪽의 상태를 알 수가 없기 때문에, 작업이 실제로 불변성을 위반하는지 알 수 있는 방법은 없습니다.)
신용카드 결제와 같은 외부 이벤트는 종종 이런 방식으로 작동합니다. 이런 경우에는 의도를 기록하고 복구 후에 실행하는 전략을 사용합니다. 이런 트랜잭션들은 일반적으로 명시적인 주문 처리 상태를 갖는 더 큰 워크플로우의 일부이며, 파티션이 끝날 때까지 작업을 지연시켜도 큰 단점이 없습니다.
설계자는 사용자가 보지 못하는 방식으로 A(가용성)을 포기하는 것입니다. 사용자는 자신이 주문을 했다는 사실과 시스템이 나중에 주문을 처리한다는 사실만 알 수 있습니다.
More generally, partition mode gives rise to a fundamental user-interface challenge, which is to communicate that tasks are in progress but not complete. Researchers have explored this problem in some detail for disconnected operation, which is just a long partition. Bayou’s calendar application, for example, shows potentially inconsistent (tentative) entries in a different color.[13] Such notifications are regularly visible both in workflow applications, such as commerce with e-mail notifications, and in cloud services with an offline mode, such as Google Docs.
좀 더 일반적으로는, 파티션 모드는 '작업이 진행 중이긴 하지만 완료는 안 됐음'을 알려줘야 하는 근본적인 사용자 인터페이스 문제를 야기합니다.
연구자들은 연결이 끊긴 상태에서 발생하는 긴 파티션에 대해서 이 사용자 인터페이스 문제를 상세히 연구해 왔습니다. Bayou의 달력 애플리케이션은 잠재적으로 일관성이 없는 (임시) 항목을 다른 색깔로 표시합니다. 이런 알림들은 이메일 알림이 있는 커머스 같은 워크플로 애플리케이션과, Google 문서 도구와 같은 오프라인 모드를 지원하는 클라우드 서비스에서 모두 표시되곤 합니다.
One reason to focus on explicit atomic operations, rather than just reads and writes, is that it is vastly easier to analyze the impact of higher-level operations on invariants. Essentially, the designer must build a table that looks at the cross product of all operations and all invariants and decide for each entry if that operation could violate the invariant. If so, the designer must decide whether to prohibit, delay, or modify the operation. In practice, these decisions can also depend on the known state, on the arguments, or on both. For example, in systems with a home node for certain data, 5 operations can typically proceed on the home node but not on other nodes.
읽기/쓰기가 아닌 명시적인 원자적 연산에 초점을 맞춰야 하는 이유 중 하나는, 상위 레벨의 작업이 불변성에 미치는 영향을 분석하기 훨씬 쉽기 때문입니다.
설계자는 기본적으로 모든 연산과 모든 불변성을 교차해서 볼 수 있는 테이블을 만들고, 각 항목에 대해 해당 연산이 불변성을 위반하는지 아닌지에 대해 판단해야 합니다. 그리고 그런 것이 있다면, 설계자는 해당 연산을 금지할지, 지연시킬지, 수정할지를 결정해야 합니다. 실제로 이런 결정들은 알려진 상태나 인자, 또는 둘 다에 따라 달라질 수 있습니다. 예를 들어 특정 데이터에 대한 홈 노드가 있는 시스템에서는, 5개의 연산을 수행할 수 있겠지만 다른 노드에서는 그렇지 않을 수 있습니다.
The best way to track the history of operations on both sides is to use version vectors, which capture the causal dependencies among operations. The vector’s elements are a pair (node, logical time), with one entry for every node that has updated the object and the time of its last update. Given two versions of an object, A and B, A is newer than B if, for every node in common in their vectors, A’s times are greater than or equal to B’s and at least one of A’s times is greater.
양쪽의 작업 이력을 추적하는 가장 좋은 방법은, 작업 간의 인과적 의존관계를 포착하는 버전 벡터를 사용하는 것입니다.
이 벡터는 (노드, 논리적 시간) 쌍으로 구성되며, 해당 객체를 업데이트한 모든 노드에 대해 각각 하나씩의 항목과 마지막 업데이트 시간을 갖습니다. 객체의 두 가지 버전인 A, B가 주어졌을 때, 벡터에 공통으로 있는 모든 노드에 대해 A의 시간이 B의 시간보다 크거나 같은데, A의 시간 중 하나가 B의 시간보다 크다면, A는 B보다 최신입니다.
If it is impossible to order the vectors, then the updates were concurrent and possibly inconsistent. Thus, given the version vector history of both sides, the system can easily tell which operations are already in a known order and which executed concurrently. Recent work[14] proved that this kind of causal consistency is the best possible outcome in general if the designer chooses to focus on availability.
만약 벡터들의 순서를 정렬할 수 없다면, 그 업데이트들은 동시에 일어난 것이므로 아마도 일관성이 없을 수 있습니다. 그러므로 양쪽의 버전 벡터 히스토리가 주어지면, 시스템은 어떤 작업이 알려진 순서대로 실행됐고, 어떤 작업이 동시에 실행된 것인지를 쉽게 알 수 있습니다.
최신의 연구에 의하면 설계자가 가용성에 초점을 맞추기로 선택한 경우, 일반적으로 이런 종류의 인과적 일관성이 최선의 결과라는 것이 증명되었습니다.
Partition recovery
파티션 복구
At some point, communication resumes and the partition ends. During the partition, each side was available and thus making forward progress, but partitioning has delayed some operations and violated some invariants. At this point, the system knows the state and history of both sides because it kept a careful log during partition mode. The state is less useful than the history, from which the system can deduce which operations actually violated invariants and what results were externalized, including the responses sent to the user. The designer must solve two hard problems during recovery:
- the state on both sides must become consistent, and
- there must be compensation for the mistakes made during partition mode.
어느 순간 통신이 재개되면 파티션이 끝납니다. 파티션이 진행되는 동안 양쪽 모두 사용이 가능했으므로 진행이 되긴 했지만, 파티션으로 인해 몇몇 작업이 지연되었고 일부 불변성도 위반되었습니다.
이 시점에서 시스템은 파티션 모드 동안 주의깊게 로그를 유지했기 때문에 양쪽의 상태와 이력을 알고 있습니다.
상태는 이력보다 덜 유용합니다. 이력은 실제로 어떤 작업이 불변성을 위반했는지, 사용자에게 전송된 응답을 포함하여 어떤 결과가 외부화되었는지 추론할 수 있게 도와줍니다. 설계자는 복구 과정에 대해 두 가지 어려운 문제를 해결해야 합니다.
- 양 쪽의 상태가 일관성을 유지해야 합니다. 그리고
- 파티션 모드 동안 발생한 실수에 대한 보정이 있어야 합니다.
It is generally easier to fix the current state by starting from the state at the time of the partition and rolling forward both sets of operations in some manner, maintaining consistent state along the way. Bayou did this explicitly by rolling back the database to a correct time and replaying the full set of operations in a well-defined, deterministic order so that all nodes reached the same state.[15] Similarly, source-code control systems such as the Concurrent Versioning System (CVS) start from a shared consistent point and roll forward updates to merge branches.
파티션 당시의 상태에서 시작해서 어떤 방식으로든 두 작업 집합을 모두 롤백하는 방법을 써서 일관된 상태를 유지한다고 치면, 일반적으로 현재 상태를 수정하는 것이 더 쉽습니다.
Bayou는 데이터베이스를 정확한 시점으로 롤백하고, 모든 노드가 동일한 상태에 도달하도록 잘 정의된 결정론적 순서로 전체 작업 집합을 명시적으로 재생해 수행합니다.
이와 비슷하게 동시 버전 관리 시스템(CVS)과 같은 소스 코드 제어 시스템은 공유된 일관된 지점부터 시작해 업데이트를 롤 포워드하여 브랜치를 병합합니다.3
Most systems cannot always merge conflicts. For example, CVS occasionally has conflicts that the user must resolve manually, and wiki systems with offline mode typically leave conflicts in the resulting document that require manual editing. [16]
대부분의 시스템들에서는 충돌을 항상 병합할 수 없습니다.
예를 들어 CVS에서는 사용자가 수동으로 해결해야만 하는 컨플릭트가 발생하곤 하며, 오프라인 모드의 위키 시스템은 일반적으로 결과 문서에 수동으로 편집해야 하는 컨플릭트를 남겨둡니다.
Conversely, some systems can always merge conflicts by choosing certain operations. A case in point is text editing in Google Docs,[17] which limits operations to applying a style and adding or deleting text. Thus, although the general problem of conflict resolution is not solvable, in practice, designers can choose to constrain the use of certain operations during partitioning so that the system can automatically merge state during recovery. Delaying risky operations is one relatively easy implementation of this strategy.
이와 반대로, 일부 시스템에서는 특정 작업을 선택하여 항상 충돌을 병합할 수 있습니다.
대표적인 예로는 스타일 적용 / 텍스트 추가 / 텍스트 삭제만으로 작업이 제한된 Google Docs의 텍스트 편집을 들 수 있습니다. 이를 통해 충돌 해결이라는 일반적인 문제는 해결할 수 없지만, 실제로는 설계자가 파티셔닝 중에 특정 작업의 사용을 제한하여 시스템이 복구 중에 상태를 자동으로 병합하도록 할 수 있습니다.
위험한 작업을 고의로 지연시키는 것은 이 전략을 상대적으로 쉽게 구현할 수 있는 방법 중 하나입니다.
Using commutative operations is the closest approach to a general framework for automatic state convergence. The system concatenates logs, sorts them into some order, and then executes them. Commutativity implies the ability to rearrange operations into a preferred consistent global order. Unfortunately, using only commutative operations is harder than it appears; for example, addition is commutative, but addition with a bounds check is not (a zero balance, for example).
교환법칙 연산(commutative; 교환 법칙을 따르는 연산)을 사용하는 것은 자동 상태 수렴을 위한 일반적인 프레임워크에 가장 가까운 접근 방식입니다.4 시스템은 로그를 이어붙이고 적절한 순서로 정렬한 다음 실행합니다. 교환성(commutativity)은 선호하는 일관성있는 전역 순서로 연산을 재배열할 수 있는 기능을 의미합니다.
그러나 안타깝게도 교환법칙 연산만 사용하는 것은 생각보다 어렵습니다. 예를 들어 덧셈은 공변 교환법칙을 따르지만 경계 검사가 있는 덧셈은 교환법칙 연산이 아닙니다(예를 들어, 잔액이 0인 경우).
Recent work by Marc Shapiro and colleagues at INRIA[18],[19] has greatly improved the use of commutative operations for state convergence. The team has developed commutative replicated data types (CRDTs), a class of data structures that provably converge after a partition, and describe how to use these structures to
- ensure that all operations during a partition are commutative, or
- represent values on a lattice and ensure that all operations during a partition are monotonically increasing with respect to that lattice.
INRIA의 Mark Shapiro와 동료들의 최근 연구는 상태 수렴을 위한 교환법칙 연산의 사용을 크게 개선했습니다. 이 팀은 파티션 후의 수렴이 증명 가능한 데이터 구조의 클래스인 교환성 복제 데이터 타입(CRDT)을 개발했으며, 이러한 구조를 사용하는 방법을 설명합니다.
- 파티션 동안의 모든 연산이 교환법칙을 따르도록 보장하거나
- 격자 위에 값을 표현하고, 파티션 동안의 모든 연산이 그 격자에 대해 단조 증가하도록 보장합니다.
The latter approach converges state by moving to the maximum of each side’s values. It is a formalization and improvement of what Amazon does with its shopping cart:[20] after a partition, the converged value is the union of the two carts, with union being a monotonic set operation. The consequence of this choice is that deleted items may reappear.
후자의 접근 방식은 양쪽 파티션의 최대값으로 상태를 수렴시킵니다.
이 방법은 Amazon에서 쇼핑 장바구니에서 수행하는 작업을 공식화하고 개선하는 데 사용됐습니다. 파티션 후 수렴된 값은 두 장바구니의 합집합이 되며, 합집합은 단조 증가하는 집합 연산입니다. 이 선택의 부작용은 장바구니에서 삭제된 항목이 다시 나타날 수 있다는 정도입니다.
However, CRDTs can also implement partition-tolerant sets that both add and delete items. The essence of this approach is to maintain two sets: one each for the added and deleted items, with the difference being the set’s membership. Each simplified set converges, and thus so does the difference. At some point, the system can clean things up simply by removing the deleted items from both sets. However, such cleanup generally is possible only while the system is not partitioned. In other words, the designer must prohibit or postpone some operations during a partition, but these are cleanup operations that do not limit perceived availability. Thus, by implementing state through CRDTs, a designer can choose A and still ensure that state converges automatically after a partition.
그러나 CRDT에서는 항목을 추가하고 삭제하는 파티션 허용 집합을 구현하는 것도 가능합니다. 이 접근 방식의 핵심은 추가/삭제된 항목에 대해 각각 하나씩 두 개의 집합을 유지하되, 두 집합의 차집합을 운영하는 것입니다. 각각의 단순화된 집합은 수렴하므로, 차집합도 수렴합니다. 어느 시점에서 시스템은 두 집합에서 삭제된 항목을 제거함으로써 간단히 정리할 수 있습니다.
그러나 이러한 정리는 일반적으로 시스템이 파티션되지 않은 상태에서만 가능합니다. 즉 설계자는 파티션 중에 일부 작업을 금지하거나 연기해야 하지만, 이런 작업은 가용성을 제한하지 않는 정리 작업입니다.
따라서 설계자는 CRDT를 통해 상태를 구현함으로써 A(가용성)를 선택하면서도 파티션 후 상태가 자동으로 수렴되도록 할 수 있습니다.
Compensating for mistakes
실수에 대한 보상
In addition to computing the postpartition state, there is the somewhat harder problem of fixing mistakes made during partitioning. The tracking and limitation of partition-mode operations ensures the knowledge of which invariants could have been violated, which in turn enables the designer to create a restoration strategy for each such invariant. Typically, the system discovers the violation during recovery and must implement any fix at that time.
파티셔닝 후 상태를 계산하는 것 외에도, 파티션 중에 발생한 실수를 수정하는 더 어려운 문제가 있습니다.
파티션 모드의 연산을 추적하고 제한하면 어떤 불변성을 위반했을 수 있는지 알 수 있습니다. 이를 통해 설계자는 각 불변성에 대한 복원 전략을 세울 수 있습니다. 일반적으로 시스템은 복구 중에 위반 사항을 발견하고 그 시점에 수정 사항을 구현해야만 합니다.
There are various ways to fix the invariants, including trivial ways such as "last writer wins" (which ignores some updates), smarter approaches that merge operations, and human escalation. An example of the latter is airplane overbooking: boarding the plane is in some sense partition recovery with the invariant that there must be at least as many seats as passengers. If there are too many passengers, some will lose their seats, and ideally customer service will compensate those passengers in some way.
불변성을 수정하는 방법은 여러 가지가 있습니다. "마지막 작성자가 승리"하는 소박한 방법(일부 업데이트를 무시함), 작업을 병합하는 좀 더 똑똑한 방법, 사람에 의한 에스컬레이션 등이 있습니다.
사람에 의한 에스컬레이션의 예로는 비행기 좌석 초과 예약이 있습니다. 비행기 탑승 문제는 승객 수 만큼의 좌석이 있어야 한다는 불변성을 갖는, 일종의 파티션 복구로 볼 수도 있습니다.
승객이 너무 많으면 일부 승객은 좌석을 잃게 됩니다. 이상적인 고객 서비스에서는 이런 승객들에게 어떤 식으로건 보상을 해주게 됩니다.
The airplane example also exhibits an externalized mistake: if the airline had not said that the passenger had a seat, fixing the problem would be much easier. This is another reason to delay risky operations: at the time of recovery, the truth is known. The idea of compensation is really at the core of fixing such mistakes; designers must create compensating operations that both restore an invariant and more broadly correct an externalized mistake.
비행기 예제는 또한 외부화된 실수를 보여주기도 합니다. 만약 항공사가 예약하는 승객에게 '잔여 좌석이 있다'고 말하지 않았다면 문제를 해결하는 것은 훨씬 쉬웠을 것입니다. 이것은 위험한 작업에 지연을 주는 또 다른 이유라고도 할 수 있습니다. 복구 시점에 진실이 밝혀지기 때문입니다.
보상의 개념은 이런 실수들을 수정하는 데 있어 핵심적인 요소입니다. 설계자는 불변성을 복원하고 더 넓은 범위에서 외부화된 실수를 수정하는 보상 작업을 만들어야 합니다.
Technically, CRDTs allow only locally verifiable invariants-a limitation that makes compensation unnecessary but that somewhat decreases the approach’s power. However, a solution that uses CRDTs for state convergence could allow the temporary violation of a global invariant, converge the state after the partition, and then execute any needed compensations.
기술적으로 CRDT는 로컬에서 검증 가능한 불변성만 허용하므로 보상 개념이 필요하지 않지만, 이로 인해 접근 방식의 효율이 다소 떨어지는 한계가 있습니다. 그러나 상태 수렴에 CRDT를 사용하는 솔루션은 전역 불변성에 대한 일시적인 위반을 허용하고, 파티션 후 상태를 수렴한 다음 필요한 보상을 실행할 수 있습니다.
Recovering from externalized mistakes typically requires some history about externalized outputs. Consider the drunk "dialing" scenario, in which a person does not remember making various telephone calls while intoxicated the previous night. That person’s state in the light of day might be sound, but the log still shows a list of calls, some of which might have been mistakes. The calls are the external effects of the person’s state (intoxication). Because the person failed to remember the calls, it could be hard to compensate for any trouble they have caused.
외부화된 실수로부터 복구하려면, 일반적으로 외부화된 결과물에 대한 어떤 히스토리가 필요합니다.
전날 밤에 술에 취해서 전화를 마구 걸었던 것을 기억하지 못하는 술취한 사람의 '전화 걸기' 시나리오를 생각해 보겠습니다. 날이 밝았을 때 그 사람의 상태는 정상일 것입니다. 그러나 로그에는 여전히 통화 목록이 표시되며, 그 통화들 중 몇몇은 실수를 저지른 것일 수도 있습니다. 이런 통화는 그 사람의 상태(음주)에 따른 외부 효과라 할 수 있습니다. 전화를 건 사람이 통화를 기억을 못하기 때문에 이로 인해 발생한 문제에 대한 보상이 어려울 수 있습니다.
In a machine context, a computer could execute orders twice during a partition. If the system can distinguish two intentional orders from two duplicate orders, it can cancel one of the duplicates. If externalized, one compensation strategy would be to autogenerate an e-mail to the customer explaining that the system accidentally executed the order twice but that the mistake has been fixed and to attach a coupon for a discount on the next order. With-out the proper history, however, the burden of catching the mistake is on the customer.
컴퓨터 이야기로 돌아가 봅시다. 컴퓨터는 파티션 중에 주문을 두 번 실행할 수도 있습니다.
주문 중복이 발생했는데, 시스템이 의도적인 주문과 중복 주문을 구별할 수 있다면 중복 주문을 취소할 수 있을 것입니다. 만약 이를 외부화한다면 생각할 수 있는 보상 전략 중 한 가지는, 시스템이 실수로 주문을 두 번 실행했지만 실수가 수정됐다고 설명하는 이메일을 자동으로 생성하고 다음 주문에 대한 할인 쿠폰을 첨부해 고객에게 전송하는 것입니다.
그러나 적절한 이력이 없다면 실수를 발견하는 부담은 고객에게 전가됩니다.
Some researchers have formally explored compensating transactions as a way to deal with long-lived transactions. [21],[22] Long-running transactions face a variation of the partition decision: is it better to hold locks for a long time to ensure consistency, or release them early and expose uncommitted data to other transactions but allow higher concurrency? A typical example is trying to update all employee records as a single transaction. Serializing this transaction in the normal way locks all records and prevents concurrency. Compensating transactions take a different approach by breaking the large transaction into a saga, which consists of multiple subtransactions, each of which commits along the way. Thus, to abort the larger transaction, the system must undo each already committed subtransaction by issuing a new transaction that corrects for its effects-the compensating transaction.
일부 연구자들은 오랫동안 지속되는 트랜잭션을 처리하는 방법으로 트랜잭션 보상을 공식적으로 검토해 왔습니다.
장기간 실행되는 트랜잭션은 파티션 결정의 다양한 측면을 마주하게 됩니다.
- 일관성을 보장하기 위해 '잠금을 오랫동안 유지하는 것'이 더 나은지?
- 아니면 잠금을 일찍 해제해서 커밋되지 않은 데이터를 다른 트랜잭션에 노출하되, 더 높은 동시성을 허용하는 것이 더 나은지?
일반적인 예로 모든 직원 기록을 단일 트랜잭션으로 업데이트하려고 드는 경우가 있습니다. 이 트랜잭션을 일반적인 방식으로 직렬화하면 모든 레코드에 잠금이 걸려 동시성이 제한됩니다.
보상 트랜잭션은 큰 트랜잭션을 여러 개의 하위 트랜잭션으로 구성된 사가(saga)로 나누는 다른 접근 방식을 취합니다. 하위 트랜잭션은 각자 진행 중에 커밋을 하게 됩니다.
따라서 대규모 트랜잭션을 중단하려면 시스템은 이미 커밋된 각 하위 트랜잭션을 취소하고 그 영향을 바로잡는 새 트랜잭션, 즉 보상 트랜잭션을 발행해야 합니다.
In general, the goal is to avoid aborting other transactions that used the incorrectly committed data (no cascading aborts). The correctness of this approach depends not on serializability or isolation, but rather on the net effect of the transaction sequence on state and outputs. That is, after compensations, does the database essentially end up in a place equivalent to where it would have been had the subtransactions never executed? The equivalence must include externalized actions; for example, refunding a duplicate purchase is hardly the same as not charging that customer in the first place, but it is arguably equivalent. The same idea holds in partition recovery. A service or product provider cannot always undo mistakes directly, but it aims to admit them and take new, compensating actions. How best to apply these ideas to partition recovery is an open problem. The "Compensation Issues in an Automated Teller Machine" sidebar describes some of the concerns in just one application area.
일반적으로 목표는 잘못 커밋된 데이터를 사용한 다른 트랜잭션의 중단을 방지하는 것입니다(cascading 중단 없음) 이 접근법의 정확성은 직렬화 가능성이나 격리와는 무관하며, 트랜잭션 시퀀스가 상태 및 출력에 미치는 순수한 영향에 따라 달라집니다. 즉 보상 조치 후에 데이터베이스는 기본적으로 하위 트랜잭션이 실행되지 않았을 때와 동일한 상태여야 합니다.
동등성에는 외부화된 작업이 포함돼야 합니다. 예를 들어, '중복 구매를 환불'하는 것은 처음부터 해당 고객에게 요금을 청구하지 않은 것과 완전히 똑같다고 보기는 어렵지만, 어느 정도 합리적으로 동등하다고는 할 수 있습니다.
파티션 복구에서도 같은 아이디어가 적용됩니다. 서비스 또는 제품 제공업체가 항상 실수를 직접 취소할 수는 없습니다. 그러나 실수를 인정하고 새로운 보상 조치를 취하는 것을 목표로 삼을 수 있습니다. 이런 아이디어를 파티션 복구에 가장 잘 적용하는 방법은 아직 해결되지 않은 문제입니다.
"현금 자동 입출금기에서의 보상 문제" 섹션에서는 한 가지 애플리케이션 영역에 대한 몇 가지 고려 사항을 설명합니다.
System designers should not blindly sacrifice consistency or availability when partitions exist. Using the proposed approach, they can optimize both properties through careful management of invariants during partitions. As newer techniques, such as version vectors and CRDTs, move into frameworks that simplify their use, this kind of optimization should become more wide-spread. However, unlike ACID transactions, this approach requires more thoughtful deployment relative to past strategies, and the best solutions will depend heavily on details about the service’s invariants and operations.
시스템 설계자들은 파티션이 존재할 때 일관성 또는 가용성을 맹목적으로 희생해서는 안 됩니다. 제안된 접근 방법을 사용하면 파티션 동안 불변성을 신중하게 관리하여 두 가지 속성을 모두 최적화할 수 있습니다.
버전 벡터와 CRDT 같은 최신 기술이 단순하게 사용할 수 있는 프레임워크로 이동함에 따라 이러한 최적화는 점점 널리 퍼질 것입니다. 그러나 이 접근 방식은 ACID 트랜잭션과 달리 과거 전략에 비해 더 신중한 배포가 필요하며, 최상의 솔루션은 서비스의 불변성과 운영에 대한 세부 정보에 따라 크게 달라집니다.
Compensation issues in an automated teller machine
현금 자동 입출금기에서의 보상 문제
In the design of an automated teller machine (ATM), strong consistency would appear to be the logical choice, but in practice, A trumps C. The reason is straightforward enough: higher availability means higher revenue. Regardless, ATM design serves as a good context for reviewing some of the challenges involved in compensating for invariant violations during a partition.
현금 자동 입출금기(ATM)를 설계할 때는 강력한 일관성이 논리적 선택일 것 같지만, 실제로는 A(가용성)가 C(일관성)보다 우선시됩니다.
그 이유는 매우 간단합니다. ATM의 가용성이 높으면 은행의 수익도 높아지기 때문입니다. 그렇지만 ATM 설계는 파티션 중 불변성 위반에 대한 보상과 관련된 몇 가지 도전적인 과제를 검토하는 데 좋은 사례라 할 수 있습니다.
The essential ATM operations are deposit, withdraw, and check balance. The key invariant is that the balance should be zero or higher. Because only withdraw can violate the invariant, it will need special treatment, but the other two operations can always execute.
ATM의 필수 기능은 입금, 출금, 잔액 확인입니다. 핵심 불변성은 잔액이 0 이상이어야 한다는 것입니다. 이 불변성을 위반할 수 있는 것은 출금 뿐이므로, 출금은 특별한 처리가 필요하지만 다른 두 작업은 항상 실행할 수 있습니다.
The ATM system designer could choose to prohibit withdrawals during a partition, since it is impossible to know the true balance at that time, but that would compromise availability. Instead, using stand-in mode (partition mode), modern ATMs limit the net withdrawal to at most k, where k might be $200. Below this limit, withdrawals work completely; when the balance reaches the limit, the system denies withdrawals. Thus, the ATM chooses a sophisticated limit on availability that permits withdrawals but bounds the risk.
ATM 시스템 설계자는 파티션 중에 실제 잔액을 알 수 없기 때문에 출금을 금지하도록 선택할 수 있습니다. 그런데 이렇게 하면 가용성이 저하됩니다.
따라서 그렇게 하는 대신, 최신 ATM은 대기 모드(파티션 모드)를 사용해 순 출금 한도를 최대 k(예: k = $200)로 제안합니다. 이 한도 이하에서는 출금이 완전히 작동하지만, 잔액이 이 한도에 도달하면 시스템은 출금을 거부합니다. 따라서 ATM은 출금을 허용하지만 위험은 제한하는 정교한 가용성을 선택합니다.
When the partition ends, there must be some way to both restore consistency and compensate for mistakes made while the system was partitioned. Restoring state is easy because the operations are commutative, but compensation can take several forms. A final balance below zero violates the invariant. In the normal case, the ATM dispensed the money, which caused the mistake to become external. The bank compensates by charging a fee and expecting repayment. Given that the risk is bounded, the problem is not severe. However, suppose that the balance was below zero at some point during the partition (unknown to the ATM), but that a later deposit brought it back up. In this case, the bank might still charge an overdraft fee retroactively, or it might ignore the violation, since the customer has already made the necessary payment.
파티션이 종료되면 일관성을 복원하고 시스템이 파티션된 동안 발생한 오류를 보상할 수 있는 방법이 있어야 합니다. 작업이 교환 가능하기 때문에 상태 복원은 쉽습니다. 그러나 보상은 여러 가지 형태로 이루어질 수 있습니다.
최종 잔액이 0 미만이면 불변성을 위반합니다. 일반적인 경우라면 ATM이 돈을 지급하고 말았으니 오류가 외부로 전달됐습니다. 은행은 수수료를 부과하고 상환을 기대하는 방식으로 보상합니다. 위험이 제한되어 있으므로, 이 문제는 그리 심각하지 않습니다.
그러나 파티션 중 어느 시점에 잔액이 0 미만이었지만(ATM에서는 알 수 없음) 나중에 입금하여 잔액이 다시 올라갔다고 가정해 보겠습니다. 이런 경우 은행은 여전히 초과 출금 수수료를 추후에 부과하거나, 고객이 이미 필요한 결제를 완료했기 때문에 위반 사항을 무시할 수도 있습니다.
In general, because of communication delays, the banking system depends not on consistency for correctness, but rather on auditing and compensation. Another example of this is "check kiting," in which a customer withdraws money from multiple branches before they can communicate and then flees. The overdraft will be caught later, perhaps leading to compensation in the form of legal action.
일반적으로는 통신 지연으로 인해 은행 시스템은 정확성에 대한 일관성보다는 감사 및 보상에 의존합니다. 이와 관련이 있는 또 다른 예로는 고객이 여러 지점에서 돈을 출금한 후, 연락이 닿기 전에 도망치는 "check kitting"이 있습니다.
물론 초과 출금은 적발되면 법적 조치의 형태로 보상을 받게 될 수 있습니다.
Acknowledgments
감사의 말
I thank Mike Dahlin, Hank Korth, Marc Shapiro, Justin Sheehy, Amin Vahdat, Ben Zhao, and the IEEE Computer Society volunteers for their helpful feedback on this work.
이 작업에 도움을 주신 Mike Dahlin, Hank Korth, Marc Shapiro, Justin Sheehy, Amin Vahdat, Ben Zhao, 그리고 IEEE Computer Society 자원봉사자들에게 감사드립니다.
About the Author
Eric Brewer is a professor of computer science at the University of California, Berkeley, and vice president of infrastructure at Google. His research interests include cloud computing, scalable servers, sensor networks, and technology for developing regions. He also helped create USA.gov, the official portal of the federal government. Brewer received a PhD in electrical engineering and computer science from MIT. He is a member of the National Academy of Engineering. Contact him at …@…
Eric Brewer는 캘리포니아 대학 버클리 캠퍼스의 컴퓨터 과학 교수이자 Google의 인프라스트럭처 부문 부사장입니다. 그의 연구 관심사는 클라우드 컴퓨팅, 확장 가능한 서버, 센서 네트워크, 그리고 개발 도상국을 위한 기술 등이 있습니다. 그는 또한 미국 정부의 공식 포털인 USA.gov 를 창설하는 데에도 기여했습니다. Brewer는 MIT에서 전기 공학 및 컴퓨터 과학 박사 학위를 받았습니다. 그는 미국 국립 공학 아카데미의 회원입니다.
References
- E. Brewer, "Lessons from Giant-Scale Services," IEEE Internet Computing, July/Aug. 2001, pp. 46-55.
- 2. A. Fox et al., "Cluster-Based Scalable Network Services," Proc. 16th ACM Symp. Operating Systems Principles (SOSP 97), ACM, 1997, pp. 78-91.
- 3. A. Fox and E.A. Brewer, "Harvest, Yield and Scalable Tolerant Systems," Proc. 7th Workshop Hot Topics in Operating Systems (HotOS 99), IEEE CS, 1999, pp. 174-178.
- 4. E. Brewer, "Towards Robust Distributed Systems," Proc. 19th Ann. ACM Symp.Principles of Distributed Computing (PODC 00), ACM, 2000, pp. 7-10; on-line resource.
- B. Cooper et al., "PNUTS: Yahoo!’s Hosted Data Serving Platform," Proc. VLDB Endowment (VLDB 08), ACM, 2008, pp. 1277-1288.
- J. Sobel, "Scaling Out," Facebook Engineering Notes, 20 Aug. 2008; on-line resource.
- J. Kistler and M. Satyanarayanan, "Disconnected Operation in the Coda File System" ACM Trans. Computer Systems, Feb. 1992, pp. 3-25.
- K. Birman, Q. Huang, and D. Freedman, "Overcoming the ‘D’ in CAP: Using Isis2 to Build Locally Responsive Cloud Services," Computer, Feb. 2011, pp. 50-58.
- M. Burrows, "The Chubby Lock Service for Loosely-Coupled Distributed Systems," Proc. Symp. Operating Systems Design and Implementation (OSDI 06), Usenix, 2006, pp. 335-350.
- J. Baker et al., "Megastore: Providing Scalable, Highly Available Storage for Interactive Services," Proc. 5th Biennial Conf. Innovative Data Systems Research (CIDR 11), ACM, 2011, pp. 223-234.
- D. Abadi, "Problems with CAP, and Yahoo’s Little Known NoSQL System," DBMS Musings, blog, 23 Apr. 2010; on-line resource.
- C. Hale, "You Can’t Sacrifice Partition Tolerance," 7 Oct. 2010; on-line resource.
- W. K. Edwards et al., "Designing and Implementing Asynchronous Collaborative Applications with Bayou," Proc. 10th Ann. ACM Symp. User Interface Software and Technology (UIST 97), ACM, 1999, pp. 119-128.
- P. Mahajan, L. Alvisi, and M. Dahlin, Consistency, Availability, and Convergence, tech. report UTCS TR-11-22, Univ. of Texas at Austin, 2011.
- D.B. Terry et al., "Managing Update Conflicts in Bayou, a Weakly Connected Replicated Storage System," Proc. 15th ACM Symp. Operating Systems Principles (SOSP 95), ACM, 1995, pp. 172-182.
- B. Du and E.A. Brewer, "DTWiki: A Disconnection and Intermittency Tolerant Wiki," Proc. 17th Int’l Conf. World Wide Web (WWW 08), ACM, 2008, pp. 945-952.
- "What’s Different about the New Google Docs: Conflict Resolution" blog.
- M. Shapiro et al., "Conflict-Free Replicated Data Types," Proc. 13th Int’l Conf. Stabilization, Safety, and Security of Distributed Systems (SSS 11), ACM, 2011, pp. 386-400.
- M. Shapiro et al., "Convergent and Commutative Replicated Data Types," Bulletin of the EATCS, no. 104, June 2011, pp. 67-88.
- G. DeCandia et al., "Dynamo: Amazon’s Highly Available Key-Value Store," Proc. 21st ACM SIGOPS Symp. Operating Systems Principles (SOSP 07), ACM, 2007, pp. 205-220.
- H. Garcia-Molina and K. Salem, "SAGAS," Proc. ACM SIGMOD Int’l Conf. Management of Data (SIGMOD 87), ACM, 1987, pp. 249-259.
- H. Korth, E. Levy, and A. Silberschatz, "A Formal Approach to Recovery by Compensating Transactions," Proc. VLDB Endowment (VLDB 90), ACM, 1990, pp. 95-106
함께 읽기
- [[/jargon/cap-theorem]]
주석
-
역주: 'ACID vs BASE' 에서 또 다른 유명한 대립 관계인 '산 vs 염기'가 연상된다. ↩
-
역주: 쿼럼. 정족수(定足數). 분산 컴퓨팅 시스템에서 사용하는 용어. 다수결을 토대로 하는 합의 과정에 참여하는 최소한의 노드 수를 의미한다.
5개의 노드가 있는 분산 시스템에서 quorum을 3으로 설정한다면 노드 2개에 장애가 발생해도 작동이 가능하다. 대신 데이터 업데이트를 처리하려면 최소한 3개 노드가 동의를 해야 한다. ↩ -
역주: 롤 포워드 머지는, 공통된 기준점에서 시작해 두 브랜치의 변경 사항을 순서대로 적용해 최종 상태를 얻는다. ↩
-
교환 법칙을 따르는 연산은
3 + 2,2 + 3처럼 순서에 관계없이 결과가 똑같은 연산을 의미한다. 이런 특성을 갖는 연산을 만들어 사용하면 순서를 변경해서 적용해도 결과는 같을 것이다. 분산 시스템에서도 이런 식의 연산만 사용한다면 순서가 어떻건 결과는 같을 것이기 때문에 복구가 편해지고, 자동으로 복구하는 것도 가능해진다. ↩