B-Tree
보편적인 색인 구조
B-Tree
기원과 컨셉
다음은 TAOCP 3권에서 인용한 것이다.
다중 트리 분기를 수단으로 하는 새로운 외부 검색 접근방식이 1970년에 바이에르(R. Bayer)와 매크라이트(E. McCreight)에 의해서, 그리고 그와 독립적으로 같은 시기에 코프먼(M. Kaufman)에 의해서 발견되었다. 그들의 착안은 B 트리 라고 불리는 새로운 다목적 자료구조에 기초를 둔 것으로, 비교적 간단한 알고리즘들을 사용해서 큰 파일의 검색과 갱신 모두를 수행할 수 있으며 최악의 경우에도 일정한 효율성이 보장된다. 1
다음은 "알고리즘"에서 인용한 것이다.
1970년대 베이어(Bayer)와 맥크레이트(McCreight)는 외부 탐색을 위한 다중 균형 트리를 처음 연구했고 이러한 트리를 B-트리라고 이름 지었다. 어떤 사람들은 베이어와 맥크레이트가 제안한 알고리즘의 데이터 구조에 한정해서만 B-트리라고 부르기도 한다. 이 책에서는 고정 크기 페이지를 사용하는 다중 균형 탐색 트리를 지칭하는 일반적인 이름으로서 B-트리를 사용하기로 한다. M개의 값을 지정할 때는 "오더 M B-트리"라고 부른다. 오더 4인 B-트리는 각 노드가 최대 3개, 최소 2개의 키-링크 쌍을 가지고, 오더 6인 B-트리는 최대 5개, 최소 3개인 키-링크 쌍을 가지는 식이다(뿌리 노드는 예외이다). 뿌리 노드가 예외인 이유는 트리 생성 알고리즘을 살펴볼 때 분명해진다. 2
다음은 "데이터 중심 애플리케이션 설계"에서 인용한 것이다.
B 트리는 1970년대에 등장했다. B 트리는 이후 10년도 안 돼 "보편적인 색인 구조"라 불렸고 B 트리는 이 기간 동안 테스트를 잘 견뎌냈다. 여전히 거의 대부분의 관계형 데이터베이스에서 표준 색인 구현으로 B 트리를 사용할 뿐 아니라 많은 비관계형 데이터베이스에서도 사용한다.
B 트리는 SS테이블과 같이 키로 정렬된 키-값 쌍을 유지하기 때문에 키-값 검색과 범위 질의에 효율적이다. 하지만 비슷한 점은 이 정도가 전부다. B 트리는 설계 철학이 매우 다르다.
(중략)
반면 B 트리는 전통적으로 4KB 크기(때로는 더 큰)의 고정 크기 블록이나 페이지로 나누고 한 번에 하나의 페이지에 읽기 또는 쓰기를 한다. 디스크가 고정 크기 블록으로 배열되기 때문에 이런 설계는 근본적으로 하드웨어와 조금 더 밀접한 관련이 있다. 3
다음 이미지는 1970년 Bayer와 McCreight의 논문 "ORGANIZATION AND MAINTENANCE OF LARGE ORDERED INDICES"에서 캡처한 것이다.4
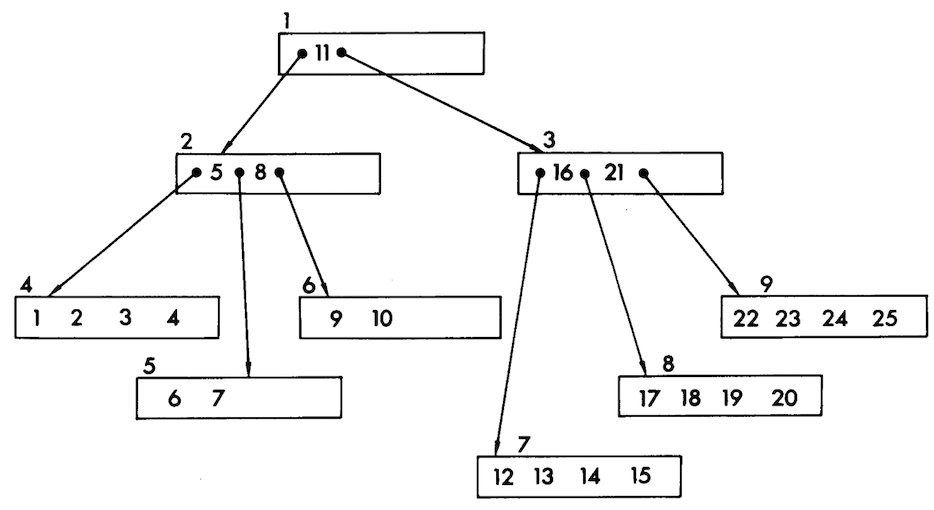
2-3 탐색 트리
B-트리는 2-3 탐색 트리의 확장이므로, 2-3 탐색 트리에 대해 인용한다.
정의
"2-3 탐색 트리"는 공백이거나 다음 중 하나이다.
- 2-노드: 하나의 키(와 그에 연관된 값) 그리고 두 개의 링크를 가진다. 왼쪽 링크는 더 작은 키들을 담고 있는 2-3 탐색 트리를, 오른쪽 링크는 더 큰 키들을 담고 있는 2-3 탐색 트리를 가리킨다.
- 3-노드: 두 개의 키(와 각각에 연관된 두 개의 값) 그리고 세 개의 링크를 가진다. 왼쪽 링크는 더 작은 키들을 담고 있는 2-3 탐색 트리를, 가운데 링크는 두 개의 키 사이에 있는 키들을 담고 있는 2-3 탐색 트리를, 오른쪽 링크는 더 큰 키들을 담고 있는 2-3 탐색 트리를 가리킨다.
그리고 공백 트리는 null 링크로 표현한다.5
B-Tree의 정의
다음은 TAOCP 3권에서 인용한 것이다.1
\(m\)차 B 트리는 다음과 같은 성질들을 만족하는 트리이다.
- 모든 노드는 최대 \(m\) 개의 자식들을 가진다.
- 루트와 잎들을 제외한 모든 노드는 적어도 \(m / 2\) 개의 자식들을 가진다.
- 루트는 적어도 두 개의 자식들을 가진다(루트 자신이 잎이 아닌 한).
- 모든 잎은 같은 수준에 나타나며, 정보는 답지 않는다.
- 잎이 아닌 한 노드의 자식들이 \(k\)개일 때, 그 노드는 \(k-1\)개의 키들을 담는다.
다음은 "알고리즘"에서 인용한 것이다.
정의
오더 M인 B-트리(여기서 M은 짝수)는 외부 k-노드(k개의 키와 연관 정보를 포함) 또는 내부 k-노드(k 개의 키, 키들로 구분되는 k개 구간에 해당하는 B-트리로의 링크들)로 구성되는 트리로 다음과 같은 구조적인 속성을 갖는다. 뿌리에서 어떤 외부 노드로의 모든 경로는 반드시 같은 길이를 가진다(완전 균형). 그리고 뿌리에서 k는 반드시 2에서 M-1 범위에 있어야 하고(B-트리가 공백인 경우 예외), 다른 노드들에서는 k는 반드시 M/2 에서 M-1 범위에 있어야 한다.6
B-Tree는 2-3 트리를 확장한다.
- 2-3 트리와는 달리 데이터를 트리에 저장하는 것이 아니라 복제된 키들로 트리를 만들고, 각 키가 링크와 연결된다.
- 이를 통해 인덱스와 테이블이 분리된다.
- 2-3 트리에서 그랬듯, 각 노드가 가질 수 있는 키-링크 쌍의 개수에 상하한이 있다.
B-Tree는 파라미터 M 값을 사용한다.
- M은 관례적으로 짝수 값을 갖는다.
- 모든 노드가 가질 수 있는 키-링크 쌍 k의 수는 \({ M \over 2 } \le k \le M-1\) 개이다.
- 단 최소값은 2 이상이어야 한다.
- 루트 노드는 예외적으로 \({ M \over 2 }\) 보다 적은 수의 키-링크 쌍을 가질 수 있다.
- 예를 들어 M이 10 이라면 모든 노드가 가질 수 있는 키-링크 쌍의 수는 5 ~ 9 개이다.
- M 값에 따라 "오더 M B-트리"라고 부른다.
- 오더 6 B-트리: 각 노드가 3 ~ 5 개의 키-링크 쌍을 갖는다.
- 오더 4 B-트리: 각 노드가 2 ~ 3 개의 키-링크 쌍을 갖는다.
탐색
다음 예제는 TAOCP 3권을 인용한 것이다.1
\(j\) 개의 키들과 \(j+1\) 개의 포인터들을 가진 한 노드를 다음과 같이 표현할 수 있다.
(1)
여기서 \(K_1 < K_2 < ... < K_j\) 이며 \(P_i\)는 키들이 \(K_i\)에서 \(K_{i+1}\) 사이인 하위 트리를 가리키는 포인터이다. 이런 구조에서 B트리의 검색은 상당히 간단하다: 노드 (1)을 내부 메모리로 가져온 후, 키 \(K_1, K_2, ..., K_j\) 중에서 주어진 인수를 찾는다. (j가 크다면 이진 검색을 사용할 수도 있겠지만, j가 좀 작은 듯 하다면 순차 검색이 제일 낫다.) 만일 검색에 성공했다면 원하는 키를 찾은 것이다. 그러나 인수가 \(K_i\)와 \(K_{i+1}\) 사이에 있어서 검색이 실패했다면 \(P_i\)가 가리키는 노드를 가져와서 검색을 진행한다. 인수가 \(K_1\) 보다 작을 때에는 포인터 \(P_0\)을, \(K_j\)보다 크다면 \(P_j\)를 사용한다. 만일 \(P_i = ∧\) 이면 검색은 실패한 것이다.
명쾌하고 심플한 설명이다.
탐색 예제
다음은 오더 6 B-트리를 이해하기 쉽게 표현한 이미지다.
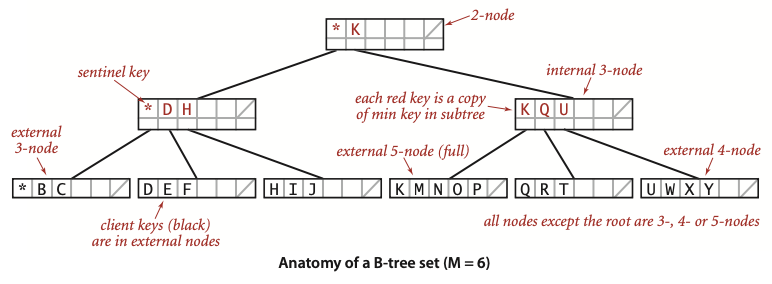
- 오더 6 B-트리이므로, 루트 노드를 제외한 모든 노드가 가진 아이템의 수가 3 ~ 5 개라는 것을 알 수 있다.
- 2-node: 키가 2개 있는 노드.
- 3-node: 키가 3개 있는 노드.
- 내부 노드(internal node): 키의 복제본과 페이지를 연관
- 외부 노드(external node): 실제 데이터에 대한 참조 저장
- 빨간색 키: 서브 트리에서 가장 작은 값을 가진 키의 복제본.
- 보초 키(sentinel key,
*): 다른 키들보다 작은 키.
탐색은 항상 루트에서부터 시작한다.
만약 위의 트리에서 O를 찾는다면 다음과 같은 과정을 거칠 것이다.
- 루트 노드에서 시작.
O는K보다 큰 값이므로,K와 연결된 서브 트리로 이동. O는K보다 크고Q보다 작으므로,K와 연결된 서브 트리로 이동.- 외부 5노드(\(K,M,N,O,P\))에서
O가 있음을 확인하여 탐색 종료.
G를 찾는다고 해보자.
- 루트 노드에서 시작.
G는K보다 작은 값이므로,*와 연결된 서브 트리로 이동. G는D보다 크고H보다 작으므로,D와 연결된 서브 트리로 이동.- 외부 3노드(\(D,E,F\))에
G가 존재하지 않음을 확인하고 탐색 종료.
삽입
B-트리에 새로운 키를 추가할 때에는 다음 과정을 따른다.
- 새로운 키를 포함하는 범위의 페이지를 찾는다.
- 해당 페이지에 키와 값을 추가한다.
- 새로운 키를 추가한 페이지가 오버플로우하면, 반으로 채워진 페이지 둘로 분할한다.
- 상위 페이지를 갱신하여, 새로 만들어진 두 페이지를 상위 페이지와 연결한다.
이 알고리즘은 트리가 계속 균형을 유지하는 것을 보장한다. n개의 키를 가진 B 트리는 깊이가 항상 \(O(\log n)\)이다. 대부분의 데이터베이스는 B 트리의 깊이가 3이나 4단계 정도면 충분하므로 검색하려는 페이지를 찾기 위해 많은 페이지 참조를 따라가지 않아도 된다(분기 계수 500의 4KB 페이지의 4단계 트리는 256TB까지 저장할 수 있다).7
삽입 예제
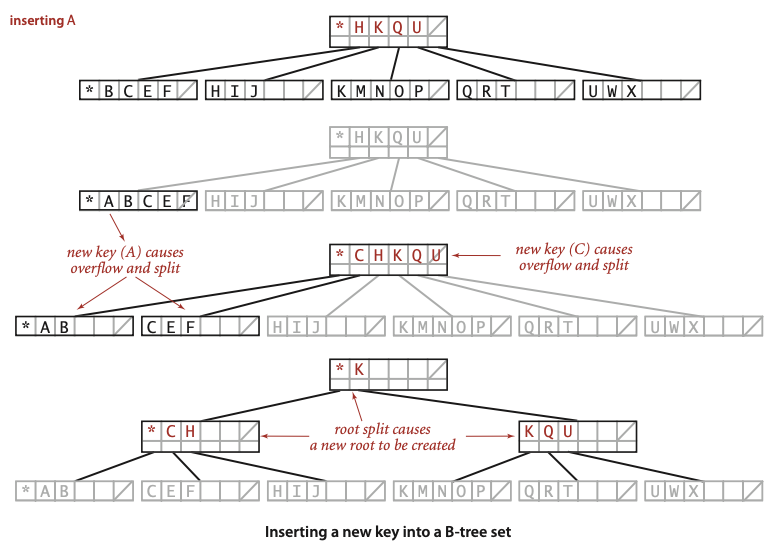
위의 예는 "알고리즘"에서 가져온 것이며 B-트리에 A를 추가하는 내용이다.8
- 두번째 줄: 새로운 키
A를 추가하여 외부 5노드(*)에 오버플로우가 발생. - 세번째 줄: 오버플로우가 발생한 외부 5노드를 두 개의 노드로 분할.
- 새로 분리된 노드는
C로 시작하며, 이 노드의 최소값은 루트 노드에도 등록. - 그런데 루트 노드에
C가 추가되면서, 루트 노드에서도 오버플로우가 발생.
- 새로 분리된 노드는
- 마지막 줄: 루트 노드 분할.
- 두 개의 새로운 내부 노드(보초 키
*를 최소값으로 갖는 노드,K가 최소값인 노드)가 추가된다.
- 두 개의 새로운 내부 노드(보초 키
정말 심플하고 근사하다.
B트리의 멋진 점은 삽입 역시 상당히 간단하다는 것이다.1
성능
명제 B
N개의 항목을 가진 오더 M인 B-트리에서의 탐색 또는 삽입 작업은 \(\log M \ N\)에서 \(\log \frac{M}{2} \ N\)회에 이르는 탐지를 소요한다. 이 값은 실제 응용에서 상수에 가깝다.
증명
M개의 키로 가득 찬 노드를 나누면서 트리가 커 나가기(자식이 분할되면서) 때문에 트리 내부에 있는 모든 노드(뿌리 노드와 외부 노드가 아닌 노드)가 \({ M \over 2 }\)에서 \(M-1\) 범위의 링크를 가진다. 위 명제는 이 부분에서 유도된다. 최적 조건에서 이 노드들은 가지 브랜치 비율이 \(M-1\)인 완전 트리가 된다. 이 경우 기술된 경계 값이 직접적으로 유도된다. 최악 조건에서는 각각 차수 \({ M \over 2 }\)인 완전 트리를 가리키는 항목 두 개가 뿌리 노드에 있게 된다. 밑이 M인 로그를 취하면 매우 작은 숫자가 얻어진다. 예를 들어 M이 1,000 이라면 625억 개보다 작은 N에서 트리의 높이가 4보다 작다( \(\log_{1000} 625 \times 10^9 = 3.598...\) ).9
이건 정말 엄청난 결과라 할 수 있다.
명제 B는 매우 중요한 결과로 고찰해볼 가치가 있다. 처리해야만 하는 상상 가능한 가장 큰 규모의 데이터가 있다고 하자. 단지 4~5 번의 탐지만으로 원하는 키를 찾아내고 삽입할 수 있는 알고리즘을 개발해낼 수 있을까? B-트리를 몰랐다면 가능하리라고 생각하기 힘들었을 것이다. B-트리는 그러한 효율성을 달성해내기 때문에 널리 사용되고 있다.10
공간
B-트리는 생성 규칙에 의해 각 페이지의 최소한 절반은 채워진다. 따라서 최악의 경우 실제 키의 개수에 비해 두 배 더 많은 공간을 소요할 수 있다. 그리고 링크를 위한 공간이 추가적으로 소요된다. 1979년 야오(A. Yao)는 무작위 키 상황에서의 수학적 분석을 통해(이 부분은 이 책의 범위를 벗어난다) 노드 하나의 평균 키 개수가 \(M \ln 2\)임을 밝혔다.9
\(ln 2\)는 약 0.6931 이므로, \(M = 100\)인 경우를 생각해 보면 대략 69.3 정도 될 것이다.
1979년 야오의 연구를 바탕으로 소박하게 생각한다면, 노드 하나는 평균적으로 30.7 % 정도 비어 있을 것으로 생각할 수 있을 것 같다(참고로 세지윅은 약 44%에 달하는 공간이 사용되지 않는다고 한다10).
B+ Tree
다음은 "데이터베이스 인터널스"에서 인용한 것이다.
B+-트리는 리프 노드에 값을 저장하기 때문에 모든 작업(삽입, 업데이트, 삭제, 검색)은 리프 노드에만 영향을 미치며 상위 레벨의 노드는 노드 분할 혹은 병합이 일어날 때에만 영향을 받는다. 11
다음은 "트랜잭션 처리의 원리"에서 인용한 것이다.
데이터베이스 시스템의 인덱스를 구현하기 위해 가장 널리 이용하는 데이터 구조는 B-트리이다. B-트리는 트리로 구성되는 페이지의 집합으로 이루어진다. 리프 페이지(leaf page)(즉, 트리에서 다른 페이지를 가리키지 않는 페이지)는 테이블의 키와 같이 인덱스화되는 데이터를 포함한다. 내부 노드(internal node)라고 하는 나머지 페이지는 검색에 사용되는 키 값의 디렉토리이다.
내부 노드가 키와 관계되는 데이터를 포함하는 경우에 그 트리를 B-트리라고 한다. 반면에, 내부 노드가 키 값만 포함하며 관련 데이터는 포함하지 않는 경우에 이를 B+ 트리라고 한다. 모든 예에서 B+ 트리를 사용하는데, 이들이 실제로 더 많이 사용되기 때문이다. 12
다음은 "관계형 데이터베이스 실전 입문"에서 인용한 것이다.
B+트리는 데이터(인덱스의 값)가 저장된 리프 노드와 리프 노드까지의 경로 역할을 하는 논리프 노드로 구성된다. 경로의 출발점이 되는 노드는 루트 노드라고 한다. 논리프 노드에는 자식 노드가 보유하는 값 중에 최솟값이 저장돼 있다.
또한, 자식 노드에는 포인터(대부분 페이지 ID)가 저장되고 "어떤 경로를 검색하면 원하는 인덱스를 찾을 수 있는지" 알 수 있게 되어 있다. 따라서 B+ 트리의 검색은 루트 노드에서 어떤 리프 노드에 이르는 한 개의 경로만 검색하면 되므로 굉장히 효율적이다. 이 성질은 아무리 트리의 크기가 크거나 계층이 증가해도 변하지 않는다.
B+ 트리 인덱스에는 또 다른 재미있는 특징이 있다. 그것은 인덱스에 있는 항목의 수가 테이블의 행 수와 똑같다는 점이다. 따라서 테이블의 행이 늘어나면 인덱스도 커진다. 책의 끝부분에 단어의 일부만 실려있는 색인과는 굉장히 다르다.13
- B+ Tree의 각 페이지는 범위별 키 값을 갖는다.
다음은 B+ Tree의 예를 표현한 것으로, "트랜잭션 처리의 원리"에서 인용한 것이다.14
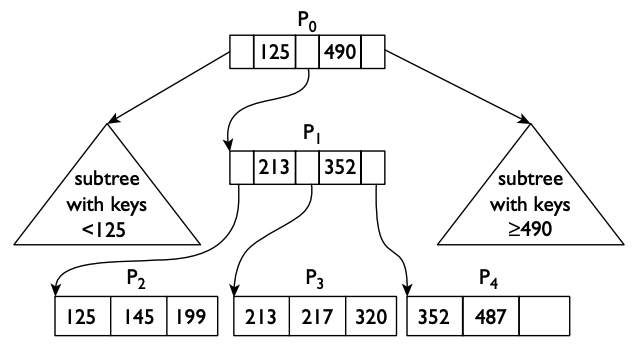
이 예에서 키 값 299를 찾으려 한다고 하자.
- 루트에서 \([125, 490)\) 범위에 해당되므로, \(P_1\)로 이동한다.
- \(P_1\)에서 \([213, 352)\) 범위에 해당되므로, \(P_3\)으로 이동한다.
- \(P_3\)에 299가 없으므로, 찾으려는 값은 인덱스에 존재하지 않는다.
n개의 키 값이 있을 때, B+ Tree는 키 값 목록 \([k_1, k_2, ..., k_n]\)에 대해, \(n+1\) 하위범위를 생성한다.
B+ Tree 페이지는 디스크 페이지의 크이기므로, 굉장히 많은 수의 페이지를 관리할 수 있다.
예를 들어, 한 페이지가 8K바이트, 한 키가 8 바이트, 한 포인터가 2바이트인 경우에 한 페이지는 819개 키를 유지할 수 있으므로 3-레벨 B+ 트리는 \(820^2 = 672,400\) 리프를 포함할 수 있다. 각 리프가 80개 레코드를 유지하는 경우에 그것은 모두 530만 개의 레코드를 유지한다. 트리가 네 개의 레벨이면 그 트리는 약 44억 개의 레코드를 유지할 수 잇다. 이들 숫자에서 보듯이, B+ 트리가 4-레벨보다 많은 경우는 매우 드물다.15
위의 인용문의 계산은 다음과 같이 따라해볼 수 있다.
\[{ \text{페이지 크기} \over \text{키 크기} } = { 8 \times 1024 \over 8 + 2 } = 819.2\]- 3 level B+ Tree일 경우 \(820^2 = 672,400\) 개의 leaf.
- 각 leaf가 갖는 레코드가 80개라면 \(672440 \times 80 = 44,109,440,000\). 즉 약 44억 개.
B+ 트리는 디스크에 상주하며 이들의 일부가 메인 메모리에 버퍼링하도록 의도된 것이다. 루트는 항상 메인 메모리에 캐시되며 대개 루트 아래 레벨도 캐시된다. 레벨 3과 4는 문제가 된다. 이들 가운데 얼마나 많은 것이 캐시되느냐 하는 것은 얼마나 많은 메모리가 이용 가능하며 페이지들이 얼마나 자주 엑세스되느냐에 따라, 즉 이들을 캐싱할 가치가 있느냐 없느냐에 따라 달라진다. 그러나 어떤 키를 검색하기 위하여 레벨 3과 4를 전혀 캐싱하지 않더라도, 단 두 개의 디스크 페이지만 엑세스하면 된다.15
- 트리의 레벨이 많다면 성능은 나빠진다.
B+ Tree 인덱스 사용시 주의점
- B+ 트리 인덱스는 등가 비교와 범위 검색에 사용할 수 있다.
- 예:
WHERE key = 123 - 예:
WHERE key BETWEEN 10 AND 1000
- 예:
- 범위 검색 시에는 최소값을 기준으로 한 검색을 사용할 수 있다.
- 예:
WHERE key like 'a%' - 잘못된 예:
WHERE key like %a이렇게 하면 B+ 트리 구조 활용이 어렵다. - 잘못된 예:
WHERE key like %a%이렇게 하면 B+ 트리 구조 활용이 어렵다.
- 예:
참고문헌
- 웹 문서
- 도서
- 알고리즘 [개정4판] / 로버트 세지윅, 케빈 웨인 저/권오인 역 / 길벗 / 초판발행 2018년 12월 26일
- 트랜잭션 처리의 원리 / 필립 A. 번스타인, 에릭 뉴코머 공저 / 한창래 역 / KICC(한국정보통신) / 1판 1쇄 2011년 12월 19일
- 관계형 데이터베이스 실전 입문 / 오쿠노 미키야 저 / 성창규 역 / 위키북스 / 초판 2016년 07월 20일 / 원서 : 理論から學ぶデ-タベ-ス實踐入門 リレ-ショナルモデルによる效率的なSQL/奧野幹也
- 데이터 중심 애플리케이션 설계 / 마틴 클레프만 저/정재부, 김영준, 이도경 역 / 위키북스 / 초판발행 2018년 04월 12일
- The Art of Computer Programming 3 정렬과 검색(개정2판) [양장] / 도널드 커누스 저 / 한빛미디어 / 초판 2쇄 2013년 02월 10일
- 데이터베이스 인터널스 / 알렉스 페트로프 저/이우현 역/이태휘 감수 / 에이콘출판사 / 발행: 2021년 01월 29일 / 원제: Database Internals: A Deep Dive into How Distributed Data Systems Work
주석
-
알고리즘. 6 맥락. 850쪽. ↩
-
데이터 중심 애플리케이션 설계. 03장. 82쪽. ↩
-
ORGANIZATION AND MAINTENANCE OF LARGE ORDERED INDICES by R. Bayer and E. McCreight 1970. 115쪽(PDF 파일 9쪽). ↩
-
알고리즘. 3.3 균형 탐색 트리. 420쪽. ↩
-
알고리즘. 6 맥락. 852쪽. ↩
-
데이터 중심 애플리케이션 설계. 03장. 84쪽. ↩
-
알고리즘. 6 맥락. 853쪽. ↩
-
데이터베이스 인터널스. 2장. 70쪽. ↩
-
트랜잭션 처리의 원리. 6.9 B-Tree 잠금. 224쪽. ↩
-
관계형 데이터베이스 실전 입문. 11. 209쪽. ↩
-
트랜잭션 처리의 원리. 6.9 B-Tree 잠금. 225쪽. ↩